Cum se face un audit de conținut? 10 pași pentru a optimiza conținutul site-ului dvs

Auditul de conținut este una dintre sarcinile pe care specialiștii SEO le îndeplinesc zilnic. Rareori vă confruntați cu situația în care site-ul nu are conținut și puteți planifica totul de la început, după artă. De cele mai multe ori, site-ul are deja un anumit conținut care trebuie optimizat. În acest articol, vă voi arăta procesul de la A la Z pentru a efectua un audit avansat al conținutului existent. La sfârșitul articolului veți găsi, de asemenea, un șablon gata pregătit pentru a fi folosit în timpul propriului audit..
Principalele concluzii
- Pentru a realiza un audit de conținut eficient, este esențial să colectați URL-urile existente ale site-ului, folosind metode precum crawl-ul cu instrumente SEO specializate sau extragerea adreselor din sitemap-uri XML.
- Informațiile de bază necesare într-un audit includ titluri, antete, data publicării, legături canonice și metadate, care pot fi colectate eficient folosind instrumente precum Analiza de vizibilitate Senuto.
- Analiza vizibilității URL-urilor este crucială în audit, iar instrumente precum Senuto oferă statistici detaliate și fraze cheie specifice pentru fiecare adresă URL analizată.
- Keyword Gap Analysis ajută la identificarea oportunităților ratate prin determinarea frazelor cheie pentru care conținutul ar trebui să fie vizibil, dar nu este încă.
- Auditul de conținut trebuie să se finalizeze cu acțiuni concrete, cum ar fi eliminarea conținutului duplicat, completarea cu fraze de cuvinte cheie suplimentare și îmbunătățirea legăturilor interne, pentru a maximiza potențialul SEO al site-ului.
Etapa 1 Obținerea URL-urilor
.
În primul pas, trebuie să achiziționați toate URL-urile care conțin conținut publicat. În acest caz, vom face un audit de conținut pe blogul Senuto. URL-urile pot fi obținute în mai multe moduri.
Metoda nr. 1: rawl-ul site-ului realizat cu un instrument precum Screaming Frog sau Sitebulb.
Metoda numărul 2: extragerea adreselor dintr-un sitemap XML. În cazul site-ului Senuto, avem un sitemap separat care conține toate postările de pe blogul nostru (https://www.senuto.com/pl/post-sitemap.xml). O astfel de hartă este generată de toate plugin-urile populare de WordPress. Dacă nu aveți un sitemap care conține doar postările de pe blog, va trebui să acordați adreselor o prelucrare suplimentară. Odată ce aveți o adresă sitemap, puteți utiliza Google Sheets pentru a răsfoi adresele.
Utilizați formula de aici:.
=IMPORTXML("https://www.senuto.com/pl/post-sitemap.xml", "//*[local-name() ='url']/*[local-name() ='loc']").

*După câteva secunde, URL-urile din sitemap ar trebui să apară în foaie. Dacă formula nu funcționează, înlocuiți ”,” cu ”;”.
Metoda #3: Descărcarea URL-urilor din Senuto. Puteți configura un filtru în raportul de articole pentru a afișa numai URL-urile care conțin un blog. În acest fel, însă, veți omite articolele care nu afișează nici un fraze de cuvinte cheie.
 .
.
Nu aveți încă un cont Senuto?.
Click >>aici<< și folosiți gratuit timp de 2 săptămâni!.
Înainte de a trece la pasul următor, adăugați în continuare un identificator numeric la fiecare URL. Acest identificator vă va permite să combinați datele pentru URL-uri din mai multe surse.

Am ajuns în punctul în care am colectat deja toate URL-urile articolelor de pe blog. Putem trece la următorul pas.
Pasul 2 Informații URL de bază
.
În acest pas, dorim să colectăm informații URL de bază de care vom avea nevoie într-o etapă ulterioară. Acestea includ:
- Title tags .- Headers .- Data publicării .- Legături canonice .- Blagăre meta robots .- Distanța față de pagina principală .- Lungimea conținutului .- Numărul de linkuri interne .- Numărul de linkuri externe .- Alte elemente .
Singura modalitate de a determina toate aceste date este de a face un crawl al site-ului (folosind Screaming Frog, de exemplu). Cu toate acestea, dacă săriți peste legăturile din toate acestea, vă puteți limita la a lucra doar în Google Sheets. Mai jos veți găsi formulele care vor introduce aceste date în Google Sheets.
-
Title tag:
=IMPORTXML(B2,"//title").
- B2 conține URL-ul. Trăgând formula în jos, o vom aplica la toate URL-urile.

*Pentru o listă cu mai mult de 200 de URL-uri, această metodă nu va funcționa.
-
Eticheta H1:
=IMPORTXML(A2,"//h1").
- Există un URL în A2. Formula va prelua toate elementele care corespund (toate antetele H1). Dacă dorim să recuperăm doar primul antet H1, trebuie să folosim formula
=IMPORTXML(A2,"(//h1)[1]").
-
Etichete H2:
=IMPORTXML(A2,"//h2").
-
Legătură canonică:.
=IMPORTXML(A2,"//link[@rel='canonical']/@href").
-
Etichetă meta robots:.
=IMPORTXML(A2,"//meta[@name='robots']/@content").
În multe cazuri, putem considera utilă auditarea unor elemente suplimentare din pagină, cum ar fi autorul textului, data publicării acestuia, numărul de comentarii, categoria, tags etc. În acest caz, putem folosi și Google Sheets. În formula Import XML, putem specifica xPath-ul din care foaia trebuie să recupereze datele. Mai jos puteți vedea acest lucru în exemplul de pe blogul Senuto.
Putem efectua o astfel de extragere pentru orice element din pagină. În instrumente precum Screaming Frog acest lucru este de asemenea posibil și funcționează în același mod. Atunci când configurăm crawl-ul în meniul de configurare >> custom >> extraction, putem specifica datele pe care dorim să le extragem.
Dacă ați extras datele de publicare a conținutului pentru auditul dumneavoastră, atunci într-o coloană separată utilizați formula =TODAY(), care va insera valoarea datei de astăzi în rând. Apoi, scădeți această dată din data publicării articolului.
 .
.
Acest text special este exact de acum 2 zile. Vom folosi apoi acest lucru pentru a examina relația dintre vizibilitatea textului și data publicării.
Toate datele pe care le-am descris aici pot fi găsite în șablonul Google Docs de la sfârșitul articolului. Am folosit instrumentul Screaming Frog și formulele Google Sheets pentru a le colecta.
La sfârșitul articolului veți găsi, de asemenea, un șablon gata făcut pe care să îl folosiți în timpul propriului dvs. audit..
Tip: la Senuto lucrăm în prezent la un instrument care vă va permite să faceți astfel de operațiuni pe lista dvs. de URL-uri. Acesta ar trebui să fie disponibil la începutul anului 2021.
Date de vizibilitate URL din Pasul 3
.
În acest pas, colectăm date privind vizibilitatea URL-urilor. În două dimensiuni:
- Statistică - informații despre câte fraze cheie din TOP3/TOP10 sunt vizibile URL-urile noastre .- Fraze - informații, pe ce fraze sunt vizibile adresele individuale .
Aici vom folosi instrumentul analiză URL din Senuto, creat în acest scop.
În prima etapă, recuperez statisticile pentru lista de URL-uri.
 .
.
Import datele în fișierul Google Sheets de bază și folosesc SEARCH.VERTICAL pentru a potrivi datele. Am ajuns la 3 coloane:
- TOP 3 - numărul de fraze cheie pe care URL-ul le are în TOP 3 .- TOP 10 - numărul de fraze cheie pe care URL-ul le are în TOP 10 .- Vizibilitate - numărul lunar estimat de vizite pentru un articol cu SEO .
În al doilea pas, voi folosi din nou același instrument, dar în loc de statistici, voi prelua din listă toate frazele pentru care sunt vizibile URL-urile. Am pus frazele într-o filă separată.
Pasul 4. Date privind frazele pe care sunt vizibile adresele URL
.
În pasul următor, vom adăuga informații despre frazele pe care sunt vizibile articolele noastre în fișierul nostru**.**
Din nou, vom folosi aici același instrument din Senuto - Analiză URL (în loc de modul statistică, alegeți modul fraze de cuvinte cheie).
Frazele pe care le-am descărcat de la instrument se află în fila “phrases” din fișier.
Step 5. Date despre linkuri din ahrefs
.
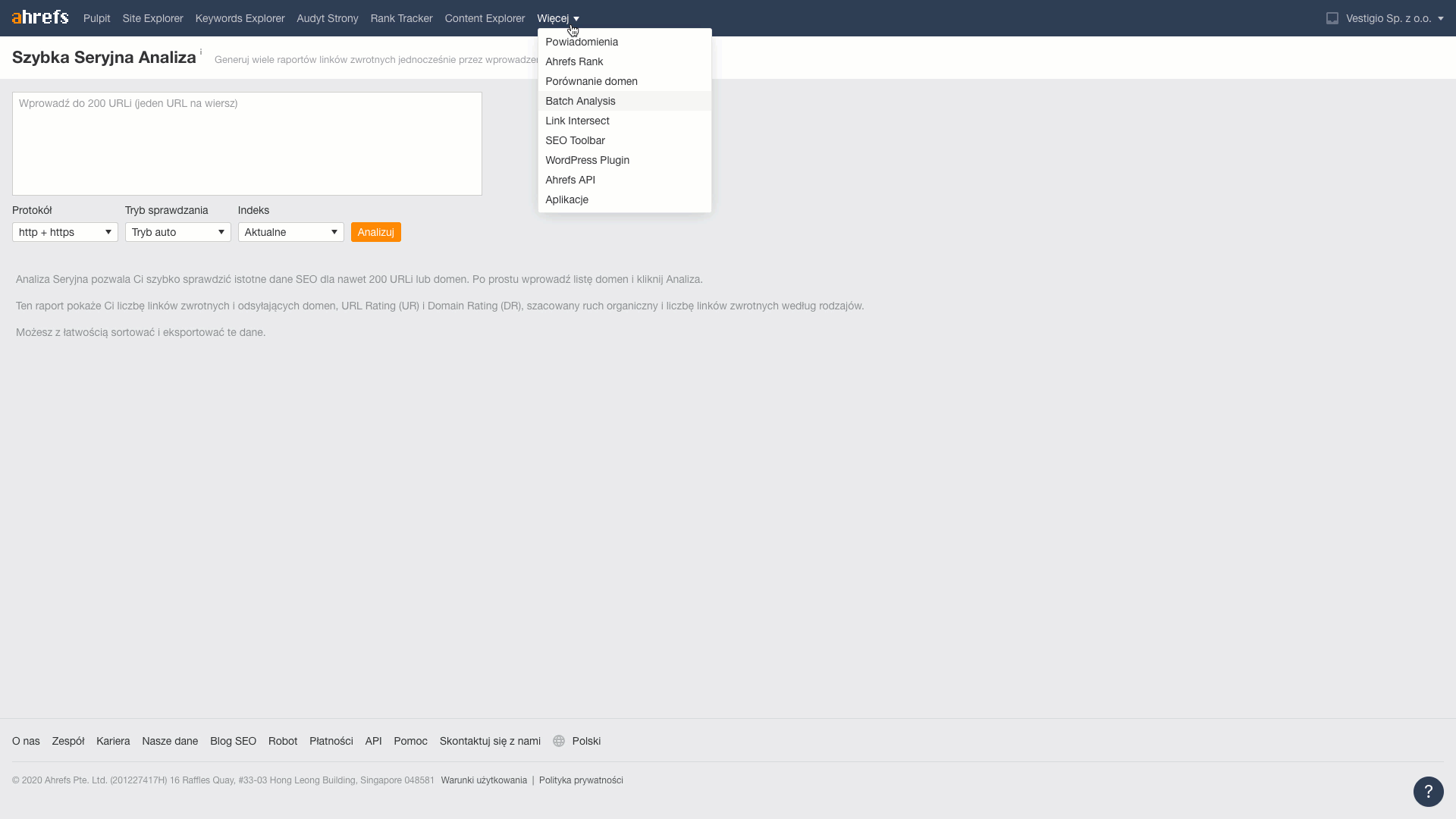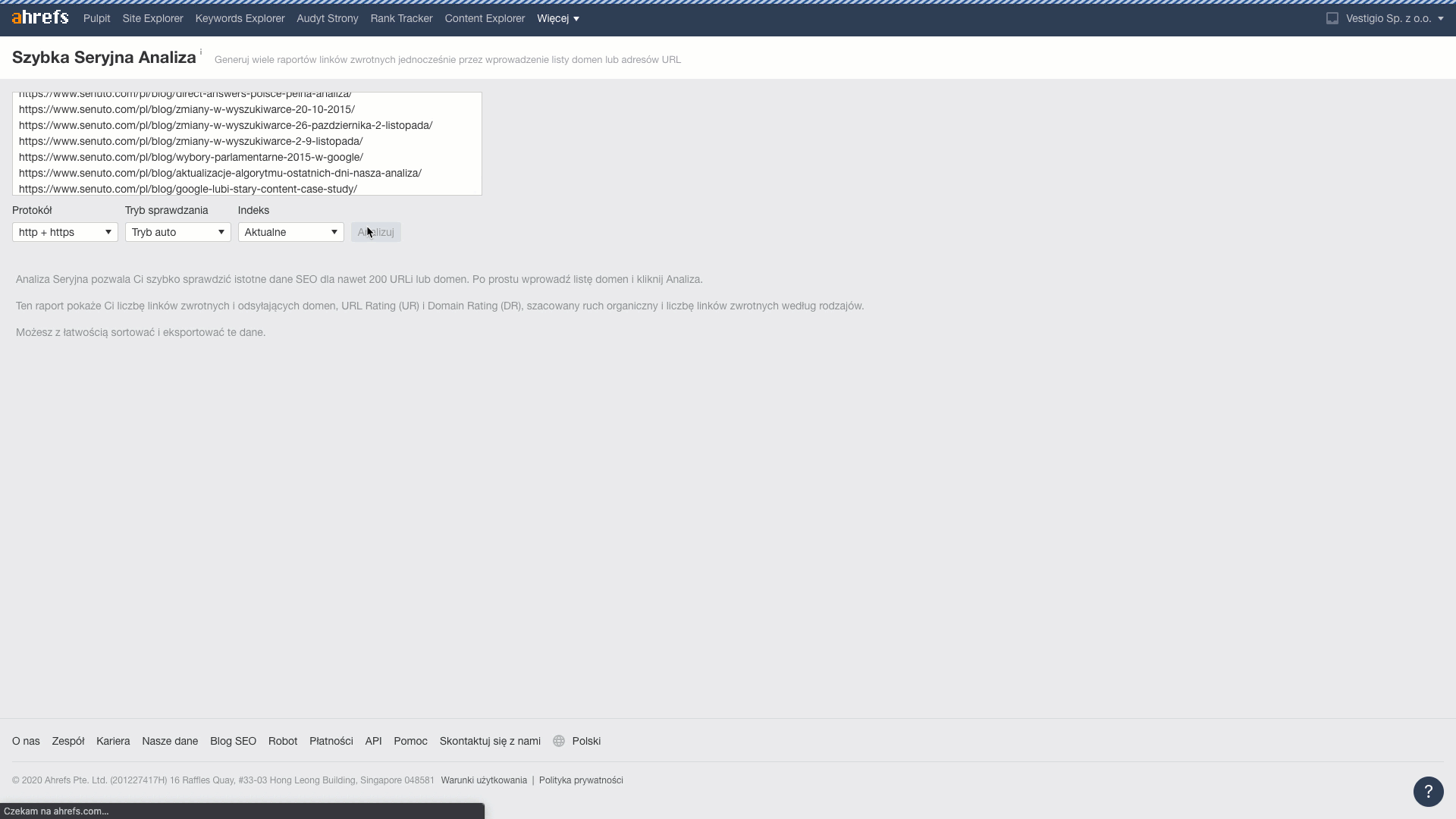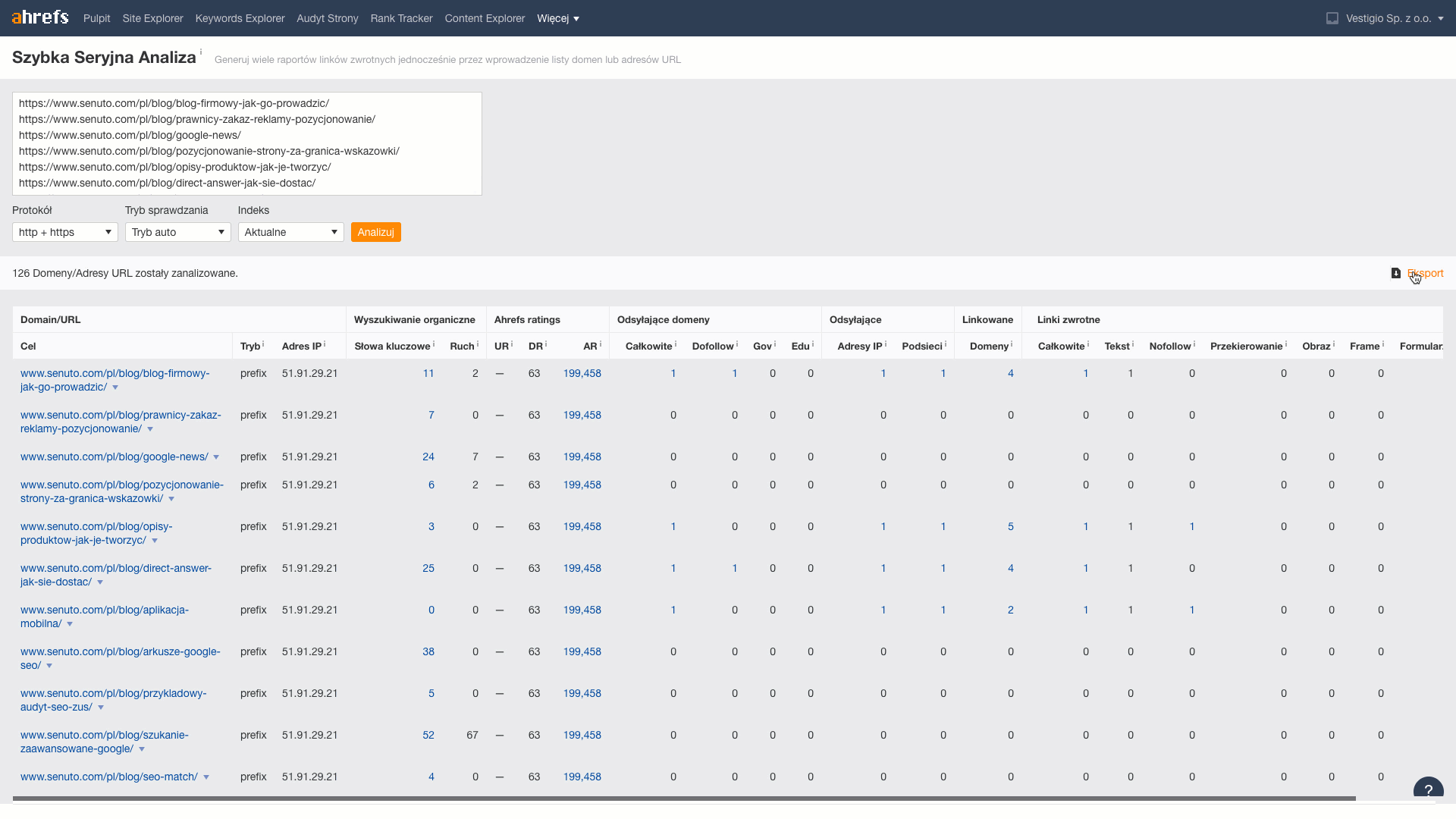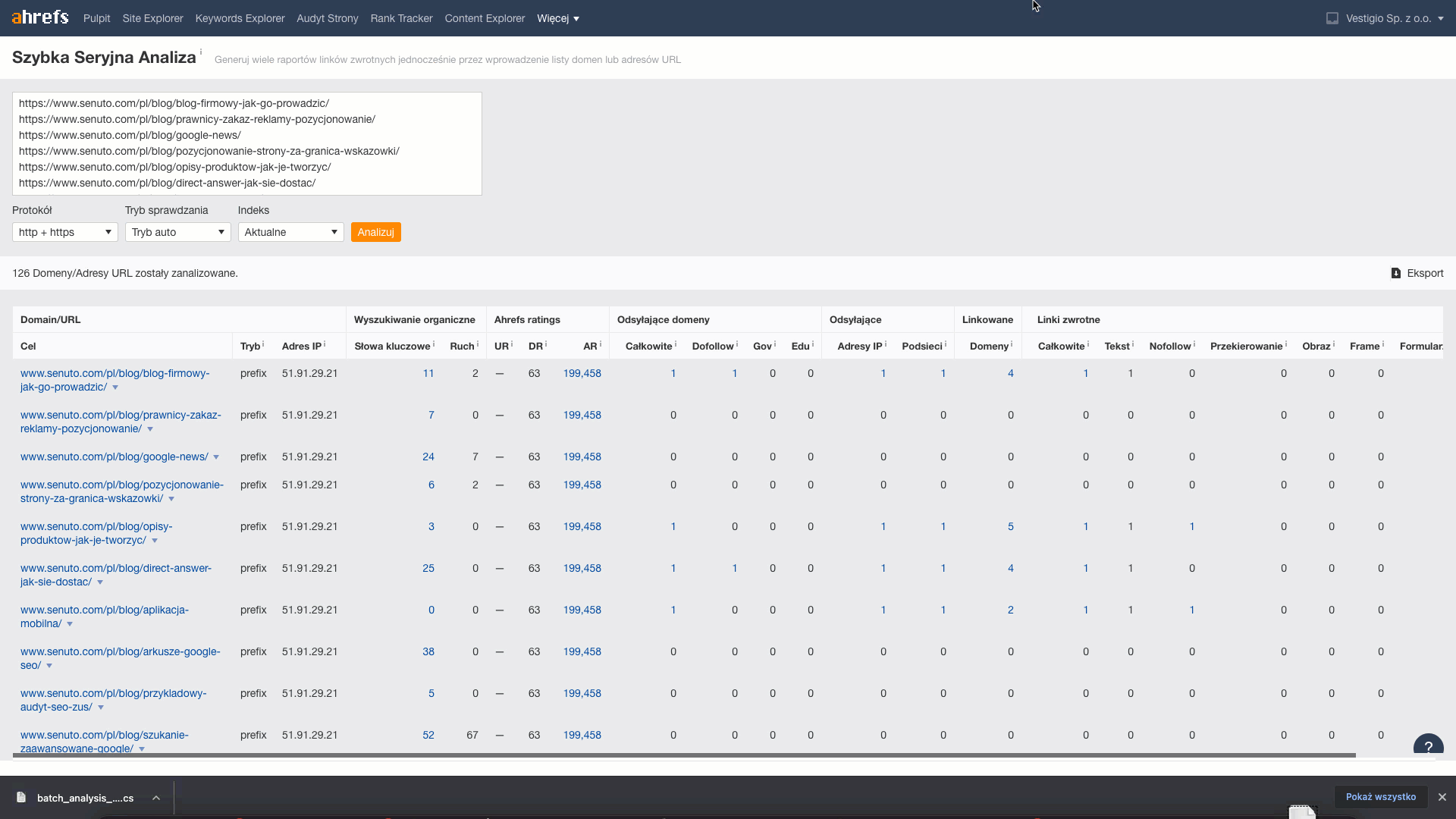
În acest pas, pentru fiecare URL recuperăminformații despre numărul de linkuri și domenii care duc la acesta. Pentru a face acest lucru, vom utiliza instrumentul Batch Analysis inclus în Ahrefs.
Din datele descărcate, transfer în foaie metricile Reffering domains (informații din câte domenii au link-uri către articol), Total backlinks (numărul de link-uri care duc către articol).
Step 6 Keyword Gap
.
În acest pas, dorim să determinăm pentru fiecare articol frazele de cuvinte cheie pentru care acesta ar trebui să fie vizibil și nu este încă. O astfel de analiză se numește în mod obișnuit analiză a decalajelor de cuvinte cheie.
Pentru aceasta, vom avea nevoie de informații despre fraza principală a articolului - acesta este cuvântul cheie pentru care articolul ar trebui să fie vizibil (coloana Main Keyword din fișă). În acest caz am făcut-o manual, dar puteți folosi și H1 headings, tag-uri sau alte elemente care conțin în general această frază. Nu fiecare articol de blog este scris cu gândul la SEO, așa că nu toate articolele din fișa noastră au o frază principală. Am adăugat o coloană suplimentară “text SEO?” pentru a ști care text a fost scris cu intenție SEO și care nu.
Procesul pentru a prelua aceste date este următorul:.
- Pasul 1 - Recuperez TOP 20 de rezultate din SERP pentru fiecare frază marcată ca cuvinte cheie principal. .2. Pasul 2 - Recuperez toate frazele care prezintă URL-uri care se află în TOP 20 pentru frazele selectate anterior. .3. Pasul 3 - Verific poziția domeniul meu pe aceste fraze. .4. Etapa 4 - Legătura datelor folosind un identificator, astfel încât să știu ce fraze sunt atribuite fiecărui articol.
În acest fel, în fila “keyword gap” au apărut 9482 de fraze de cuvinte cheie. Bazându-mă pe aceste informații, sunt acum în măsură să calculez potențialul limitativ al fiecărui articol (numărul mediu lunar maxim de căutări pentru un articol) și numărul de fraze pentru care acesta ar trebui să fie vizibil.
Pentru a face acest lucru, creăm un tabel pivot (fila “Keyword GAP - Statistics”). În această filă, pentru fiecare ID, am determinat numărul de fraze atribuite articolului și potențialul determinat ca sumă a căutărilor pentru toate frazele. Apoi, extrag aceste informații (coloanele AI și AJ) în fila “Data” și adaug coloana AK, care numără potențialul maxim de trafic pentru articol, și coloana AL, care numără potențialul pe care articolul l-a folosit deja.
Dacă sortez acum după coloana AL, pot clasifica articolele în ordinea celui mai mare potențial rămas de utilizat. De asemenea, pot face o sortare dublă după coloana AK și coloana AL pentru a desemna articolele cu potențial ridicat în cazul în care potențialul utilizat este scăzut. Pe de altă parte, folosind ID-ul din fila “Keyword gap”, pot desemna frazele care lipsesc dintr-un articol.
Tip: În prezent lucrăm în Senuto la un instrument care vă va permite să recuperați TOP 20 rezultate pentru orice frază. O astfel de adăugare va apărea și în integrarea noastră cu Google Sheets. Între timp, puteți face acest lucru folosind instrumentul SERP History sau API-ul Senuto.
Step 7 Competitor Analysis
.
În analiza noastră, trebuie să analizăm și concurența. În pasul anterior, am descărcat TOP 20 de rezultate din SERP pentru fiecare frază din audit. Aceste date pot fi găsite în fila “TOP 20”. Pentru fiecare URL, am descărcat, de asemenea, lungimea conținutului său.
Aceste informații ne vor permite să determinăm dacă lungimea conținutului nostru în raport cu concurența este prea scurtă. Din această filă, am creat 2 tabele pivot în fila “Lungime conținut” - primul tabel măsoară lungimea medie a conținutului din TOP 20, în timp ce al doilea măsoară lungimea medie a conținutului din TOP 3. De asemenea, am mutat aceste date în fila “Date” în coloanele Y-AC, unde am determinat, de asemenea, pe baza lungimii medii a conținutului din TOP 3, dacă textul este prea scurt.
Rețineți că lungimea conținutului, în majoritatea cazurilor, nu contează prea mult pentru clasament. Vom verifica acest lucru mai târziu în această analiză.
Tip: În prezent lucrăm la un instrument la Senuto care vă va permite să preluați TOP 20 rezultate pentru orice frază. O astfel de adăugare va apărea și în integrarea noastră cu Google Sheets. Între timp, puteți face acest lucru cu instrumentul SERP Analysis.
Pasul 8 Relații
.
Următorul pas al analizei este examinarea relațiilor dintre diferitele caracteristici. Aceasta ne va ajuta să aflăm, care date din audit ar trebui să aibă cea mai mare prioritate. Aici examinăm corelația liniară a două variabile. Corelația operează în intervalul -1 (nicio corelație) până la 1 (corelație puternică). În intervalul de >0,3, putem vorbi deja despre corelația a două variabile.
Puteți găsi corelația în fila “Tablou de bord”, în coloana B-C, la rândul 92-98. Utilizăm funcția =CORREL pentru a determina corelația.
După cum puteți vedea, în acest caz nu există corelații puternice între niciun parametru, ceea ce se datorează cantității mici de date - eșantionul este de doar puțin peste 80 de articole. Puteți vedea doar o corelație între numărul de fraze din TOP 10 și lungimea articolului - acest lucru pare firesc, deoarece cu cât articolul este mai lung, cu atât mai multe fraze cu coadă lungă pe care le captează. Totuși, acest lucru nu se traduce în vizibilitate.
Step 9 Date de trafic din Google Search Console
.
Pentru fiecare URL, este de asemenea o idee bună să preluați informații despre Câte click-uri din rezultatele căutării a avut recent (în cazul nostru, este vorba de 6 luni). Am creat o filă separată “Data GSC” de unde am descărcat aceste informații.
Am folosit pluginul Google Sheets Search Analytics for Sheets - acesta recuperează date pentru toate URL-urile. Utilizând funcția SEARCH.VERTICAL, am mutat aceste informații în fila “Data”.
Step 10 Duplicates
.
În timpul creării auditului, am observat că în trei cazuri cuvântul cheie principal al articolelor este același, ceea ce înseamnă că trei articole au un duplicat.
Am mutat datele cu ajutorul funcției de interogare în fila “Duplicates”. În această filă, am creat coloana J și am introdus valoarea “1” în primul rând. În rândul următor, am inserat formula:
=if(C3=C2, J2, J2+1).
- această formulă verifică dacă valoarea din rândul C3 este egală cu valoarea din rândul C2 (dacă cuvântul cheie principal este același). Dacă valorile sunt identice, se ia valoarea rândului J2 (ID); dacă nu, se adaugă 1 la aceasta. În acest fel, rândurile care au același cuvânt-cheie principal vor avea același ID și va fi ușor să le prindem. Acum pot face un tabel pivot după valoarea ID-ului și numărul de apariții ale acestuia și pot decide ce să fac cu acel conținut.
Prezentare date
.
Prezentarea datelor este, de asemenea, o parte importantă a oricărui audit. Prin urmare, auditul a inclus o filă “Tablou de bord”, unde am adunat toate informațiile cele mai importante. Aici am folosit în principal funcția de interogare.
Funcțiile din Google Sheets pe care le-am folosit
.
Pentru a crea în mod eficient audituri ca acest exemplu, trebuie să știți cum să navigați în mediul foilor de calcul (toate funcționează în mod similar). Asigurați-vă că puteți utiliza următoarele funcții:
- SEARCH.VERTICAL: https://support.google.com/docs/answer/3093318?hl=pl
- Tabele pivotante: https://support.google.com/docs/answer/1272900?co=GENIE.Platform%3DDesktop&hl=en
- Query: https://support.google.com/docs/answer/3093343?hl=pl
- Import XML: https://support.google.com/docs/answer/3093342?hl=pl
- Formatul condiționat: https://support.google.com/docs/answer/78413?co=GENIE.Platform%3DDesktop&hl=en
Ce urmează?
.
Acesta nu este sfârșitul lucrării. Datele pe care le-am colectat aici trebuie transformate în concluzii. Ceea ce am reușit să văd sunt:
- Cel puțin conținut de pe blogul Senuto este duplicat (sunt despre același lucru). .- Am folosit doar 1% din potențialul total pe care îl au articolele.
- Există foarte multe dublări.- În multe locuri, articolele trebuie completate cu fraze de cuvinte cheie suplimentare (asta o știu din analiza deficitului de cuvinte cheie). .- Un număr mare de articole au mai puțin de 10 link-uri interne - va trebui să lucrăm la acest aspect. .
Dacă un astfel de audit ar ateriza la un client, am avea nevoie de un fișier .pdf suplimentar cu o descriere a fiecărei informații, sau o listă de sarcini de îndeplinit. Am putea trage și alte informații în fișierul nostru, cum ar fi titlurile concurenților, etichetele lor de titlu etc. Cu toate acestea, ne vom opri aici. Scopul meu a fost să prezint un flux de lucru care poate fi utilizat. La Senuto, lucrăm la astfel de instrumente care vor susține acest flux de lucru, astfel încât să puteți crea audituri de conținut cât mai curând posibil.
FAQ
Cum obțin URL-urile necesare pentru un audit de conținut?
URL-urile necesare pentru un audit de conținut pot fi obținute prin crawl-ul site-ului cu instrumente precum Screaming Frog sau Sitebulb, extragerea adreselor dintr-un sitemap XML sau descărcarea URL-urilor direct din Senuto.
Ce informații de bază sunt necesare în etapa a doua a auditului de conținut?
În etapa a doua a auditului de conținut sunt necesare informații de bază precum title tags, headers, data publicării, legături canonice, blagăre meta robots, distanța față de pagina principală, lungimea conținutului, numărul de linkuri interne și externe.
Cum pot colecta date despre vizibilitatea URL-urilor?
Datele despre vizibilitatea URL-urilor pot fi colectate folosind instrumentul de analiză URL din Senuto, care oferă informații atât statistice despre numărul de fraze cheie din TOP3/TOP10, cât și frazele specifice pe care sunt vizibile adresele individuale.
Ce este un Keyword Gap și cum îl determin?
Un Keyword Gap este o analiză care determină frazele de cuvinte cheie pentru care un articol ar trebui să fie vizibil și nu este încă. Acest lucru se face prin recuperarea TOP 20 de rezultate din SERP pentru fiecare frază cheie principală și analizarea poziției domeniului pe aceste fraze.
Cum pot folosi datele colectate într-un audit de conținut?
Datele colectate într-un audit de conținut trebuie transformate în concluzii pentru a identifica conținutul duplicat, a evalua potențialul neutilizat al articolelor, a descoperi lipsa frazelor de cuvinte cheie și a determina necesitatea îmbunătățirii legăturilor interne. Aceste informații pot fi folosite pentru a optimiza și îmbunătăți strategia de conținut. Află mai multe despre auditul de conținut.

Damian Sałkowski
CEO Senuto. Specjalista SEO z bagażem doświadczeń z rynku polskiego i rynków zagranicznych. Autor dwóch książek o marketingu internetowym i kilkuset artykułów w tej tematyce. Prywatnie fan piłki nożnej i sportów motorowych.
All articles →