Robert Głowacki
Robert Głowacki What is an SEO website audit and how to perform it? Together with a content plan and a strategy for organic visibility, this document (or a set of documents) forms the cornerstone of your SEO activity. Implementing it well will put you on a road to success.
With that in mind, we decided to guide you through the process of performing an SEO audit step by step.
An SEO audit is a set of analyses performed by an SEO specialist. It aims to ensure that the site meets the latest search engine optimization standards and that nothing stands in the way of pursuing a strategy for organic growth.
Importantly, an audit in itself is not a strategy. At the beginning of cooperation, we usually provide the client with both documents at the same time. Yet, most audits don’t include keywords analysis or a content plan (exceptions exist).
If the site contains no fundamental errors, even the most thorough audit will reveal only a couple of wrinkles to iron out. It’s the best-case scenario because it means you can launch our SEO strategy right away instead of implementing audit recommendations, which would generate additional costs for the client. In a way, SEO experts are like doctors – all you wish them to say is “everything is fine”.
An SEO expert can give a general assessment of the website’s health even at the quotation stage. This preliminary diagnosis serves to tailor the audit offer and the scope of analysis to the client’s needs.
When to perform an SEO audit? 4 situations when your need one
As you implement any technical updates
An SEO expert should look into any plans for major updates before implementation. “Major” updates include:
- transferring to another CMS (content management system),
- updating HTML code,
- changing URLs or internal site structure,
- adding or removing specific sections, pages, or features.
Do you know what is the most common killer of organic growth in Google? Not algorithm tweaks but major updates implemented without SEO support or analysis.
For this reason, an SEO agency or expert should participate in web design projects right from the start. If you’re on board from day one, you can ensure that the site structure itself fuels your SEO strategy.
For organic visibility issues
If your SEO efforts are at a standstill, random traffic drops or a visibility plateau are to be expected. However, during an active campaign, the lack of results is a reason for concern.
A sudden drop in organic traffic may indicate errors on the website or an update in the Google algorithm that altered the evaluation of the existing content. In both cases, you may require an SEO audit aimed to identify the issues that need fixing or to adjust the website to the new evaluation criteria used by search engine robots.
If there is an active content marketing and/or link building strategy in place, a stagnation may suggest the presence of undetected errors which effectively stunt your growth.
When partnering with a new SEO agency
An SEO audit is standard procedure at the beginning of cooperation with any agency or expert specializing in SEO. To effectively run our strategy, we need to know that the website is in good working order.
Clients tend to object to this idea, arguing that a modern website cannot contain any errors or that an SEO audit was performed by the former agency the year before.
However, as a specialist who assumes responsibility for the new project and its results, you have every right to inspect the website as you see fit.
As a routine
Even if you performed the main SEO audit some time ago, and there have been no major changes in the meantime, it is best to run periodical checks. They don’t have to take the form of full-scale technical audits from the ground up. Depending on the selected methods, routine audits involve:
- monthly or quarterly reviews based on errors spotted during the initial audit,
- analyses focused on core issues such as the new 404 errors.
Thus, a routine audit aims to check if nothing went wrong since the last inspection. As we know, any website is a living thing – pages come and go, or they change location. Medium-sized online stores tend to be managed by several people at the company, and there’s always room for human error.
Types of SEO audits
A full technical SEO audit
When speaking of an SEO audit, we mostly mean the full-scale, technical inspection aimed to reveal all potential optimization errors and imperfections. These audits focus on the website itself, covering the on-site and off-site perspectives. The findings are presented in an SEO report drafted by an SEO expert who gathers data with the use of selected tools, analyzes the results, and offers recommendations adjusted to the client’s product.
Automatic SEO audits
Automatic audits may be grouped into two categories:
- in-depth PDF reports generated by modern and specialized crawlers such as Sitebulb;
- website audits performed automatically by free-of-charge tools.
Reports of both types have their uses. However, while the former type facilitates the work of a seasoned expert, the other usually amounts to a hasty analysis of some basic data, which is not enough to draw any broader set of conclusions.
Reports of the second type are generally available as a free-of-charge client incentive.
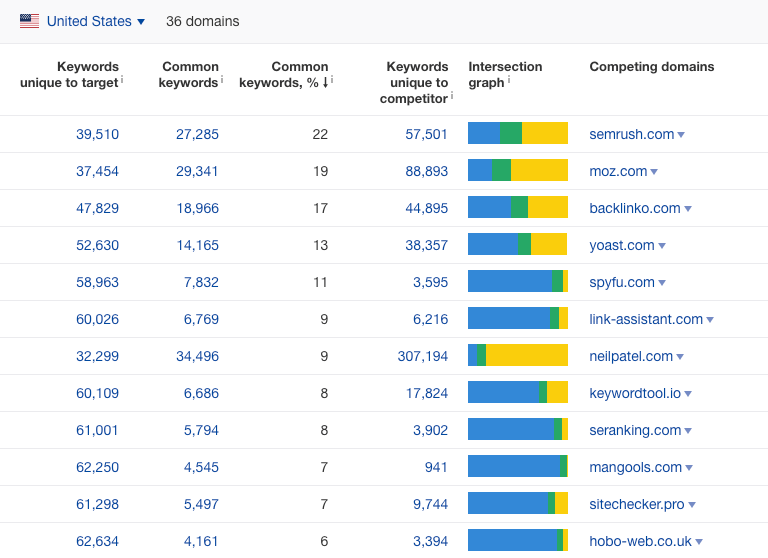
SEO competition audits – benchmarking
Something else entirely is an SEO competition audit, usually performed as we start to develop your SEO strategy. It combines visibility analysis of your competition with a short technical & content audit of selected rivals.
This audit provides:
- your current benchmark against the competition. The audit shows you how your site ranks in Google visibility in comparison with your rivals. You may update the audit every quarter to determine how your strategy is affecting your market position.
- a cornucopia of knowledge on the path of our competitors to their present-day position and results.
You can use the audit to:
- get a peek of optimization solutions that go beyond standard recommendations,
- come up with new ideas for link building,
- and, importantly, define the content gap, which may show you a new pathway to organic growth – something you have missed that generates a lot of traffic for the competition.
Post-implementation audits
After the first audit, the client may involve you in implementing the recommendations (which simplifies things) or take it upon themselves. In the latter case, it’s best to wrap-up the whole procedure with one final inspection when you go through the checklist point by point. Just to make sure that everything is fine.
E-commerce audits
Firstly, an e-commerce audit zeroes in on website architecture, including main navigation, categories, and subcategories. Consequently, technical audits for online stores often require the addition of a keyword use strategy.
Secondly, the audit should look into pagination and the whole site structure because many e-commerce software developers regard the notorious use of rel=canonical and robots noindex as a cure for all ills. The upshot: online stores with 1000 SKU (stock-keeping units) which generate more than a million redundant pages.
Thirdly, the focus should fall on eliminating duplicate content – both internal (repeated over multiple product options) and external (across different stores).
Content audits
Content audits (not to be confused with a growth strategy or a content plan) focus on maximizing organic traffic with the use of existing resources. They may involve the analyses of:
- Current condition of internal linking within the domain – the goal: determine if all your contents topically link to each other, and if that one lonely link in the category tab is not the only way to discover a high-value article.
- Potential problems with keyword cannibalization or situations when a single topic is needlessly split into a few separate articles, none of which stands a chance of getting a top rank.
- Identification of the low-hanging fruit, that is the content that requires only cosmetic changes (linking, reoptimization) to start generating organic traffic.
Only when everything is in good working order, should you proceed with creating new content and further growth.
SEO audit of a local service
Companies operating locally tend to use smaller websites, where site structure and information architecture are of secondary importance.
The priority here is a suitable (local) keyword analysis, which will serve as a foundation for planning offer pages. Besides, the focus falls on:
- reviewing and optimizing the company profile at Google My Business,
- adding or optimizing the Local Business structured data,
- auditing external linking and the NAP factor (Name + Address + Phone Number).
Is a free-of-charge SEO audit worth it?
Free-of-charge SEO audits available on the Internet usually serve one purpose only – to reveal a host of (often irrelevant) errors in order to offer paid services in the end.
Note that these audits tend to be automatically generated by digital tools rather than drafted by SEO experts.
Oftentimes, an SEO audit has to be completed by several people specializing in technical matters or content optimization.
In some cases, audit scope, site size, or deadline require the involvement of a whole team employed by an SEO agency.
Thus, there is no such thing as a trustworthy free-of-charge SEO audit of any website.
How to begin your SEO audit
The first thing I do when performing an audit (or earlier, as I get the enquiry from a client) is to:
- check the organic visibility chart in Senuto
- use the search operator site:
It takes the total of five minutes and often lets me identify many issues on the website.
Remember that at the quotation stage (and, in some cases, even when performing the audit), you may not have access to Google Search Console or Analytics, so external tools are a must.
Just a peek into the site’s visibility chart in Senuto gives you a wealth of information on the website’s wellbeing. On closer inspection, focus on the following points:
- Graph direction – to see if the visibility has been growing steadily over the last couple of years, with no sudden spikes and drops. If the chart looks flat, it usually suggests the lack of organic activity or major issues that impede growth.
- If you notice any sudden drops in a short timeframe, try:
- comparing the anomalies against the list of major known algorithm updates in Google Search. If they overlap, at least you know what you’re up against.
- using the WayBackMachine to see what the site looked like a month before and after the drop. In most cases, visibility plummets after migrations completed without the support of an SEO expert.
Another good call is to use the commonly overlooked site:domain.com operator. Click through the first few results to:
- make a rough estimate of site size – even though you should go to Google Search Console + your selected crawler for the most accurate data,
- see the general quality of title tags, meta description tags, and the presentation of results.
- frequently: find fundamental errors such as site hacking or indexation issues.
Case in point:
A client who has been running his business for years has noticed a slump in the number of orders and new enquiries from the company website. With the site:domain.pl command, the mystery was solved instantaneously:

Key points to check during an SEO audit
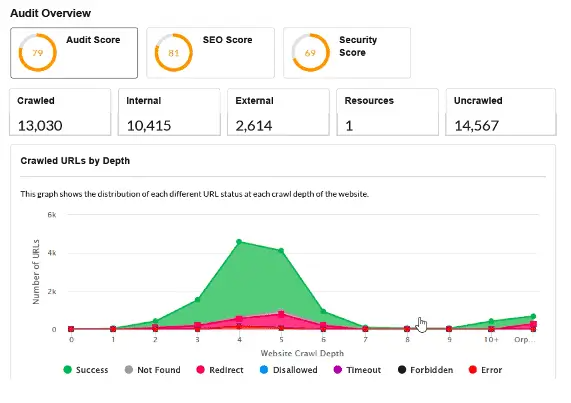
In the world of technical analysis, the focus has shifted from individual tags such as Hx headers to more global issues: site architecture, structure, or rendering (which results, among other things, from Google’s increasing prowess in handling various site types and technologies).
The biggest challenges in creating a unique guide on SEO audits include:
- The huge variety of situations and sites to inspect during an audit. Different goals, types, and CMSs generate a myriad of possible configurations.
- The resulting differences in the weight of detected issues and their potential solutions.
Theoretically, I could draft a separate list of best optimization practices and common mistakes for every CMS and e-commerce system. With that in mind, it would be probably more accurate to call the list below – backed by my expertise from dozens of audits – something along the lines of: Fantastic SEO Errors and Where to Find Them.
Crawling and indexation
Robots.txt
The robots.txt file manages the locations on site which you want to hide from search engine robots. It serves to block crawling rather than the indexation itself. These days, robots.txt files rarely contain errors, but it can really hurt when they do.
An XML sitemap
An XML sitemap is a file or a set of files containing a list of all pages that you want to have indexed in a given structure.
You can locate the sitemap at any address. However, it must present data in the XML format, compliant with the specification.
Basic mistakes relating to XML sitemaps include:
- the lack of an XML sitemap,
- syntax errors (reported in GSC), which prevent Google from retrieving the sitemap,
- incompatibility of the sitemap and website structure,
- failure to include files such as graphics and videos in the sitemap.
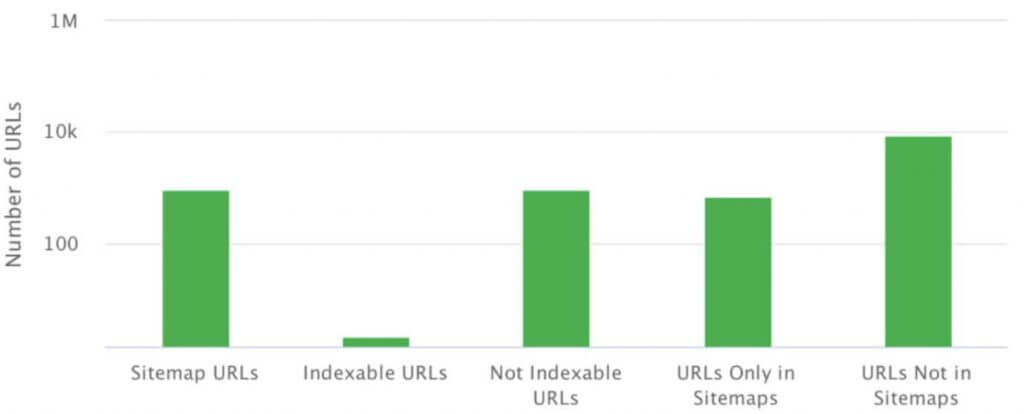
Orphan pages
Orphan pages are not linked to internally, but they often render correctly and respond with a 200 status code. They show up in Google Search Console, and sometimes even climb up the ranks and generate traffic.
Orphan pages crop up for many reasons, starting from CMS errors and ending with human errors in internal or external linking.
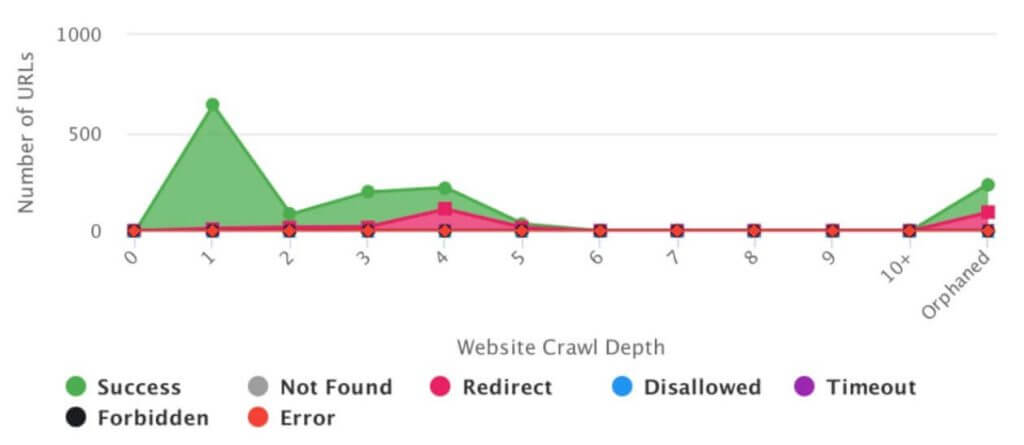
Rel=canonical
Rel=canonical is not a problem when used as intended – to reference the original page address in the event of internal duplication. However, it is often mistaken for a panacea for all troublesome pages and poorly planned structures.

Internal 404 errors
Anytime we detect internal 404 errors in live site structure, that is in our current crawl, their correction should be our priority. Such errors imply that our website contains links to pages which no longer exist, which is undesirable for users and bots alike. However, in most cases, the crawl is clean, but GSC reveals tons of 404.
Generally, this suggests one of the problems listed above: errors in site structure, a faulty XML sitemap referencing non-existent pages, or echoes of a mishandled migration with wrong redirects.
Alas, these mistakes are sometimes slowly indexed by Google. However, if they are relatively fresh, we should inspect the situation to see why they occur. If a fresh crawl of the site is clean, we must decide how to best rectify the errors detected in GSC. Usually, the optimal solution is to redirect visitors to the closest thematic equivalent of the problematic content.
Website architecture analysis
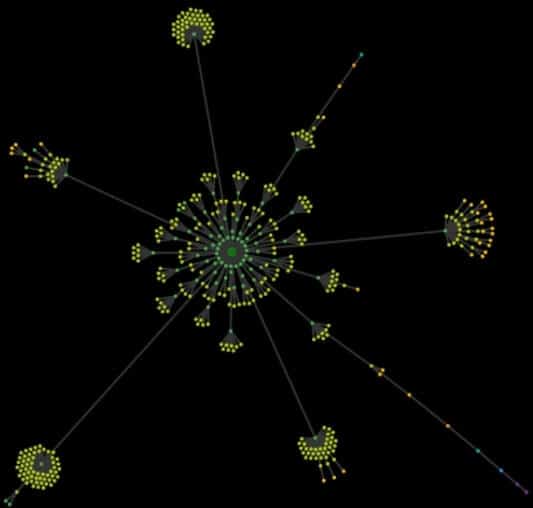
With no way to visualize the actual look of the website, all you have is a cryptic Excel with thousands of URLs. The analysis of site architecture (the so-called crawl map) lets you detect mistakes and bottlenecks of the site structure in an instant.
In general, a crawl map is a visualization of all the URLs found on the website, starting with the homepage. The principle is simple: if what you see at first glance is perfect order and harmonious “flowers” of the structure without bottlenecks, things aren’t bad. The more chaotic the map, the more you need to ponder over the roots of the problems.
The image below shows a crawl map of a content website. In terms of SEO, its structure was planned properly right from the start, with an SEO specialist watching over the entire process. At first glance, you see order, harmony, clearly divided sections and categories, and correct linking.
The image below shows a crawl map of a content website developed for years. New sections were added and expanded without much forethought. At some point, the client asked for help, saying that they are getting lost on their own website. The map revealed total chaos, so the structure needed to be replanned from scratch.

As an extra, I add a crawl map of a small local page made up of several offer pages and a dozen of news items. The two odd and surprising “tails” are the product of calendar extensions, which generated new redundant but indexable pages at a crawl depth up to over 50 clicks from the homepage.
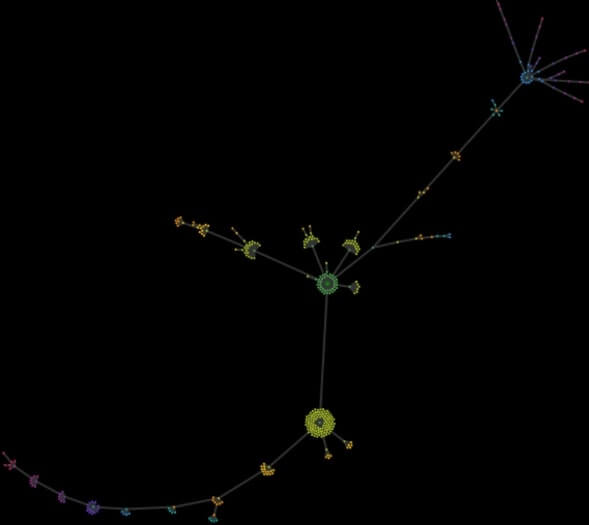
On-site factors
Meta title
Use it to your advantage and enhance your page titles with keywords in line with your strategy. Besides, page titles impact website clickability in search results.
The most common mistakes relating to titles include:
- creating titles that aren’t based on keyword research and the strategy of organic visibility,
- the lack of a global title schema, for instance: [a component unique for the page] – [a regular component/name/brand],
- duplicate titles within the site – often indicating duplicate content.
We often say that titles should be around 65-75 characters long (depending on letter width). However, in practice, it’s more important whether they contain our targeted keywords.
Meta description
The content of meta description tags is not subject to evaluation by the algorithm. Still, its proper construction enhances website appearance in search results, which translates to better clickability of the listing.
The most common mistakes relating to meta description include:
- the lack of meta description,
- duplicate descriptions within the site (which may indicate duplicate content like duplicate titles),
- excessive length of the descriptions.
Ideally, every page aimed to generate search engine traffic should have its own meta description with a call-to-action. Yet, this often proves unrealistic. In many cases such as online stores, we can create unique meta descriptions for core pages and categories, whereas for product pages – generate meta descriptions from a template filled with product features.
Hx header hierarchy
We all have a sense of what a proper header hierarchy looks like. Yet, during SEO audits, we routinely encounter H1 headers with a logo.
The impact of Hx headers on the ranks is highly debatable, especially in the HTML5 era. However, using them is still standard practice in the world of SEO.
Accordingly, you should have only one H1 header per page. It should contain the main title plus important keywords.
The number of other headers doesn’t matter, as long as you stick to the principles of priority and nesting (H3 inside H2) etc.
During SEO audits, header issues usually drop down to the bottom of the priority list.
JavaScript
In most cases, the use of JavaScript is natural and does not interfere with indexation or rendering, which is Google’s strong suit. However, in a small percentage of cases, it causes errors critical to site visibility.
As a rule, all you need to do is check if the site requires an extra action (usually a click) to display additional content generated by JavaScript. If it does, chances are that GoogleBot won’t perform this action.
A simple and effective method to check that is to run two crawls, one after another, with your preferred tool. The first crawl should analyze only HTML, with the Chrome engine switched off. The other should include JavaScript, with the Chrome engine switched on.
A comparison between two crawls will reveal differences in the structure, linking, and the content of both versions. The differences themselves are not a problem – if the tool with the rendering switched on can crawl the website, Google will probably manage, too.
Additionally, it’s a good idea to click through the core pages of the website and observe in Chrome DevTools what extra resources get loaded, if any. Focus your attention on key elements, such as the menu, internal linking, and content implementation.
Structured data / rich snippets
On most websites, structured data are used automatically, which is a plus. However, they may still generate problems discussed below:
- The lack of structured data.
- The use of formats reduced to the bare minimum (a frequent scenario). Most formats offer required and optional content fields to fill out. Yet, e-commerce systems often limit data included in the Product format to the required information.
- The failure to tag breadcrumbs navigation – a simple and useful tool which may enhance the appearance of your listing in search results.
- Limited use of structured data. Currently, Google offers a gallery of 31 supported formats – including logos, local formats, articles – to use and combine in a myriad of ways.
User experience factors
Page load speed
There’s no denying that page load speed matters. Suffice it to say that Google itself no longer speaks of speed alone, replacing it with “Core Web Vitals” to be included in the core algorithm in 2021.
Currently, the key parameters to consider are:
LCP – Largest Contentful Paint – assessing the load speed of main content,
FID – First Input Delay – assessing the speed of site response to user actions,
CLS – Cumulative Layout Shift – assessing sudden changes in site layout upon loading.
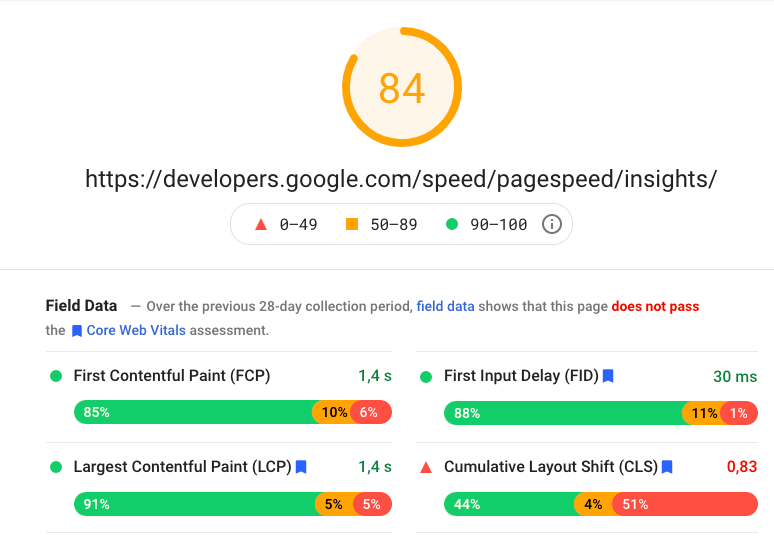
Our toolkit includes mainly Google products: data from GSC and PageSpeed Insights. Both are imperfect, they have to serve us as the main source of analysis, to be completed with a selected tool when need be.
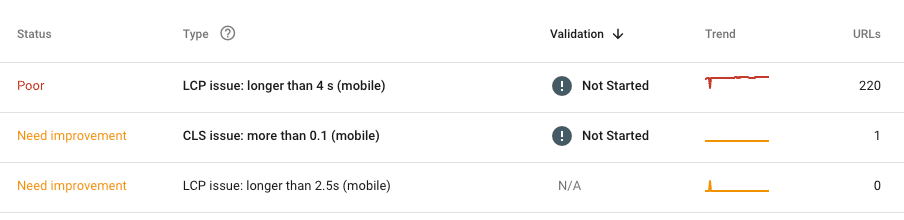
Important!
Never evaluate website speed only on the basis of the homepage. It’s the worst thing to include in an audit. Take the approach you know from other analyses – divide the site into similar sections, assuming that the detected errors reappear across the site.
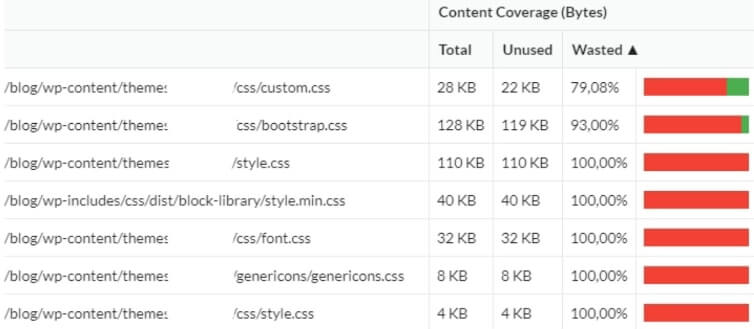
What is now the biggest problem with website speed? At the development stage, the priority is to deliver the website as fast as possible, not to optimize for speed. Consequently, developers often resort to ready-made frameworks (without much forethought). As a result, the owner ends up with dozens of redundant files never to be used. For this reason, complete your SEO audit with an analysis of actual code use during rendering. It often turns out that even ¾ of the code is left unused
Mobile optimization
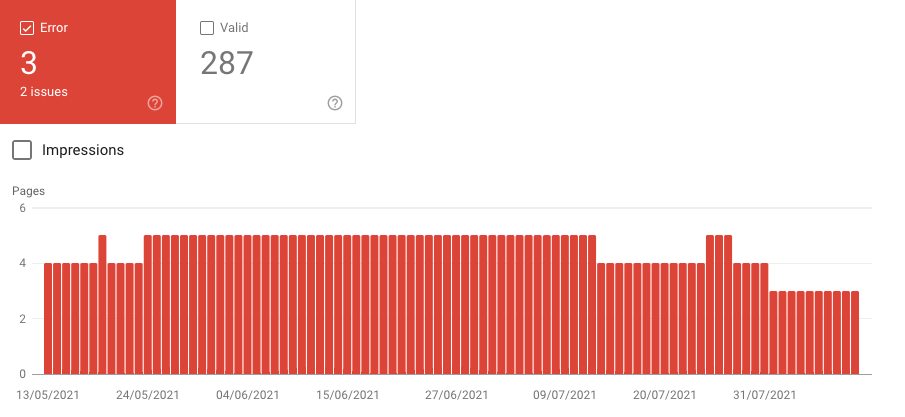
In modern times, we rarely audit sites that are completely unresponsive. Most sites are fully adapted for mobile devices – which does not necessarily imply the application of the mobile-first philosophy.
Over the last 2 years, I haven’t encountered a website that would be unresponsive from start to finish. However, the devil is in the details (just like in the case of speed-related errors), so pay attention to isolated errors such as the pages where GSC or crawler detect mobile optimization issues. In most cases, they result from human errors (again, just like speed-related errors) or from the attempts to casually toss new features, not included in the original plan, into the main website and CMS.
Content analysis
In SEO, website content includes all content outside the boilerplate area, that is the fixed elements of the source code.
Duplication
In most cases, internal duplicate content is the product of:
Errors in website design (features and structure)
Example:
A financial institution offered services for individual clients, entrepreneurs, and large businesses. Navigation based on the type of offer that the client was interested in. Upon making their choice, users were redirected to one of three dedicated sections:
https://domain.pl/individual-clients/
https://domain.pl/entrepreneur/
The client could browse through the dedicated offer, but the first part of the URL remained unchanged. Unfortunately, the content of all three offers overlapped in 90%. Thus, the website created 3 almost interchangeable structures with the same content. It’s one of the errors caused by the lack of SEO support at the design stage. Due to internal regulations of the client, the problem proved virtually impossible to fix. The only solution was to launch a new website one year after the audit.
Human errors or development errors
Example:
A client had the same content in the footer and the main menu. The solution, which generally shouldn’t be a problem, caused quite a hassle. The website comprised around 20 pages, but a simple mistake in internal linking caused the footer to multiply the website to infinity. Every link in the footer generated an additional component in the footer’s URL. As a result, the client ended up with addresses such as:
https://domain.pl/history/ history/history/contact/rules/history/contact/contact/
Type of website
Example:
Alas, internal (and external) content duplication is routine on e-commerce websites. To realize that, imagine a store offering similar products in multiple variants. For instance, smartphones in five colors or clothes in several sizes.
We don’t want to block indexation or use rel=canonical for different variants to keep gaining traffic from the long tail. Yet, this leaves us with duplicate content or near duplicates.
Ideally, we should consider writing unique descriptions for each product. However, where we have many SKU and high product rotation, the only solution is to automatically generate differing product descriptions on the basis of unique product features and their combinations.
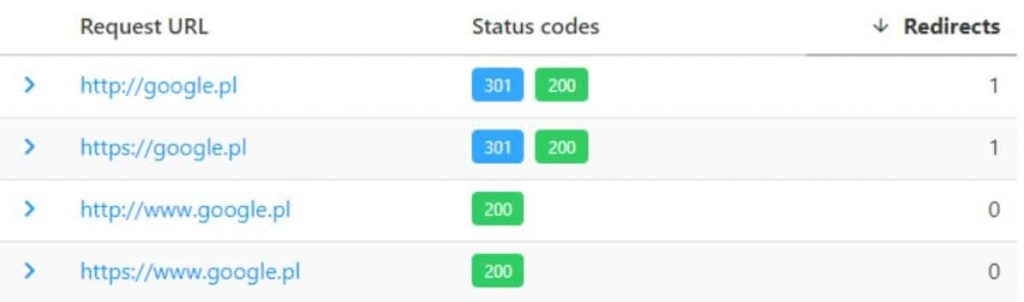
Multiple URL versions and SSL implementation
For years, the analysis of internal duplication issues relied on checking homepage redirects to the versions with(out) www and with(out https. Nowadays, it’s a rare problem. Besides, Google has learnt to deal with it very efficiently.
The most common mistakes related to SSL:
- On sites with hard-coded menu links, the “http” links may remain in places across the site among the new “https”. As a result, we end up with a new layer of redirects within the website.
- The migration to SSL may not include all resources. As a result, elements such as graphics or scripts may still load from the “http” version.
Internal linking
Internal linking affects crawling, indexation, and the visibility of each page, as links give internal power/authority to their target locations. The analysis of internal linking is a set of separate checks concerning:
Permanent linking, particularly the main navigation menu, should be planned together with the keyword use strategy. When creating main linking, simplicity is key – don’t overthink, because a clean HTML code always works best.
When we compare our strategy against reality and establish that the main menu contains all the necessary elements, let’s check for permanent but redundant internal links across the site. You can often spot them in the footer, the usual container for just about anything. It’s worth the effort because every new redundant link disturbs the internal flow of power.
Some links and pages, such as rules and regulations or privacy policy, are a must. However, others are disposable. For instance, are you certain that every shipping method needs a separate link in the footer, leading to a separate page? They’ll all fit on one. Apart from the required links, let’s organize our internal linking to avoid redundant links to pages which won’t rank for our key phrases.
Automatic linking – suggested posts/products
Automatic linking means linking to suggested posts (on blogs) or suggested products (on e-commerce sites). Generally, if these mechanisms are managed by ready-made solutions embedded in the CMS (WordPress), everything should run smoothly. If the links are generated in clean HTML that forms part of the source code, all we may need is a little optimization. Alas, these features often use dynamic solutions based on JavaScript (Case Onely+H&M) or, even worse, the solutions of external companies included as scripts from other domains.
Individual linking between pages used mainly in content sections
Contextual linking across articles underpins the growth of content section visibility. Yet, it’s often overlooked. As a result, the only links pointing to the articles are those from category pages.
A contextual linking analysis is relatively simple. All you need to do is mix crawl data on internal linking with information on the current organic traffic (GSC/Analytics). Besides, you may include data on the external inbound links to determine which articles have the greatest authority. Add data on seed keyword visibility (Senuto) to see what areas need your attention and how to fix them.
External linking
Link profile analysis
Luckily, poor link profiles are increasingly rare, even though you can still encounter links made with GSA, Xrummer, or another automatic generator.
In the vast majority of cases, trashy links are:
- the memento of SEO efforts made by specialists from a few years back
- the signal that the site was hacked to upload SPAM, which was then linked by the hacker
- the product of scrapers and SPAM generators which download site content.
When inspecting the link profile, apply the universal golden rule – focus on anomalies.
It’s easiest to spot them on backlink growth charts. All sudden spikes and drops are up for analysis.
Deep linking distribution
SEO analysis of link distribution across the homepage and other pages of the website serves to assess the quality of the so-called deep linking and thus pinpoint the sections or pages with the highest external authority. This tells us whether our link distribution is even, and which pages could be important nodes in the structure and serve as power distributors for internal linking.
Outbound links
A frequently neglected matter is the analysis of the website’s outbound links. When you’re inspecting a website based on content or user-generated content, it surely includes several dozen links to external domains. Over the years, many of them expire, change hands, or go to harmful websites. Repeat your outbound link analysis – with a crawler or an external tool – at least once a year.
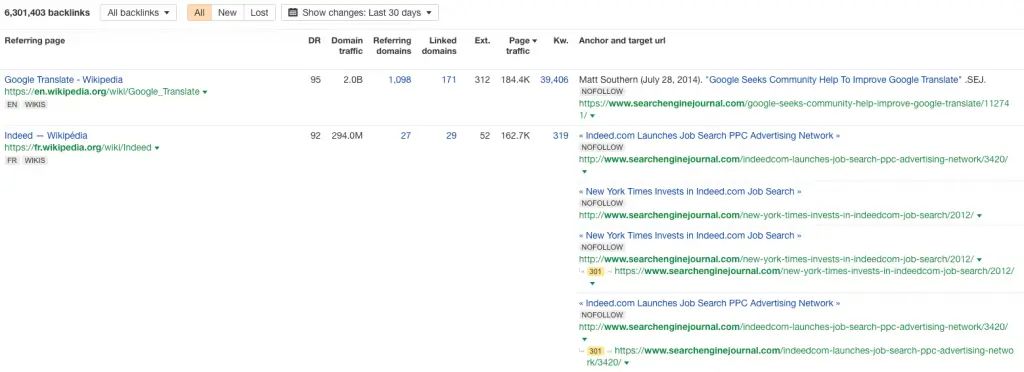
Broken & lost backlinks
Broken backlinks are your inbound links which point to the 404 error page and come to be ignored by Google. As your website grows, broken backlinks appear naturally – pages change location, some get deleted, and people make mistakes when linking our content. Broken backlinks are also a standard consequence of mishandled migrations, where the developers forgot about the redirects, and the website not only changed its structure but also lost all the links except the homepage within a day.
All the lost backlinks should be grouped together and redirected to the thematically related page. As a last resort, we may redirect them to another location on the website or the homepage. It is the only way to reclaim the authority they garnered for our domain. While you’re at it, review the linking domains – if possible, redirect only quality links, and let the spam point to 404.