 Damian Sałkowski
Damian Sałkowski A tartalmi audit az egyik olyan feladat, amelyet a SEO-szakértők napi szinten végeznek. Ritkán kerülsz olyan helyzetbe, hogy az oldalnak nincs tartalma, és mindent a kezdetektől fogva megtervezhetsz a művészetnek megfelelően. Leggyakrabban az oldalnak már van valamilyen tartalma, amelyet optimalizálni kell. Ebben a cikkben megmutatom az A-tól Z-ig tartó folyamatot, amellyel elvégezheted a meglévő tartalmak haladó auditálását. A cikk végén egy kész sablont is találsz, amelyet a saját auditálásod során használhatsz..
Legfontosabb megállapítások
- A tartalmi audit elengedhetetlen része a SEO stratégiának, segít azonosítani a weboldal tartalmi hiányosságait és optimalizálási lehetőségeit.
- Az URL-címek beszerzése kulcsfontosságú első lépés, amely több módszerrel is elvégezhető, például a Senuto Visibility Analysis eszközével.
- Alapvető URL-információk gyűjtésekor olyan elemeket vizsgálunk, mint a title tag-ek, fejlécek, megjelenési dátumok és belső, külső hivatkozások száma.
- A Senuto URL-elemzés eszköze segítségével meghatározható, hogy az URL-ek hány kulcsszóval szerepelnek a TOP3/TOP10-ben, ami segít a láthatóság javításában.
- A tartalmi audit során összegyűjtött adatok elemzése és a megfelelő akciók meghatározása növeli a weboldal SEO teljesítményét és a tartalom hatékonyságát.
1. lépés Az URL-címek beszerzése
.
Az első lépésben be kell szereznie az összes URL-t, amely közzétett tartalmat tartalmaz. Ebben az esetben a Senuto blogon fogunk tartalmi ellenőrzést végezni. Az URL-címeket többféleképpen is megkaphatjuk.
Módszer #1: Crawlozza fel a webhelyet egy olyan eszközzel, mint a Screaming Frog vagy a Sitebulb.
2. módszer: címek kinyerése egy XML sitemapből. A Senuto webhely esetében van egy külön oldaltérképünk, amely tartalmazza az összes blogbejegyzésünket (https://www.senuto.com/pl/post-sitemap.xml). Egy ilyen térképet minden népszerű WordPress bővítmény generál. Ha nincs olyan oldaltérképed, amely csak blogbejegyzéseket tartalmaz, akkor a címeknek némi extra feldolgozást kell adnod. Ha már van szittérkép-címe, akkor a Google Sheets segítségével feltérképezheti a címeket.
Az itt található képletet használja:.
=IMPORTXML("https://www.senuto.com/pl/post-sitemap.xml", "//*[local-name() ='url']/*[local-name() ='loc']")
.

*Pár másodperc múlva a lapon meg kell jelenniük az URL-eknek a sitemapből. Ha a képlet nem működik, cserélje ki a „,” helyett a „;” szót.
Módszer #3: URL-ek letöltése a Senutóból. Beállíthat egy szűrőt az elemek jelentésében, hogy csak a blogot tartalmazó URL-eket jelenítse meg. Így azonban kihagyja azokat a cikkeket, amelyek nem mutatnak kulcsszavas kifejezéseket.
 .
.
Nincs még Senuto fiókod?.
Kattints >>itt<< és használd ingyen 2 hétig!.
Mielőtt továbblépne a következő lépésre, még mindig adjon egy numerikus azonosítót minden URL-hez. Ez az azonosító lehetővé teszi a több forrásból származó URL-ek adatainak kombinálását.

Elérkeztünk ahhoz a ponthoz, ahol már összegyűjtöttük a blogcikkek összes URL-jét. Továbbléphetünk a következő lépésre.
Próbáld ki a Senuto Suite-ot 14 napig ingyen
Próbáld ki a Senuto Suite-ot 14 napig ingyen2. lépés Alapvető URL információk
.
Ebben a lépésben alapvető URL-információkat szeretnénk összegyűjteni, amelyekre a későbbiekben szükségünk lesz. Ezek közé tartozik többek között:
- Title tagek
- Főcímek
- Megjelenési dátumok
- Kanonikus hivatkozások
- Meta robotok címkék
- Távolság a kezdőlaptól
- A tartalom hossza
- A belső hivatkozások száma
- A külső linkek száma
- Egyéb elemek
.
.
.
.
.
.
.
.
.
.
Mindezen adatok meghatározásának egyetlen módja az, ha az oldal feltérképezését végezzük (például a Screaming Frog segítségével). Ha azonban mindezek közül kihagyja a hivatkozásokat, akkor korlátozhatja magát arra, hogy csak a Google Sheets-ben dolgozik. Az alábbiakban megtalálja azokat a képleteket, amelyekkel ezeket az adatokat a Google Sheets-be juttatja.
- Title tag:
=IMPORTXML(B2,"//title")
.
– A B2 tartalmazza az URL címet. A képletet lefelé húzva az összes URL-re alkalmazzuk.

*A 200-nál több URL-t tartalmazó lista esetén ez a módszer nem fog működni.
- H1 tag:
=IMPORTXML(A2,"//h1")
.
– Az A2-ben egy URL található. A képlet az összes egyező elemet (az összes H1 fejlécet) lekérdezi. Ha csak az első H1 fejlécet szeretnénk lekérdezni, akkor a következő képletet kell használnunk=IMPORTXML(A2,"(//h1)[1]")
.
- H2 címkék:
=IMPORTXML(A2,"//h2")
.
- Kanonikus link:.
=IMPORTXML(A2,"//link[@rel='kanonikus']/@href")
.
- Meta robots tag:.
=IMPORTXML(A2,"//meta[@name='robots']/@content")
.
Sok esetben hasznosnak találhatjuk az oldal további elemeinek ellenőrzését, mint például a szöveg szerzője, a megjelenés dátuma, a hozzászólások száma, a kategória, tagok stb. stb. Ebben az esetben használhatjuk a Google Sheets-et is. Az XML importálása képletben megadhatjuk az xPath-ot, ahonnan a lapnak le kell kérnie az adatokat. Az alábbiakban ezt láthatjuk a Senuto blog példájában.
Az oldal bármely elemére végezhetünk ilyen kivonást. Az olyan eszközökben, mint a Screaming Frog, ez szintén lehetséges és ugyanígy működik. A kúszás konfigurálásakor a konfiguráció >> egyéni >>> extrakció menüpontban megadhatjuk, hogy milyen adatokat szeretnénk kinyerni.
Ha a tartalom közzétételének dátumát extrahálta az ellenőrzéshez, akkor egy külön oszlopban használja a =TODAY() képletet, amely a mai dátum értékét illeszti be a sorba. Ezután vonjuk ki ezt a dátumot a cikk megjelenési dátumából.
 .
.
Ez a bizonyos szöveg pontosan 2 napos. Ezután ezt felhasználva megvizsgáljuk a szöveg láthatósága és a megjelenési dátum közötti kapcsolatot.
Az összes adat, amit itt leírtam megtalálható a cikk végén található Google Docs sablonban. Összegyűjtésükhöz a Screaming Frog eszközt és a Google Sheets képleteit használtam.
A cikk végén egy kész sablont is találsz, amelyet a saját auditálásod során használhatsz..
Tipp: A Senutónál jelenleg egy olyan eszközön dolgozunk, amellyel ilyen műveleteket végezhetsz az URL-listádon. Ez várhatóan 2021 elején lesz elérhető.
3. lépés URL láthatósági adatok
.
Ebben a lépésben URL láthatósági adatokat gyűjtünk. Két dimenzióban:
- Statisztika – információ arról, hogy hány kulcskifejezéssel a TOP3/TOP10-ben láthatóak az URL-jeink
- Kifejezések – információ, mely kifejezésekkel az egyes címek láthatóak
.
.
Itt a Senuto erre a célra létrehozott URL-elemzés eszközét fogjuk használni.
Az első lépésben az URL-ek listájának statisztikáit hívom le.
 .
.
Az adatokat importálom az alapul szolgáló Google Sheets fájlba, és a SEARCH.VERTICAL használatával egyeztetem az adatokat. Megérkeztünk a 3 oszlophoz:
- TOP 3 – azon kulcskifejezések száma, amelyeket az URL a TOP 3-ban találunk
- TOP 10 – azon kulcskifejezések száma, amelyekkel az URL a TOP 10-ben szerepel
- Láthatóság – a SEO
.
.
cikk látogatásainak becsült havi száma.
A második lépésben ismét ugyanazt az eszközt fogom használni, de a statisztikák helyett az összes olyan kifejezést fogom lekérdezni a listából, amelyek URL-jei láthatóak. A kifejezéseket egy külön fülre teszem.
Step 4. Adatok azokról a kifejezésekről, amelyeken az URL-címek láthatóak
.
A következő lépésben a fájlunkhoz hozzáadjuk az adatokat azokról a kifejezésekről, amelyeken a cikkeink láthatóak.
Itt is ugyanazt az eszközt fogjuk használni a Senutóban – URL elemzés (a statisztika mód helyett válasszuk a kulcsszavas kifejezések módot).
Az eszközből letöltött kifejezések a fájl „kifejezések” fülén találhatók.
5. lépés. Linkadatok ahrefsből
.
Ebben a lépésben minden egyes URL-hez lekérdezzükaz oda vezető linkek és domainek számáról szóló információkat. Ehhez a Ahrefs-ban található Batch Analysis eszközt fogjuk használni.
A letöltött adatokból a metrikákat Reffering domains (információ arról, hogy hány domain linkel a cikkre), Total backlinks (a cikkre vezető linkek száma) átviszem a lapra.
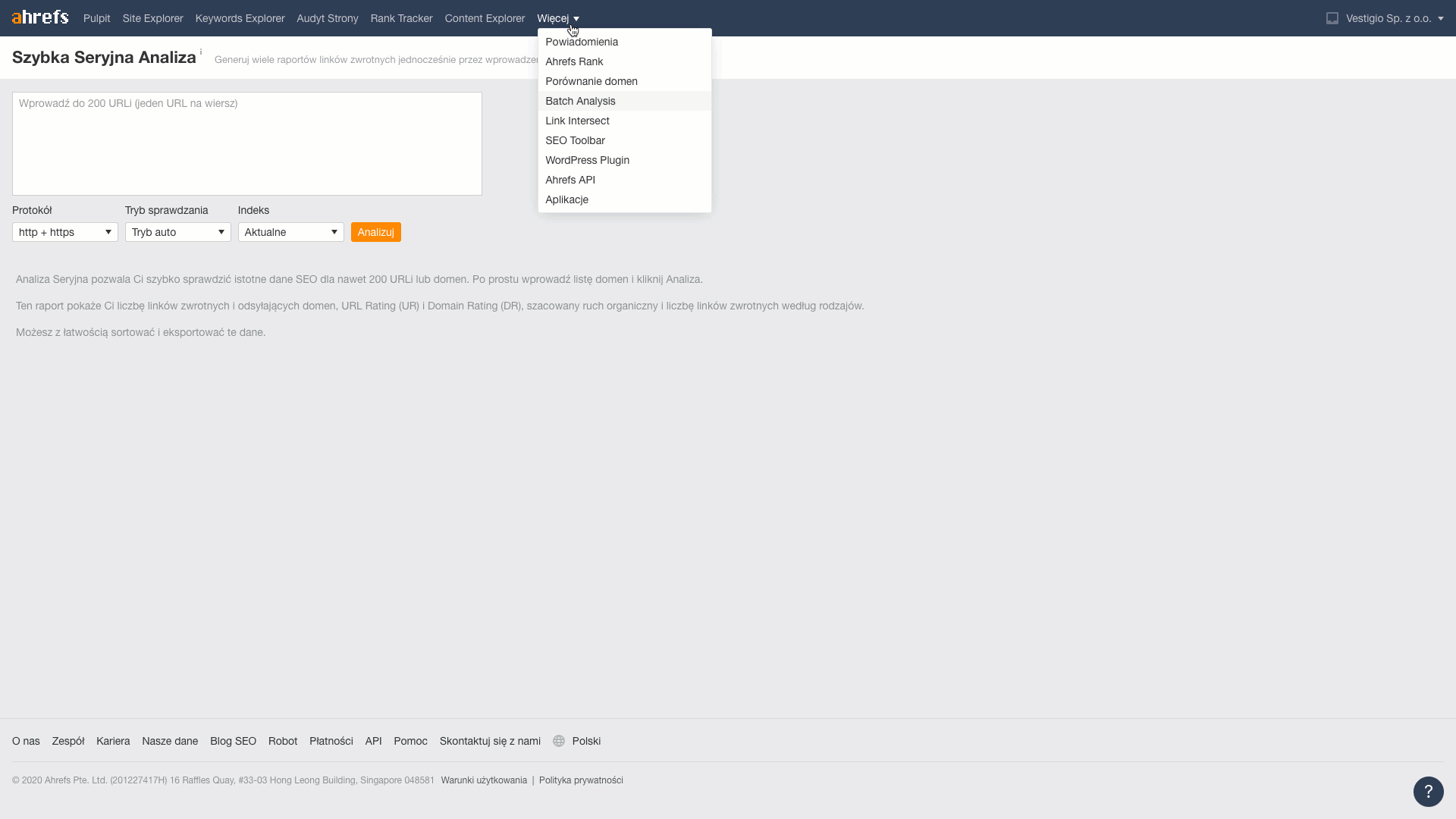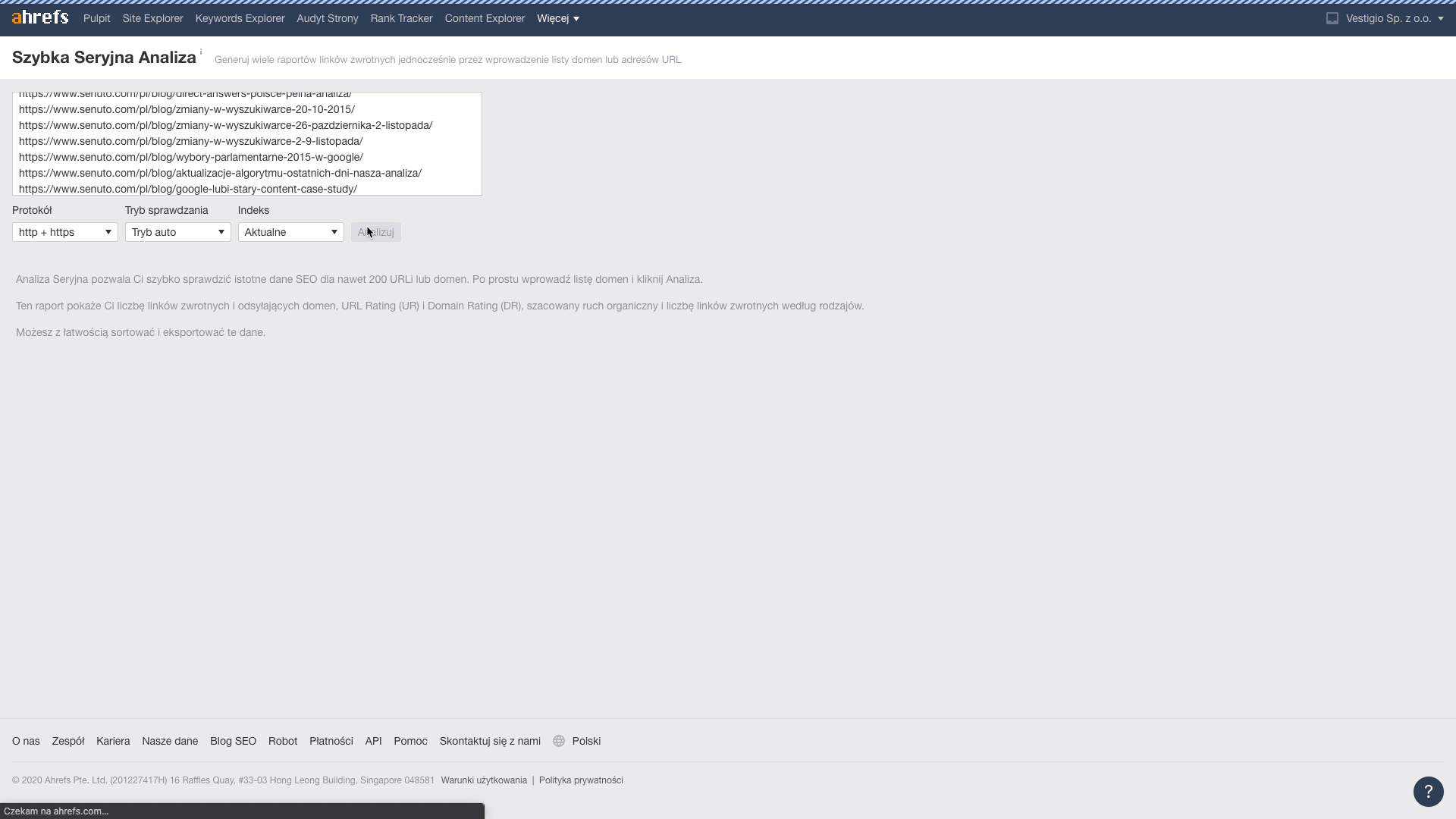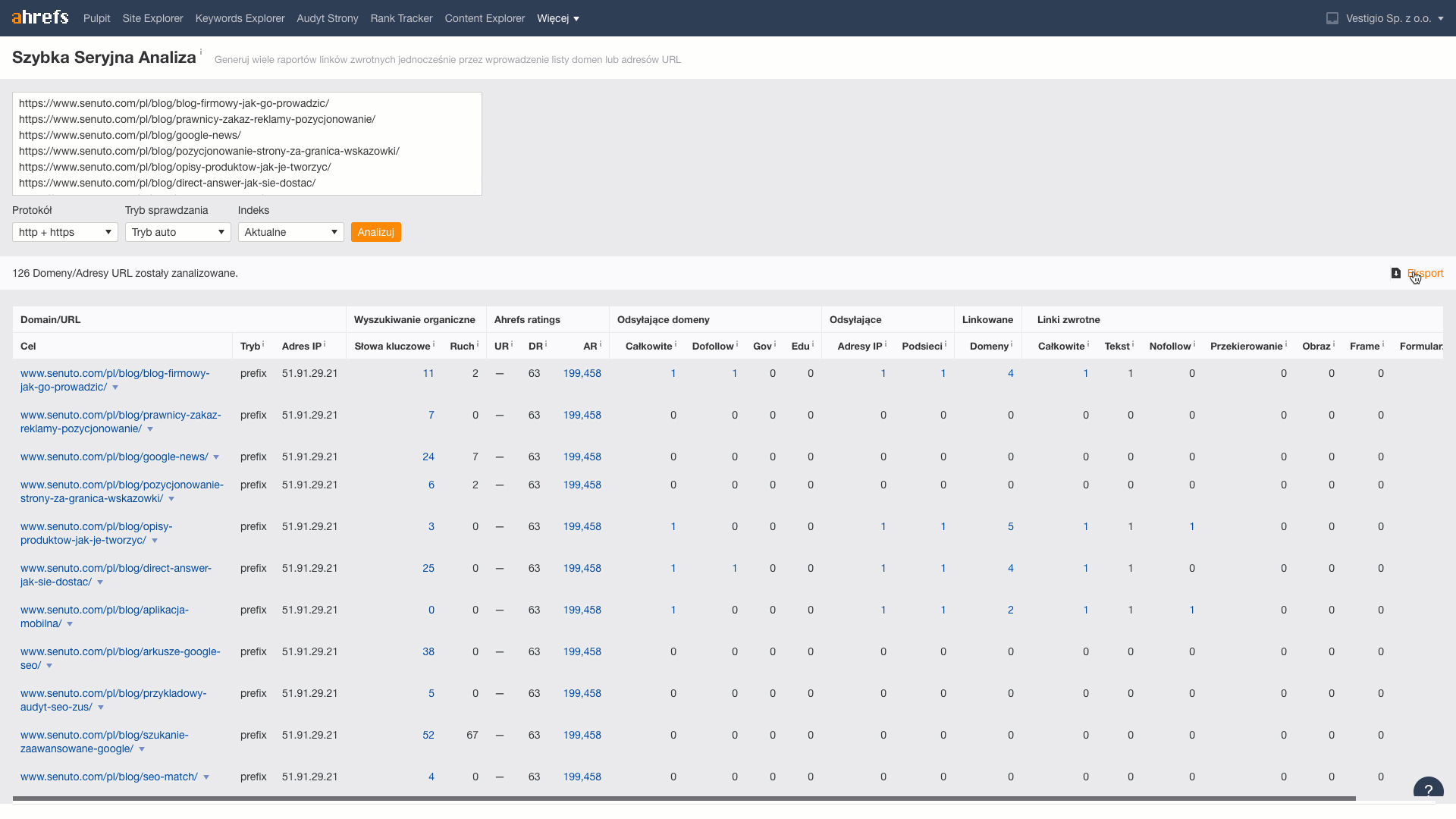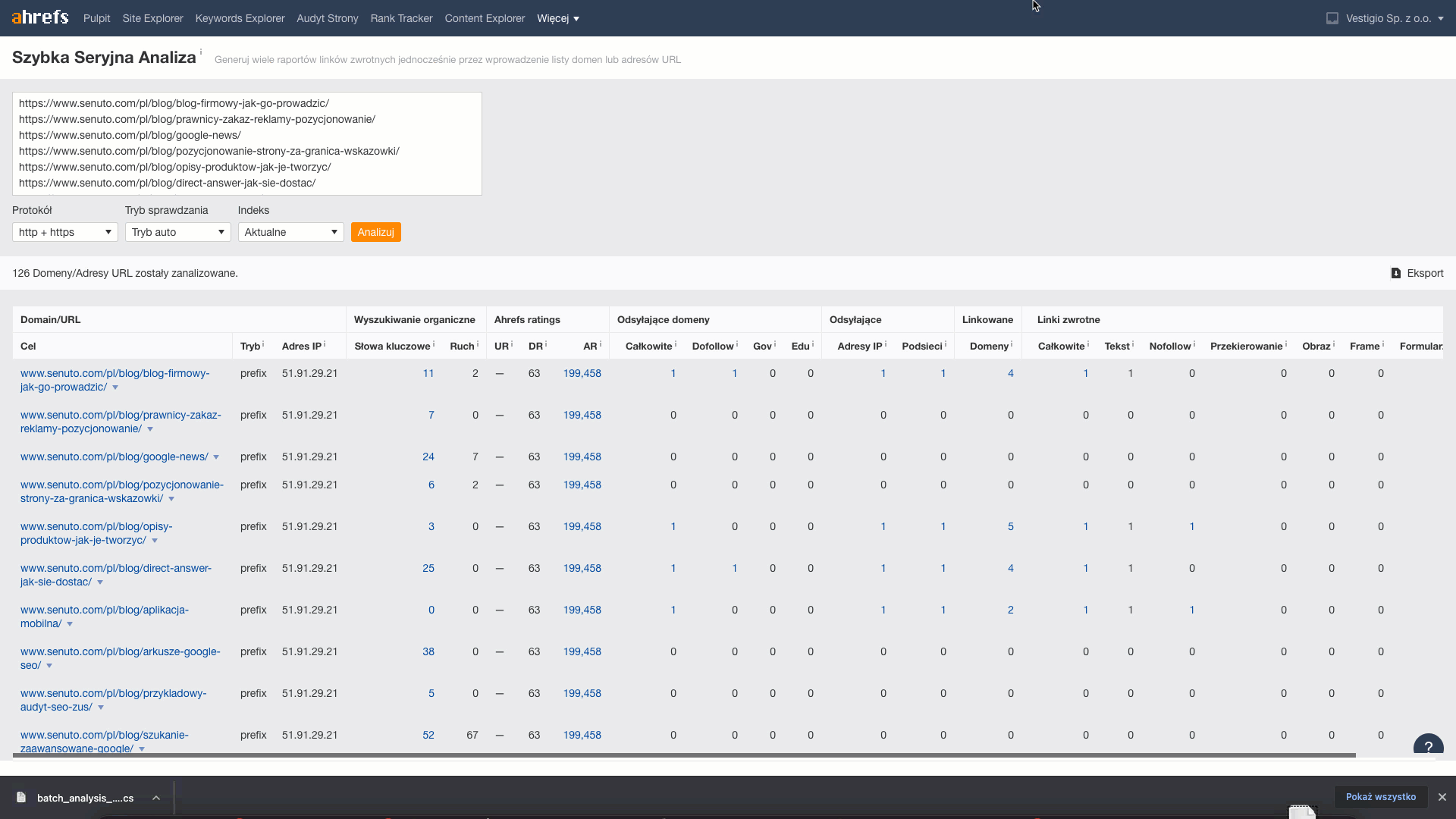
Step 6 Keyword Gap
.
Ebben a lépésben szeretnénk meghatározni minden egyes cikkhez azokat a kulcsszavas kifejezéseket, amelyek esetében láthatónak kellene lennie, de még nem az. Az ilyen elemzést általában kulcsszóhézag-elemzésnek nevezik.
Ehhez szükségünk lesz a cikk fő kulcsszavára vonatkozó információkra – ez az a kulcsszó, amelyre a cikknek láthatónak kellene lennie (a lap Fő kulcsszó oszlopa). Ebben az esetben ezt kézzel végeztem, dea H1 címszavak, címkék vagy más olyan elemek is használhatók, amelyek általában tartalmazzák ezt a kifejezést. Nem minden blogcikket írunk SEO-szemlélettel, így nem minden lapunkban szerepel a főmondat. Hozzáadtam egy további oszlopot „SEO szöveg?”, hogy tudjuk, melyik szöveg íródott SEO-szándékkal és melyik nem.
Az adatok kinyerésének folyamata a következő:.
- 1. lépés – Minden fő kulcsszóként megjelölt kifejezéshez lekérdezem a TOP 20 találatot a SERP-ről.
- 2. lépés – Lekeresem az összes olyan kifejezést, amely olyan URL-címeket mutat, amelyek a TOP 20-ban vannak az előzőleg kijelölt kifejezésekhez.
- 3. lépés – Ellenőrzöm a domain pozícióját ezeken a kifejezéseken.
- 4. lépés – Egy azonosító segítségével összekapcsolom az adatokat, így tudom, hogy melyik kifejezés melyik cikkhez tartozik.
.
.
.
Ily módon 9482 kulcsszavas kifejezés jelent meg a „kulcsszavas rés” lapon. Ezek az információk alapján most már ki tudom számítani az egyes cikkek korlátozó potenciálját (a cikkre vonatkozó keresések maximális havi átlagos száma) és azon kifejezések számát, amelyekre a cikknek láthatónak kell lennie.
Ehhez hozzunk létre egy pivot táblázatot („Keyword GAP – Statistics” fül). Ezen a lapon minden egyes azonosítóhoz meghatároztuk a cikkhez rendelt kifejezések számát és az összes kifejezésre vonatkozó keresések összegeként meghatározott potenciált. Ezt az információt (AI és AJ oszlop) áthúzom az „Adatok” fülre, majd hozzáadom az AK oszlopot, amely a cikk maximális forgalmi potenciálját számolja, és az AL oszlopot, amely azt a potenciált számolja, amelyet a cikk már felhasznált.
Ha most az AL oszlop szerint rendezem, akkor a cikkeket a legnagyobb még felhasználható potenciál szerinti sorrendbe tudom helyezni. Kettős rendezést is végezhetek az AK oszlop és az AL oszlop alapján, hogy kijelöljem a nagy potenciállal rendelkező cikkeket, ahol a felhasznált potenciál alacsony. Másrészt a „Kulcsszóhiány” fülön található azonosító segítségével kijelölhetem azokat a kifejezéseket, amelyek hiányoznak egy cikkből.
Tipp: A Senutóban jelenleg egy olyan eszközön dolgozunk, amely lehetővé teszi, hogy bármely kifejezésre vonatkozóan lekérje a TOP 20 találatot. Egy ilyen kiegészítés a Google Sheets integrációnkban is meg fog jelenni. Addig is megteheti ezt a SERP History eszköz vagy a Senuto API segítségével.
7. lépés versenytárselemzés
.
Elemzésünk során a versenytársakat is meg kell vizsgálnunk. Az előző lépésben az auditból letöltöttem a SERP minden egyes kifejezésre vonatkozó TOP 20 találatot. Ezek az adatok a „TOP 20” fülön találhatók. Minden URL-hez letöltöttem a tartalom hosszát is.
Ezzel az információval meghatározhatjuk, hogy a tartalmunk hossza a versenytársakhoz képest túl rövid-e. Ebből a fülből 2 pivot táblázatot hoztam létre a „Tartalom hossza” fülön – az első táblázat a TOP 20-ban található tartalom átlagos hosszát méri, míg a második a TOP 3-ban található tartalom átlagos hosszát. Ezeket az adatokat is átvittem az „Adatok” fülre az Y-AC oszlopokba, ahol szintén a TOP 3-ban található tartalom átlagos hossza alapján határoztam meg, hogy túl rövid-e a szöveg.
Ne feledje, hogy a tartalom hossza a legtöbb esetben nem sokat számít a rangsorolás szempontjából. Ezt később az elemzés során ellenőrizzük.
Tipp: A Senutónál jelenleg egy olyan eszközön dolgozunk, amely lehetővé teszi, hogy bármely kifejezésre vonatkozóan lekérje a TOP 20 találatot. Egy ilyen kiegészítés a Google Sheets integrációnkban is meg fog jelenni. Addig is megteheti ezt a SERP elemzés eszközzel.
8. lépés kapcsolatai
.
Az elemzés következő lépése a különböző jellemzők közötti összefüggések vizsgálata. Ez segít kideríteni, melyik adatnak kell a legnagyobb prioritást élveznie az ellenőrzésben. Itt két változó lineáris korrelációját vizsgáljuk. A korreláció a -1 (nincs korreláció) és 1 (erős korreláció) közötti tartományban működik. A >0,3 tartományban már két változó korrelációjáról beszélhetünk.
A korrelációt a „Dashboard” fülön a B-C oszlopban a 92-98. sorban találja. A korreláció meghatározásához a =CORREL függvényt használjuk.
Mint látható, ebben az esetben egyik mérőszám között sincs erős korreláció, ami a kis adatmennyiségnek köszönhető – a minta csak valamivel több mint 80 cikket tartalmaz. Egyedül a TOP 10-ben szereplő kifejezések száma és a cikk hossza között láthatunk összefüggést – ez természetesnek tűnik, hiszen minél hosszabb egy cikk, annál több hosszú szárnyú kifejezést fog meg. Ez azonban nem jelent láthatóságot.
Step 9 Traffic data from Google Search Console
.
Minden egyes URL-címhez érdemes lekérdezni azt az információt is, hogy mennyi kattintás érkezett rá a keresési találatokból az utóbbi időben (esetünkben 6 hónapról van szó). Létrehoztam egy külön „Adatok GSC” lapot, ahonnan letöltöttem ezeket az információkat.
A Google Sheets bővítményt Search Analytics for Sheets – ez az összes URL-hez lekérdezi az adatokat. A SEARCH.VERTICAL funkció segítségével áthelyeztem ezt az információt az „Adatok” fülre.
10. lépés duplikátumok
.
Az audit készítése során észrevettem, hogy három esetben a cikkek fő kulcsszava megegyezik, ami azt jelenti, hogy három cikk duplikátummal rendelkezik.
Az adatokat a lekérdezés funkció segítségével áthelyeztem a „Duplikátumok” fülre. Ezen a lapon létrehoztam a J oszlopot, és az első sorba beillesztettem az „1” értéket. A következő sorba beillesztettem a képletet:
=if(C3=C2, J2, J2+1)
.
– ez a képlet azt ellenőrzi, hogy a C3 sor értéke megegyezik-e a C2 sor értékével (hogy a fő kulcsszó megegyezik-e). Ha az értékek megegyeznek, akkor a J2 sor értékét veszi (azonosító); ha nem, akkor hozzáad 1-et. Így az azonos fő kulcsszóval rendelkező sorok azonos ID-vel rendelkeznek, és könnyen elkaphatók lesznek. Most már készíthetek egy pivot táblát az ID értéke és az előfordulások száma alapján, és eldönthetem, hogy mit csináljak ezzel a tartalommal.
Adatok bemutatása
.
Az adatok bemutatása szintén fontos része minden ellenőrzésnek. Ezért az audit tartalmazott egy „Dashboard” fület, ahol összegyűjtöttem a legfontosabb információkat. Itt elsősorban a lekérdezés funkciót használtam.
A Google Sheets általunk használt funkciói
.
Ahhoz, hogy hatékonyan készíthessünk olyan ellenőrzéseket, mint ez a példa, tudnunk kell, hogyan navigáljunk a táblázatkezelő környezetben (mindegyik hasonlóan működik). Győződjön meg róla, hogy tudja használni a következő funkciókat:
- SEARCH.VERTICAL: https://support.google.com/docs/answer/3093318?hl=pl
- Pivot táblázatok: https://support.google.com/docs/answer/1272900?co=GENIE.Platform%3DDesktop&hl=en
- Kérdezés: https://support.google.com/docs/answer/3093343?hl=pl
- Import XML: https://support.google.com/docs/answer/3093342?hl=pl
- Feltételes formázás: https://support.google.com/docs/answer/78413?co=GENIE.Platform%3DDesktop&hl=en
Mi következik?
.
A munka ezzel még nem ért véget. Az itt összegyűjtött adatokat következtetésekké kell alakítani. Amit eddig sikerült meglátnom, azok a következők:
- A Senuto blogon található tartalmak egy része duplikált (ugyanarról szólnak).
- A cikkekben rejlő teljes potenciálnak csak 1%-át használtuk ki.
- Nagyon sok a duplikáció.
- A cikkeket sok helyen ki kell egészíteni további kulcsszavas kifejezésekkel (ezt a kulcsszavas hiányelemzésből tudom).
- A cikkek nagy részének kevesebb mint 10 belső linkje van – ezen még dolgoznunk kell.
.
.
.
Ha egy ilyen audit landolna egy ügyfélnél, akkor szükségünk lenne egy további .pdf fájlra, amely tartalmazza az egyes információk leírását, vagy az elvégzendő feladatok listáját. A fájlunkba más információkat is behúzhatnánk, például a versenytársak címszavait, címtábláikat stb. Itt azonban megállunk. A célom az volt, hogy egy használható munkafolyamatot mutassak be. A Senutónál olyan eszközökön dolgozunk, amelyek támogatják ezt a munkafolyamatot, hogy minél hamarabb elkészíthesse a tartalmi auditokat.