 Damian Sałkowski
Damian Sałkowski Audit obsahu je jedním z úkolů, které specialisté na SEO provádějí denně. Málokdy se setkáte se situací, kdy web nemá žádný obsah a můžete vše naplánovat od začátku, podle umění. Nejčastěji se stává, že web již nějaký obsah, který je třeba optimalizovat, má. V tomto článku vám ukážu postup od A do Z, jak provést pokročilý audit stávajícího obsahu. Na konci článku najdete také připravenou šablonu, kterou můžete použít při vlastním auditu..
Nejdůležitější body
- Audit obsahu je klíčovým úkolem pro SEO specialisty, který zahrnuje optimalizaci již existujícího obsahu na webu.
- V prvním kroku je důležité získat všechny URL adresy zveřejněného obsahu pomocí nástrojů jako Screaming Frog nebo Senuto.
- Shromažďování základních informací o URL, jako jsou titulkové značky, záhlaví a data zveřejnění, je nutné pro další analýzu.
- Analýza viditelnosti URL pomocí nástroje Visibility Analysis od Senuto poskytuje statistiky a klíčové fráze, na kterých jsou adresy viditelné.
- Pro získání informací o odkazech a doménách vedoucích na URL je vhodné použít nástroj Ahrefs.
Krok 1 Získání adres URL
.
V prvním kroku je třeba získat všechny URL, které obsahují zveřejněný obsah. V tomto případě budeme provádět audit obsahu na blogu Senuto. Adresy URL lze získat několika způsoby.
Způsob č. 1: procházení webu provedené pomocí nástroje, jako je Screaming Frog nebo Sitebulb.
Způsob č. 2: extrakce adres z mapy stránek XML. V případě webu Senuto máme samostatnou mapu stránek, která obsahuje všechny naše blogové příspěvky (https://www.senuto.com/pl/post-sitemap.xml). Takovou mapu generují všechny oblíbené pluginy WordPressu. Pokud nemáte mapu stránek, která by obsahovala pouze příspěvky z blogů, budete muset dát adresám nějaké zpracování navíc. Jakmile budete mít mapu stránek, můžete k procházení adres použít tabulky Google.
Použijte vzorec zde: .
=IMPORTXML("https://www.senuto.com/pl/post-sitemap.xml", "//*[local-name() ='url']/*[local-name() ='loc']")
.

*Po několika sekundách by se v listu měly objevit adresy URL z mapy stránek. Pokud vzorec nefunguje, nahraďte „,“ za „;“.
Metoda č. 3: Stahování adres URL ze stránek Senuto. V sestavě položek můžete nastavit filtr, který zobrazí pouze adresy URL obsahující blog. Tímto způsobem však vynecháte články, které nezobrazují žádné klíčové fráze.
 .
.
Ještě nemáte účet Senuto?.
Klikněte na >>zde<< a používejte 2 týdny zdarma!.
Než přejdete k dalšímu kroku, přidejte ještě ke každé adrese URL číselný identifikátor. Tento identifikátor vám umožní kombinovat údaje pro adresy URL z více zdrojů.

Dosáhli jsme bodu, kdy jsme již shromáždili všechny adresy URL článků blogu. Můžeme přejít k dalšímu kroku.
Vyzkoušejte Senuto Suite na 14 dní zdarma
Pojďme na to!Krok 2 Základní informace o URL
.
V tomto kroku chceme shromáždit základní informace o URL, které budeme potřebovat v pozdější fázi. Patří sem např:
- Titulkové značky
- Záhlaví
- Data zveřejnění
- Kanonické odkazy
- Značky metarobotů
- Vzdálenost od domovské stránky
- Délka obsahu
- Počet interních odkazů
- Počet externích odkazů
- Další prvky
.
.
.
.
.
.
.
.
.
.
Jediný způsob, jak zjistit všechny tyto údaje, je provést procházení webu (například pomocí programu Screaming Frog). Pokud však všechny tyto odkazy přeskočíte, můžete se omezit pouze na práci v Google Sheets. Níže najdete vzorce, které tato data dostanou do Tabulek Google.
- Titulní značka:
=IMPORTXML(B2,"//title")
.
– B2 obsahuje adresu URL. Přetažením vzorce dolů jej použijeme na všechny adresy URL.

*Pro seznam s více než 200 adresami URL tato metoda nebude fungovat.
- Tag H1:
=IMPORTXML(A2,"//h1")
.
– V položce A2 se nachází adresa URL. Vzorec načte všechny odpovídající prvky (všechny hlavičky H1). Pokud chceme načíst pouze první záhlaví H1, měli bychom použít vzorec=IMPORTXML(A2,"(//h1)[1]")
.
=IMPORTXML(A2,"//h2")
.
=IMPORTXML(A2,"//link[@rel='canonical']/@href")
.
=IMPORTXML(A2,"//meta[@name='robots']/@content")
.
V mnoha případech se nám může hodit audit dalších prvků ze stránky, jako je autor textu, datum jeho zveřejnění, počet komentářů, kategorie, značky atd. V tomto případě můžeme využít také tabulky Google. Ve vzorci Import XML můžeme zadat xPath, ze kterého má list načíst data. Níže to můžete vidět v příkladu blogu Senuto.
Takovou extrakci můžeme provést pro libovolný prvek ze stránky. V nástrojích, jako je Screaming Frog, je to také možné a funguje to stejným způsobem. Při konfiguraci procházení v nabídce konfigurace >> vlastní >> extrakce můžeme určit data, která chceme extrahovat.
Pokud jste pro audit extrahovali data zveřejnění obsahu, pak v samostatném sloupci použijte vzorec =TODAY(), který do řádku vloží hodnotu dnešního data. Toto datum pak odečteme od data zveřejnění článku.
 .
.
Tento konkrétní text je starý přesně 2 dny. Toho pak využijeme ke zkoumání vztahu mezi viditelností textu a datem zveřejnění.
Všechny údaje, které jsem zde popsal můžete najít v šabloně Dokumentů Google na konci článku. K jejich shromáždění jsem použil nástroj Screaming Frog a vzorce v tabulkách Google.
Na konci článku najdete také připravenou šablonu, kterou můžete použít při vlastním auditu.
Tip:ve společnosti Senuto v současné době pracujeme na nástroji, který vám umožní provádět takové operace se seznamem adres URL. Měl by být k dispozici na začátku roku 2021.
Údaje o viditelnosti URL ve třetím kroku
.
V tomto kroku shromažďujeme údaje o viditelnosti URL. A to ve dvou dimenzích:
- .
- Statistika – informace o tom, kolik klíčových frází v TOP3/TOP10 jsou naše URL viditelné
- Fráze – informace, na kterých frázích jsou jednotlivé adresy viditelné
.
.
Zde použijeme nástroj Analýza URL v aplikaci Senuto, který byl pro tento účel vytvořen.
V prvním kroku načtu statistiky pro seznam adres URL.
 .
.
Data importuji do základního souboru Tabulky Google a pro porovnání dat použiji funkci HLEDAT.VERTIKÁLNĚ. Dospěli jsme ke 3 sloupcům:
- TOP 3 – počet klíčových frází, které má adresa URL v TOP 3
- TOP 10 – počet klíčových frází, které má URL adresa v TOP 10
- Zviditelnění – odhadovaný měsíční počet návštěv článku s SEO
.
.
.
V druhém kroku použiji opět stejný nástroj, ale místo statistik získám ze seznamu všechny fráze, pro které jsou URL viditelné. Fráze vložím do samostatné karty.
Krok 4. Údaje o frázích, na kterých jsou viditelné adresy URL
.
V dalším kroku přidáme do našeho souboru informace o frázích, na kterých jsou naše články viditelné.
Opět zde použijeme stejný nástroj v Senutu – Analýza URL (místo režimu statistika zvolte režim fráze klíčových slov).
Fráze, které jsem z nástroje stáhl, jsou v souboru na kartě „fráze“.
Krok 5. Data odkazů z ahrefs
.
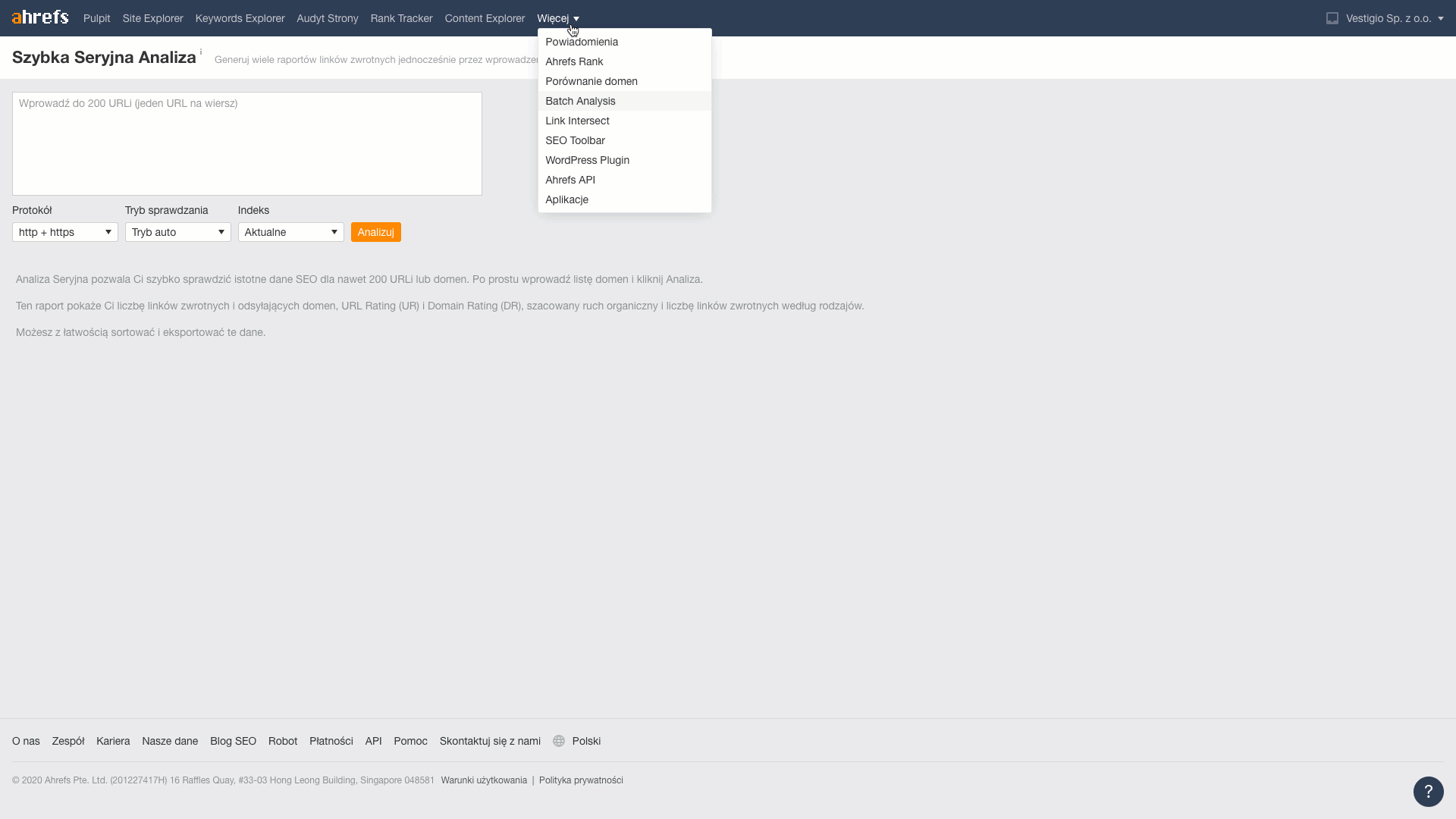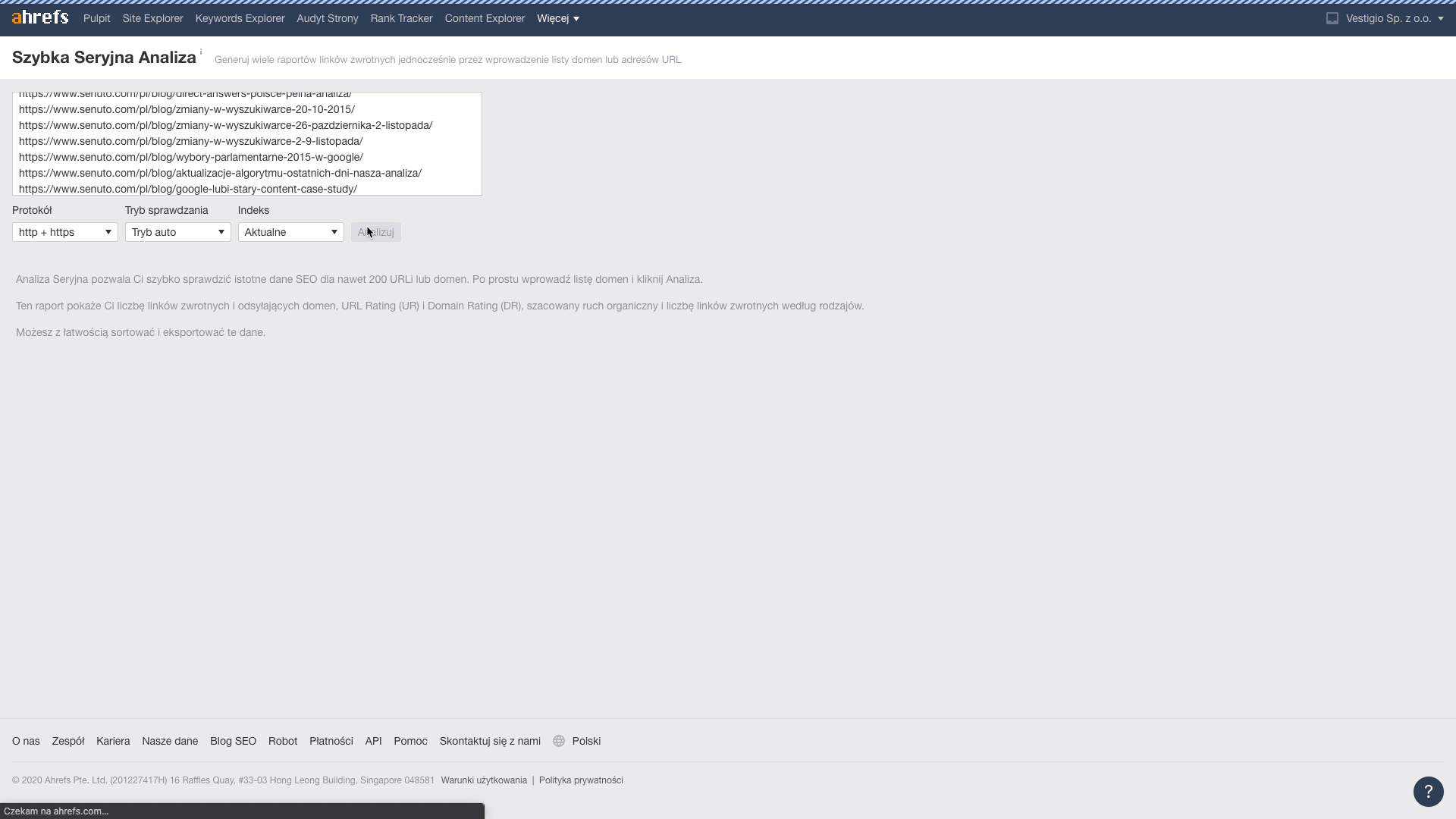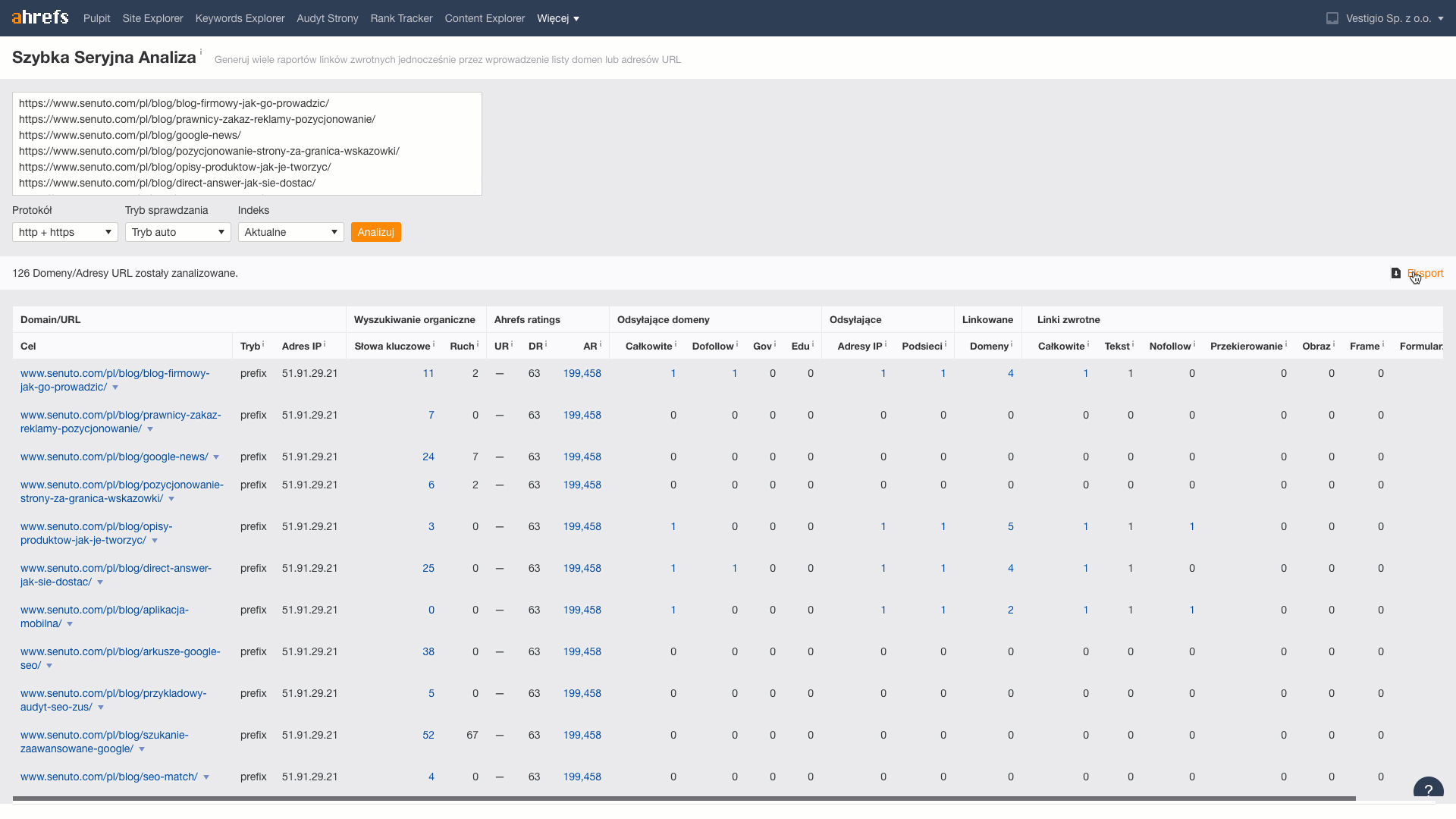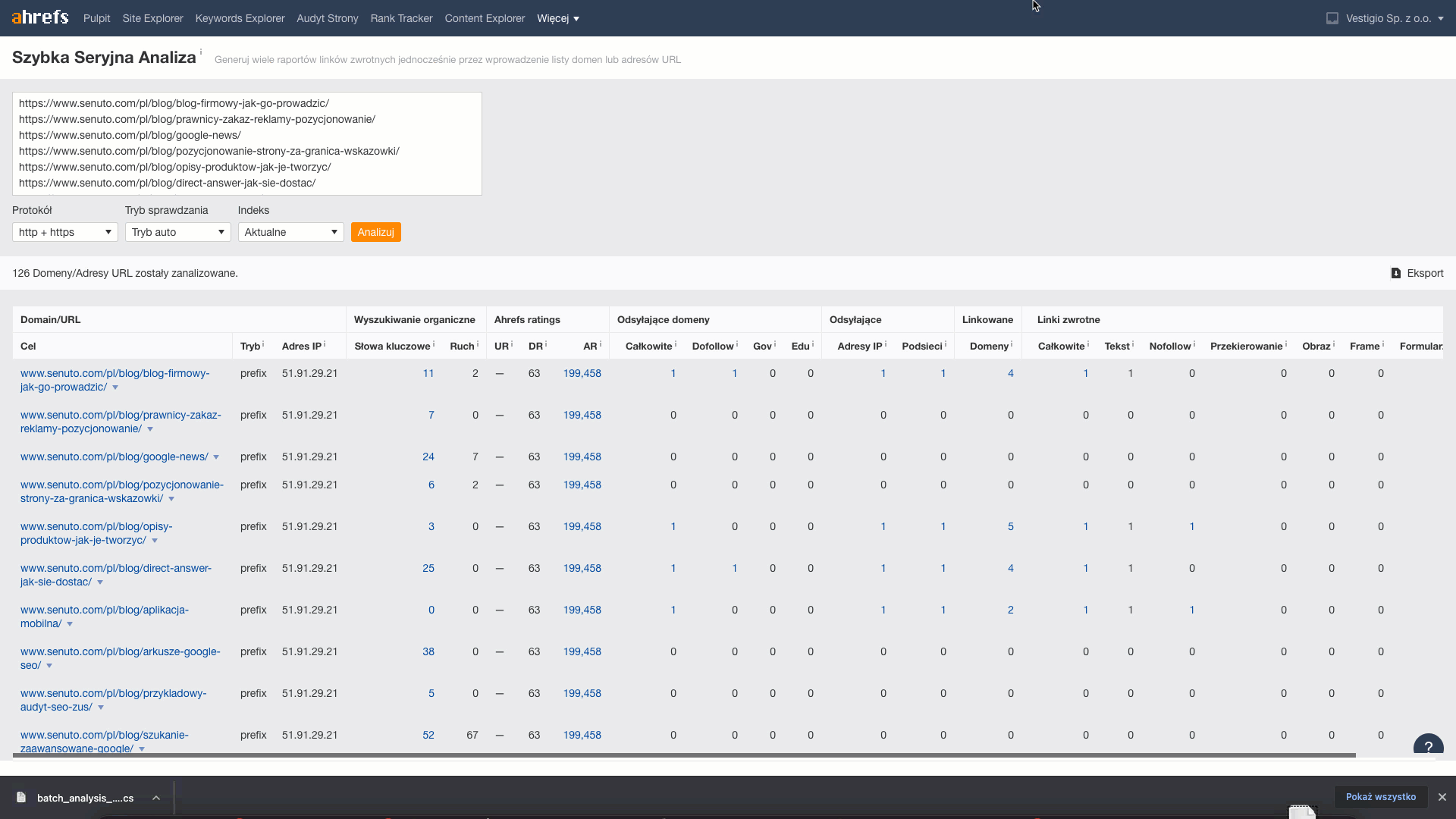
V tomto kroku pro každou adresu URL získámeinformace o počtu odkazů a domén, které na ni vedou. K tomu použijeme nástroj Dávková analýza, který je součástí Ahrefs.
Ze stažených dat přenesu do listu metriky Reffering domains (informace z kolika domén vedou odkazy na článek), Total backlinks (počet odkazů vedoucích na článek).
Krok 6 Mezera mezi klíčovými slovy
.
V tomto kroku chceme pro každý článek určit klíčové fráze, pro které by měl být viditelný a zatím není. Takové analýze se běžně říká analýza mezery mezi klíčovými slovy.
K tomu budeme potřebovat informace o hlavní frázi článku – to je klíčové slovo, pro které by měl být článek viditelný (sloupec Hlavní klíčové slovo v listu). V tomto případě jsem to udělal ručně, alemůžete také použít H1 nadpisy, značky nebo jiné prvky, které tuto frázi obecně obsahují. Ne každý článek na blogu je psán s ohledem na SEO, takže ne každý v našem listu má hlavní frázi. Přidala jsem další sloupec „SEO text?“, abych věděla, který text byl napsán se SEO záměrem a který ne.
Postup pro získání těchto údajů je následující:.
- Krok 1 – Pro každou frázi označenou jako hlavní klíčové slovo získám ze SERPu TOP 20 výsledků
- Krok 2 – Získám všechny fráze, které zobrazují adresy URL, které jsou v TOP 20 pro dříve vybrané fráze.
- Krok 3 – Zkontroluji pozici své domény na těchto frázích.
- Krok 4 – propojím data pomocí identifikátoru, abych věděl, které fráze jsou přiřazeny ke kterému článku.
.
.
.
Tímto způsobem se na kartě „mezera mezi klíčovými slovy“ objevilo 9482 klíčových frází. Na základě těchto informací jsem nyní schopen vypočítat omezující potenciál každého článku (maximální průměrný měsíční počet vyhledávání článku) a počet frází, pro které by měl být viditelný.
Za tímto účelem vytvoříme otočnou tabulku (karta „GAP klíčových slov – statistika“). V této kartě jsme pro každé ID určili počet frází přiřazených k článku a potenciál určený jako součet hledání pro všechny fráze. Tyto informace (sloupce AI a AJ) pak vytáhnu do záložky „Data“ a přidám sloupec AK, který počítá maximální potenciál návštěvnosti článku, a sloupec AL, který počítá, jaký potenciál již článek využil.
Pokud nyní seřadím podle sloupce AL, mohu články seřadit podle nejvyššího zbývajícího potenciálu, který je třeba využít. Mohu také provést dvojí řazení podle sloupce AK a sloupce AL, abych označil články s vysokým potenciálem, u kterých je využitý potenciál nízký. Na druhou stranu mohu pomocí ID na kartě „Mezera v klíčových slovech“ označit fráze, které v článku chybí.
Tip: V současné době pracujeme v Senutu na nástroji, který umožní získat TOP 20 výsledků pro libovolnou frázi. Takový doplněk se objeví také v naší integraci s tabulkami Google. Zatím to můžete provést pomocí nástroje Historie SERP nebo pomocí rozhraní Senuto API.
Krok 7 Analýza konkurence
.
V naší analýze se musíme podívat také na konkurenci. V předchozím kroku jsem pro každou frázi z auditu stáhl TOP 20 výsledků ze SERPu. Tyto údaje najdete na kartě „TOP 20“. Pro každou adresu URL jsem také stáhl délku jejího obsahu.
Tato informace nám umožní určit, zda délka našeho obsahu vzhledem ke konkurenci není příliš krátká. Z této karty jsem vytvořil 2 otočné tabulky v záložce „Délka obsahu“ – první tabulka měří průměrnou délku obsahu v TOP 20, druhá průměrnou délku obsahu v TOP 3. Tyto údaje jsem také přesunul do záložky „Data“ do sloupců Y-AC, kde jsem na základě průměrné délky obsahu z TOP 3 také určil, zda je text příliš krátký.
Mějte na paměti, že délka obsahu ve většině případů nemá pro hodnocení velký význam. To si ověříme později v této analýze.
Tip: V současné době pracujeme na nástroji Senuto, který vám umožní získat TOP 20 výsledků pro libovolnou frázi. Takový doplněk se objeví také v naší integraci s tabulkami Google. Zatím to můžete provést pomocí nástroje Analýza SERP.
Krok 8 Vztahy
.
Dalším krokem analýzy je zkoumání vztahů mezi jednotlivými prvky.To nám pomůže zjistit, které údaje v auditu by měly mít nejvyšší prioritu. Zde zkoumáme lineární korelaci dvou proměnných. Korelace pracuje v rozsahu -1 (žádná korelace) až 1 (silná korelace). V rozsahu >0,3 již můžeme hovořit o korelaci dvou proměnných.
Korelaci naleznete na kartě „Dashboard“ ve sloupci B-C v řádku 92-98. Ke zjištění korelace použijeme funkci =CORREL.
Jak vidíte, v tomto případě není mezi žádnými ukazateli silná korelace, což je způsobeno malým množstvím dat – vzorek čítá jen něco málo přes 80 článků. Vidíte pouze korelaci mezi počtem frází v TOP 10 a délkou článku – to se zdá být přirozené, protože čím delší článek, tím více dlouhých ocasních frází zachytí. To se však nepromítá do viditelnosti.
.
Pro každou adresu URL je také dobré získat informace o tom, kolik kliknutí z výsledků vyhledávání měla v poslední době (v našem případě je to 6 měsíců). Vytvořil jsem samostatnou záložku „Data GSC„, kde jsem tyto informace stáhl.
Použil jsem doplněk Google Sheets Search Analytics for Sheets – ten načítá data pro všechny adresy URL. Pomocí funkce SEARCH.VERTICAL jsem tyto informace přesunul na kartu „Data“.
Krok 10 Duplicates
.
Při vytváření auditu jsem si všiml, že ve třech případech je hlavní klíčové slovo u článků stejné, což znamená, že tři články mají duplicitu.
Data jsem pomocí funkce dotazu přesunul na kartu „Duplikáty“. Na této kartě jsem vytvořil sloupec J a do prvního řádku vložil hodnotu „1“. Do dalšího řádku jsem vložil vzorec:
=if(C3=C2, J2, J2+1)
.
– Tento vzorec kontroluje, zda se hodnota řádku C3 rovná hodnotě řádku C2 (zda je hlavní klíčové slovo stejné). Pokud jsou hodnoty shodné, převezme hodnotu řádku J2 (ID); pokud ne, přičte k ní 1. Tímto způsobem budou mít řádky se stejným hlavním klíčovým slovem stejné ID a bude snadné je zachytit. Nyní mohu vytvořit otočnou tabulku podle hodnoty ID a počtu jeho výskytů a rozhodnout, co s tímto obsahem udělat.
Prezentace dat
.
Důležitou součástí každého auditu je také prezentace dat. Proto byla součástí auditu karta „Dashboard“, kde jsem shromáždil všechny nejdůležitější informace. Využíval jsem zde především funkci dotazování.
Funkce Google Sheets, které jsme použili
.
Abyste mohli efektivně vytvářet audity, jako je tento příklad, musíte se umět orientovat v prostředí tabulkových procesorů (všechny fungují podobně). Ujistěte se, že umíte používat následující funkce:
- .
- VYHLEDÁVÁNÍ.VERTIKÁLNÍ: https://support.google.com/docs/answer/3093318?hl=pl
- Přepočítávací tabulky:
- Přepočítávací tabulky: https://support.google.com/docs/answer/1272900?co=GENIE.Platform%3DDesktop&hl=en
- Dotazy:
- Dotaz na tabulky, které se zobrazují v tabulkách, je možné zadat na základě dotazu, který se zobrazuje v tabulkách: https://support.google.com/docs/answer/3093343?hl=pl
- Import XML: https://support.google.com/docs/answer/3093342?hl=pl
- Podmíněné formátování: https://support.google.com/docs/answer/78413?co=GENIE.Platform%3DDesktop&hl=en
.
.
.
Co dál?“
.
Tímto práce nekončí, z údajů, které jsme zde shromáždili, je třeba vyvodit závěry. To, co se mi podařilo zjistit, je následující:
- .
- Některý obsah na blogu Senuto je duplicitní (týkají se stejné věci)
- Využili jsme pouze 1 % celkového potenciálu, který články mají.
- Duplikací je hodně.
- Na mnoha místech je třeba články doplnit o další klíčové fráze (to vím z analýzy mezer mezi klíčovými slovy).
- Velké množství článků má méně než 10 interních odkazů – na tom budeme muset zapracovat.
.
.
.
Pokud by takový audit u klienta přistál, potřebovali bychom další soubor ve formátu .pdf s popisem jednotlivých informací nebo seznamem úkolů, které je třeba splnit. Do souboru bychom mohli vytáhnout další informace, například nadpisy konkurentů, jejich značky nadpisů atd. U toho se však zastavíme. Mým cílem bylo představit pracovní postup, který lze použít. Ve společnosti Senuto pracujeme na takových nástrojích, které budou tento pracovní postup podporovat, abyste mohli obsahové audity vytvářet co nejdříve.