How to do a content audit? 10 steps to optimize your website content

Content audit is one of the tasks that SEO specialists perform on a daily basis. You are rarely faced with a situation where the site has no content and you can plan everything from the beginning, according to the art. Most often, the site already has some content that needs to be optimized. In this article, I’ll show you the A to Z process to perform an advanced audit of your existing content. At the end of the article you will also find a ready-made template to use during your own audit..
Step 1 Obtaining URLs
.
In the first step, you need to acquire all URLs that contain published content. In this case, we will be doing a content audit on the Senuto blog. URLs can be obtained in several ways.
Method #1: crawl the site made with a tool such as Screaming Frog or Sitebulb.
Method number 2: extracting addresses from an XML sitemap. In the case of the Senuto site, we have a separate sitemap that contains all of our blog posts (https://www.senuto.com/pl/post-sitemap.xml). Such a map is generated by all popular WordPress plugins. If you don’t have a sitemap that contains only blog posts, you’ll need to give the addresses some extra processing. Once you have a sitemap address, you can use Google Sheets to crawl the addresses.
Use the formula here:.
=IMPORTXML("https://www.senuto.com/pl/post-sitemap.xml", "//*[local-name() ='url']/*[local-name() ='loc']").

*After a few seconds, the URLs from the sitemap should appear in the sheet. If the formula doesn’t work, replace ”,” with ”;”.
Method #3: Downloading URLs from Senuto. You can set up a filter in the items report to show only URLs that contain a blog. This way, however, you will omit articles that are not showing any keyword phrases.
 .
.
You don’t have a Senuto account yet?.
Click >>here<< and use for free for 2 weeks!.
Before moving on to the next step, still add a numeric identifier to each URL. This identifier will allow you to combine data for URLs from multiple sources.

We have reached the point where we have already collected all the URLs of the blog articles. We can move on to the next step.
Step 2 Basic URL information
.
In this step, we want to collect basic URL information that we will need at a later stage. This includes:
- Title tags .- Headers .- Publication dates .- Canonical links .- Meta robots tags .- Distance from home page .- Content length .- Number of internal links .- Number of external links .- Other elements .
The only way to determine all this data is to do a crawl of the site (using Screaming Frog, for example). However, if you skip the links in all of this, you can limit yourself to just working in Google Sheets. Below you’ll find the formulas that will get this data into Google Sheets.
-
Title tag:
=IMPORTXML(B2,"//title").
- B2 contains the URL. By dragging the formula down, we will apply it to all URLs.

*For a list with more than 200 URLs, this method will not work.
-
H1 tag:
=IMPORTXML(A2,"//h1").
- There is a URL in A2. The formula will retrieve all matched elements (all H1 headers). If we want to retrieve only the first H1 header, we should use the formula
=IMPORTXML(A2,"(//h1)[1]").
-
H2 tags:
=IMPORTXML(A2,"//h2").
-
Canonical link:.
=IMPORTXML(A2,"//link[@rel='canonical']/@href").
-
Meta robots tag:.
=IMPORTXML(A2,"//meta[@name='robots']/@content").
In many cases, we may find it useful to audit additional elements from the page, such as the author of the text, its publication date, number of comments, category, tags etc. In this case, we can also use Google Sheets. In the Import XML formula, we can specify the xPath from which the sheet should retrieve the data. Below you can see this in the example of the Senuto blog.
We can perform such extraction for any element from the page. In tools such as Screaming Frog this is also possible and works in the same way. When configuring the crawl in the configuration >> custom >> extraction menu, we can specify the data we want to extract.
If you have extracted content publication dates for your audit, then in a separate column use the formula =TODAY(), which will insert today’s date value into the row. Then subtract that date from the article’s publication date.
 .
.
This particular text is exactly 2 days old. We will then use this to examine the relationship between text visibility and publication date.
All the data I’ve described here can be found in the Google Docs template at the end of the article. I used the Screaming Frog tool and Google Sheets formulas to collect them.
At the end of the article you will also find a ready-made template to use during your own audit..
Tip: at Senuto we are currently working on a tool that will allow you to do such operations on your URL list. It should be available in early 2021.
Step 3 URL visibility data
.
In this step, we collect URL visibility data. In two dimensions:
- Statistics - information on how many key phrases in TOP3/TOP10 our URLs are visible .- Phrases - information, on which phrases individual addresses are visible .
Here we will use the URL analysis tool in Senuto, which was created for this purpose.
In the first step, I retrieve statistics for the list of URLs.
 .
.
I import the data into the underlying Google Sheets file and use SEARCH.VERTICAL to match the data. We have arrived at 3 columns:
- TOP 3 - the number of key phrases that the URL has in the TOP 3 .- TOP 10 - the number of key phrases that the URL has in the TOP 10 .- Visibility - estimated monthly number of visits for an article with SEO .
In the second step, I’ll use the same tool again, but instead of statistics, I’ll retrieve all the phrases for which URLs are visible from the list. I put the phrases in a separate tab.
Step 4. Data on phrases on which URLs are visible
.
In the next step, we will add information about the phrases on which our articles are visible to our file**.**
Again, we’ll use the same tool in Senuto here - URL Analysis (instead of statistics mode, choose keyword phrases mode).
The phrases I downloaded from the tool are in the “phrases” tab of the file.
Step 5. Link data from ahrefs
.
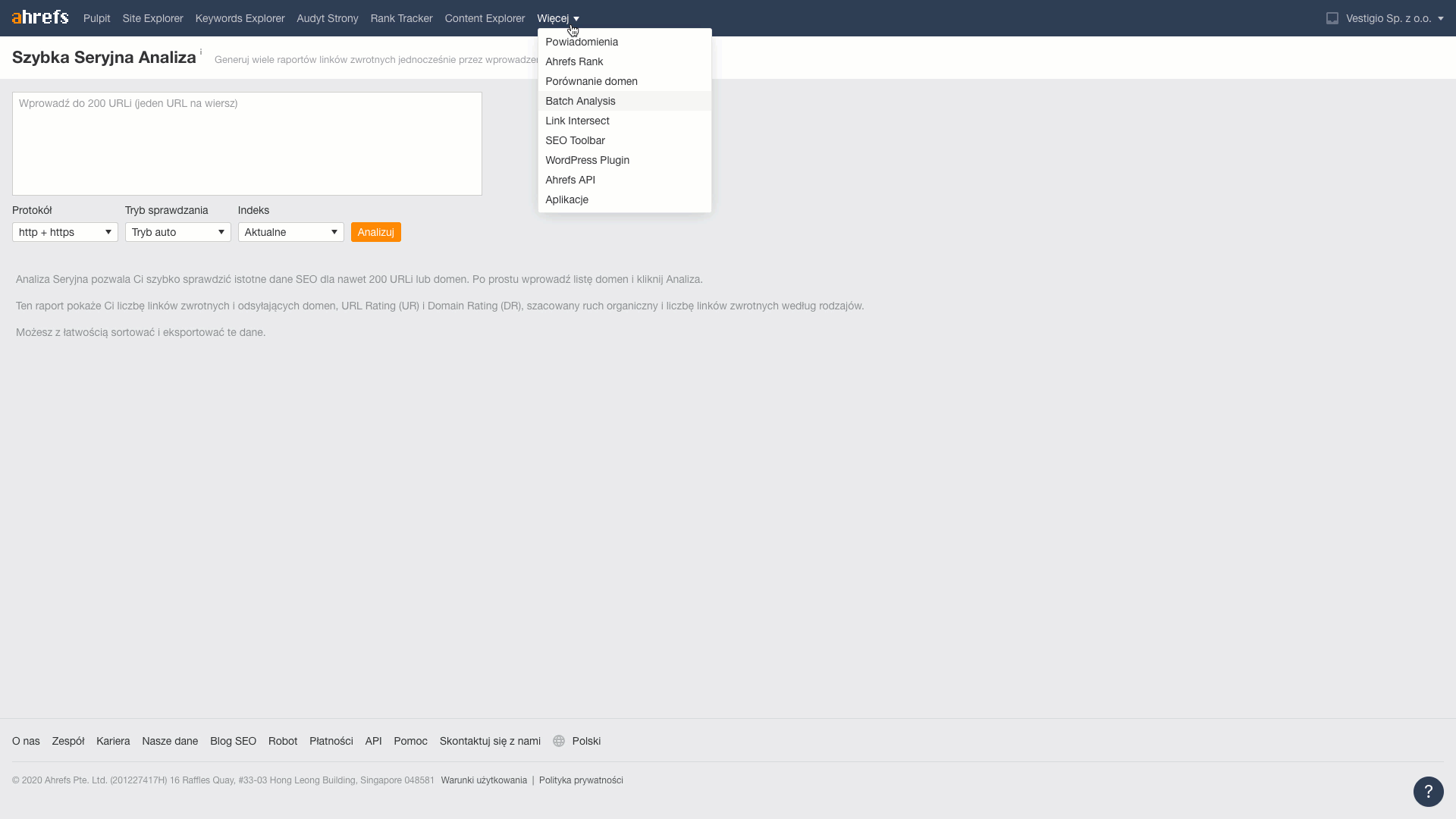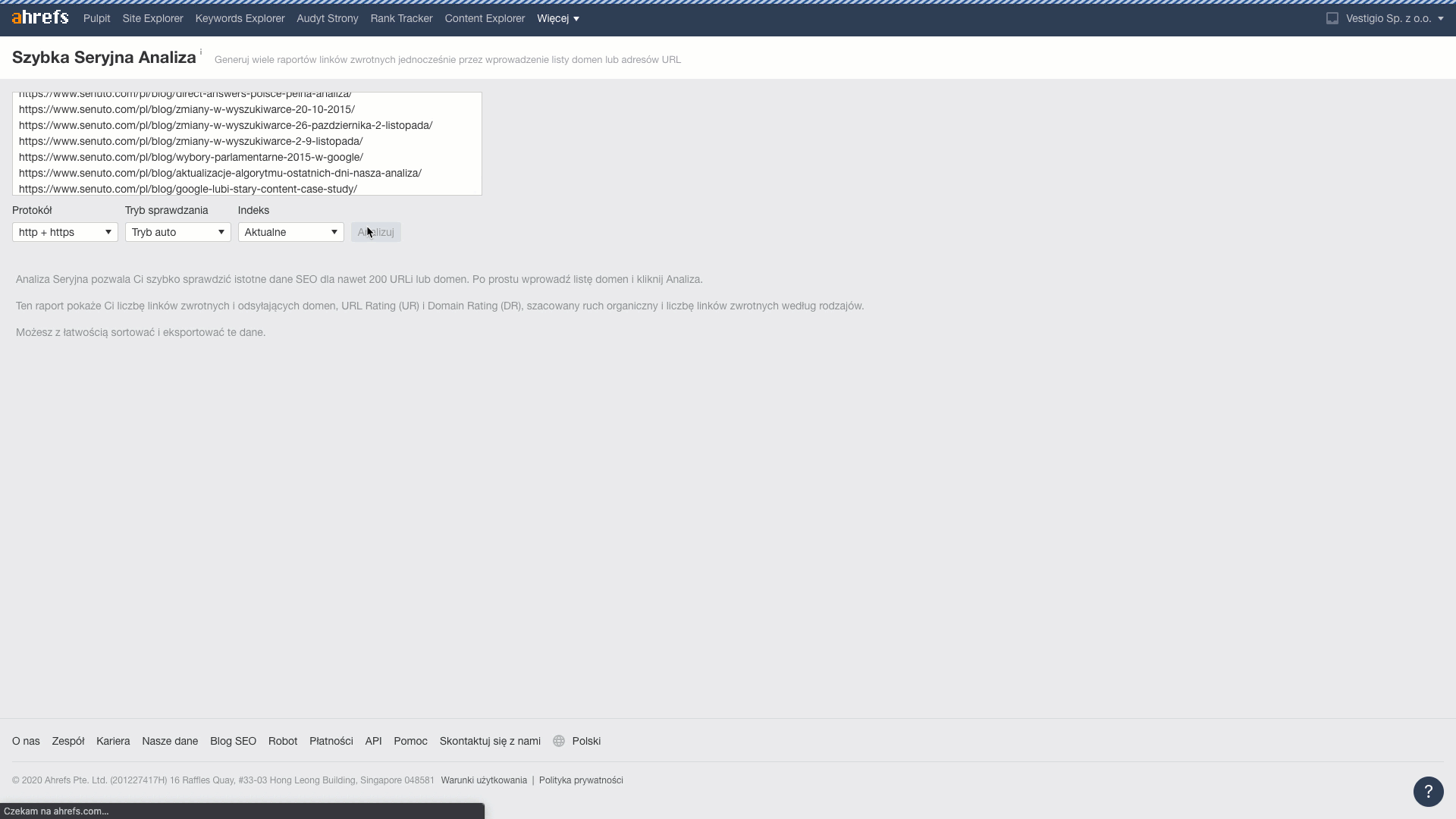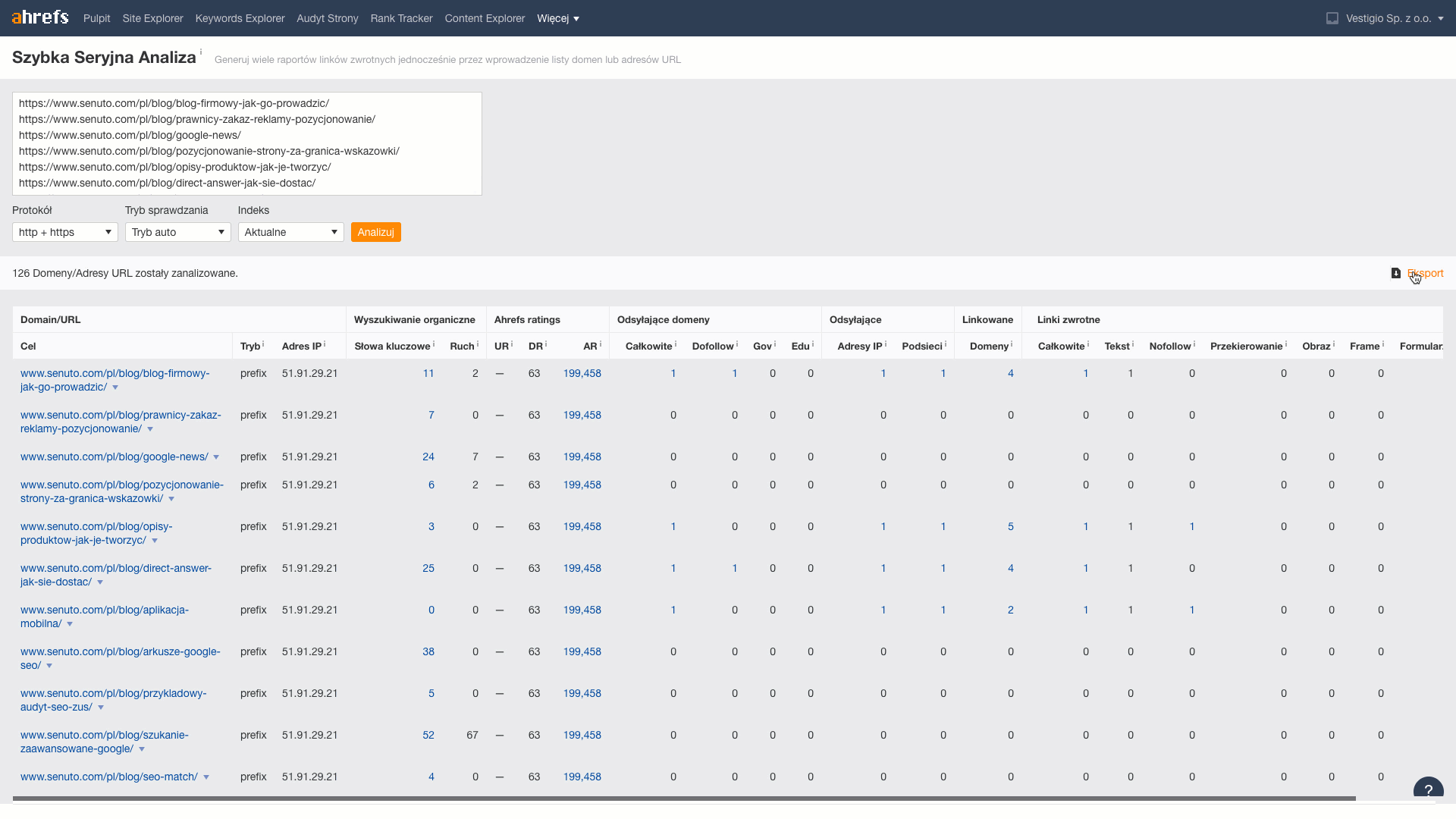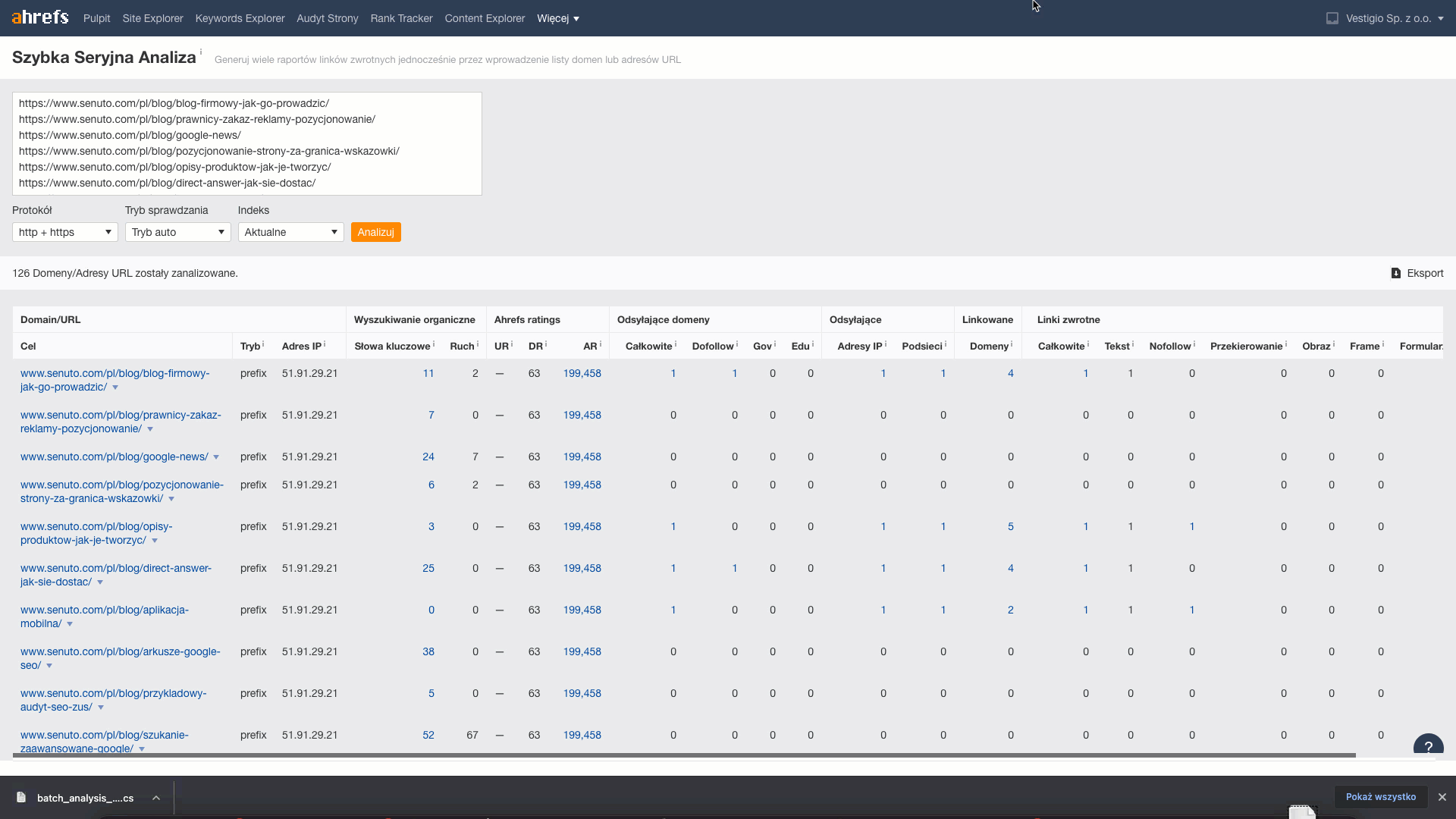
In this step, for each URL we retrieveinformation about the number of links and domains that lead to it. To do this, we will use the Batch Analysis tool included in Ahrefs.
From the downloaded data, I transfer the metrics Reffering domains (information from how many domains links to the article), Total backlinks (number of links leading to the article) to the sheet.
Step 6 Keyword Gap
.
In this step, we want to determine for each article the keyword phrases for which it should be visible and is not yet. Such an analysis is commonly called a keyword gap analysis.
For this, we will need information about the main phrase of the article - this is the keyword for which the article should be visible (column Main Keyword in the sheet). In this case I did it manually, butyou can also use H1 headings, tags or other elements that generally contain this phrase. Not every blog article is written with SEO in mind, so not everyone in our sheet has a main phrase. I added an additional column “SEO text?” to know which text was written with SEO intent and which was not.
The process to retrieve this data is as follows:.
- Step 1 - I retrieve the TOP 20 results from the SERP for each phrase marked as main keyword. .2. Step 2 - I retrieve all phrases that show URLs that are in the TOP 20 for the previously selected phrases. .3. Step 3 - I check the position of my domain on these phrases. .4. Step 4 - I link the data using an identifier so that I know which phrases are attributed to which article.
In this way, 9482 keyword phrases appeared in the “keyword gap” tab. Based on this information, I am now able to calculate the limiting potential of each article (the maximum average monthly number of searches for an article) and the number of phrases for which it should be visible.
To do this, we create a pivot table (“Keyword GAP - Statistics” tab). In this tab, for each ID, we determined the number of phrases assigned to the article and the potential determined as the sum of searches for all phrases. I then pull this information (column AI and AJ) into the “Data” tab and add column AK, which counts the maximum traffic potential for the article, and column AL, which counts what potential the article has already used.
If I now sort by the AL column, I can rank the articles in order of highest remaining potential to be used. I can also do a double sort by the AK column and the AL column to designate articles with high potential where the used potential is low. On the other hand, using the ID in the “Keyword gap” tab, I can designate the phrases that are missing from an article.
Tip: We are currently working in Senuto on a tool that will allow you to retrieve the TOP 20 results for any phrase. Such an addition will also appear in our Google Sheets integration. In the meantime, you can do this using the SERP History tool or the Senuto API.
Step 7 Competitor Analysis
.
In our analysis, we also need to look at the competition. In the earlier step, I downloaded the TOP 20 results from the SERP for each phrase from the audit. This data can be found in the “TOP 20” tab. For each URL, I also downloaded the length of its content.
This information will allow us to determine whether the length of our content relative to the competition is too short. From this tab, I created 2 pivot tables in the “Content length” tab - the first table measures the average length of content in the TOP 20, while the second measures the average length of content in the TOP 3. I also moved this data to the “Data” tab to the Y-AC columns where I also determined, based on the average length of content from the TOP 3, whether the text is too short.
Keep in mind that content length in most cases does not matter much for ranking. We’ll check this later in this analysis.
Tip: We are currently working on a tool at Senuto that will allow you to retrieve the TOP 20 results for any phrase. Such an addition will also appear in our Google Sheets integration. In the meantime, you can do this with the SERP Analysis tool.
Step 8 Relationships
.
The next step in the analysis is to examine the relationships between different features.This will help us find out, which data in the audit should have the highest priority. Here we examine the linear correlation of two variables. Correlation operates in the range -1 (no correlation) to 1 (strong correlation). In the range of >0.3, we can already talk about the correlation of two variables.
You can find the correlation in the “Dashboard” tab in column B-C in row 92-98. We use the function =CORREL to determine the correlation.
As you can see, in this case there are no strong correlations between any metrics, which is due to the small amount of data - the sample is only a little over 80 articles. You can only see a correlation between the number of phrases in the TOP 10 and the length of the article - this seems natural, since the longer the article, the more long tail phrases it catches. However, this does not translate into visibility.
Step 9 Traffic data from Google Search Console
.
For each URL, it’s also a good idea to retrieve information about how many clicks from search results it has had recently (in our case, it’s 6 months). I created a separate tab “Data GSC” where I downloaded this information.
I used the Google Sheets plugin Search Analytics for Sheets - it retrieves data for all URLs. Using the SEARCH.VERTICAL function, I moved this information to the “Data” tab.
Step 10 Duplicates
.
During the creation of the audit, I noticed that in three cases the main keyword for the articles is the same, which means that three articles have a duplicate.
I moved the data using the query function to the “Duplicates” tab. In this tab, I created column J and inserted the value “1” in the first row. In the next row, I inserted the formula:
=if(C3=C2, J2, J2+1).
- this formula checks whether the value of row C3 is equal to the value of row C2 (whether the main keyword is the same). If the values are identical, it takes the value of row J2 (ID); if not, it adds 1 to it. This way, rows that have the same main keyword will have the same ID and it will be easy to catch them. I can now make a pivot table by the ID value and the number of occurrences of it and decide what to do with that content.
Data presentation
.
Data presentation is also an important part of any audit. Therefore, the audit included a “Dashboard” tab, where I gathered all the most important information. I mainly used the query function here.
Functions of Google Sheets we used
.
In order to efficiently create audits like this example, you need to know how to navigate the spreadsheet environment (they all work similarly). Make sure you can use the following functions:
- SEARCH.VERTICAL: https://support.google.com/docs/answer/3093318?hl=pl
- Pivot tables: https://support.google.com/docs/answer/1272900?co=GENIE.Platform%3DDesktop&hl=en
- Query: https://support.google.com/docs/answer/3093343?hl=pl
- Import XML: https://support.google.com/docs/answer/3093342?hl=pl
- Conditional formatting: https://support.google.com/docs/answer/78413?co=GENIE.Platform%3DDesktop&hl=en
What’s next?
.
This is not the end of the work.The data we have collected here needs to be turned into conclusions. What I’ve been able to see are:
- Some content on the Senuto blog is duplicated (they are about the same thing). .- We have used only 1% of the total potential that the articles have.
- There is a lot of duplication.- In many places, articles need to be supplemented with additional keyword phrases (this I know from keyword gap analysis). .- A large number of articles have less than 10 internal links - we will have to work on this. .
If such an audit were to land with a client, we would need an additional .pdf file with a description of each piece of information, or a list of tasks to be completed. We could pull other information into our file, such as competitors’ headings, their title tags, etc. However, we will stop there. My goal was to present a workflow that can be used. At Senuto, we are working on such tools that will support this workflow so that you can create content audits as soon as possible.

Damian Sałkowski
CEO Senuto. Specjalista SEO z bagażem doświadczeń z rynku polskiego i rynków zagranicznych. Autor dwóch książek o marketingu internetowym i kilkuset artykułów w tej tematyce. Prywatnie fan piłki nożnej i sportów motorowych.
All articles →