Dlaczego powinniśmy zadbać o plik robots.txt na stronie internetowej

Niepozorny plik robots.txt pozwala kontrolować dostęp robotów wyszukiwarki do strony internetowej. Z tego powodu odgrywa zasadniczą rolę w pozycjonowaniu i warto poświęcić mu należytą uwagę, szczególnie w bardziej zaawansowanych działaniach SEO. W tym artykule omówimy, czym jest plik robots.txt, czemu służy i dlaczego jest ważny, a następnie przejdziemy do przykładowych reguł oraz instrukcji, jak samodzielnie stworzyć taki plik.
Co to jest jest plik robots.txt i po co się go stosuje?
Plik o dokładnej nazwie robots.txt jest zwykłym plikiem tekstowym – zapisanym w formacie .txt i umieszczonym bezpośrednio w folderze głównym domeny.
Wewnątrz pliku umieszczamy wytyczne dla robotów, które odwiedzają naszą stronę internetową.
W tych wytycznych określamy, które ze stron z domeny głównej mogą być odwiedzane przez roboty, a których możliwość odwiedzenia blokujemy.
Warto zauważyć, że roboty mogą ominąć dyrektywy umieszczone w pliku robots.txt i mimo to odpytywać strony czy sekcje tam umieszczone.
Dlaczego plik robots.txt jest ważny?
Znaczenie pliku robots.txt możemy poznać po tym, jak robot Google skanuje strony.
Kiedy robot Google natrafi na Twoją stronę podlinkowaną z innej domeny, znajdującej się już w jego indeksie, od razu sprawdza Twój plik robots.txt w celu zweryfikowania, które zasoby w serwisie może odwiedzić. Następnie regularnie odwiedza ten plik w celu sprawdzenia, czy nic w wytycznych się nie zmieniło.
Analizując logi serwisów możemy zauważyć, że plik robots.txt nawet w małych stronach internetowych odwiedzany jest kilkanaście czy kilkadziesiąt razy miesięcznie.
Poza wymienioną już możliwością blokowania dostępu robotom do określonych miejsc na stronie, plik robots.txt wykorzystujemy do podlinkowania adresu URL mapy strony w formacie XML. Podlinkowanie mapy strony w tym miejscu ma szczególne znaczenie gdy nie posiadamy profilu w Google Search Console oraz gdy nasza mapa strony ma nieszablonowy adres URL.
Warto zwrócić też uwagę, jak skrupulatnie Google wypełnia swój plik robots.txt, który znajdziemy pod adresem URLhttps://www.google.com/robots.txt.
Przykładowe reguły w robots.txt. Z jakich grup i dyrektyw zbudowany jest taki plik?
Każdy plik robots.txt zbudowany jest z grup. W skład grupy wytycznych wchodzą:
-
odwołanie do nazwy bota,
Każda aplikacja, czy użytkownik odwiedzający stronę przedstawia się swoją nazwą klienta lub inaczej nazwą robota. To właśnie tą nazwę umieszczamy w dyrektywach wewnątrz pliku w dyrektywie User-agent.
-
informacje, które zasoby są wykluczone lub dozwolone do odwiedzania przez wskazanego bota.
Takie grupy umożliwiają nam przede wszystkim:
-
Wybranie nazwy robota do którego chcemy kierować dyrektywy.
User-agent: AdsBot-Google -
Dodanie dyrektyw blokujących dostęp do określonych katalogów lub adresów URL.
Disallow: /maps/api/js/ -
Dodanie dyrektyw zezwalających na dostęp do określonych katalogów lub adresów URL.
Allow: /maps/api/js
Każda następna grupa może zawierać kolejną nazwę robota i dyrektywy dotyczące innego robota, przykładowo:
User-agent: Twitterbot
Allow: /imgresPodsumowując, otrzymujemy zestaw grup:
User-agent: AdsBot-Google
Disallow: /maps/api/js/
Allow: /maps/api/js
Disallow: /maps/api/place/js/
Disallow: /maps/api/staticmap
Disallow: /maps/api/streetview
User-agent: Twitterbot
Allow: /imgresNależy jednak pamiętać, że wiersze wewnątrz grupy przetwarzane są od góry do dołu, a klient użytkownika (w tym przypadku: nazwa robota) jest dopasowywany do wyłącznie jednego zestawu reguł, a dokładniej do pierwszej najmocniej sprecyzowanej reguły, która się do niego odnosi.
Sama w sobie kolejność grup w pliku nie ma znaczenia. Warte uwagi jest również to, że roboty rozróżniają wielkość liter. Na przykład reguła:
Disallow: /file.aspma zastosowanie do podstrony http://www.example.com/file.asp, ale do podstrony http://www.example.com/FILE.asp – już nie.
Nie powinno jednak sprawić to problemów w sytuacji, gdy poprawnie tworzymy adresy URL w naszej domenie.
Na koniec, jeżeli dla jednego robota istnieje więcej niż jedna grupa, to dyrektywy z powielonych grup są łączone w jedną grupę.
User-Agent
Do nazwy każdego robota dopasowywana jest tylko jedna z grup umieszczonych w pliku robots.txt, a pozostałe są ignorowane. Dlatego robot o nazwie Senuto, widząc w pliku robots.txt domeny reguły:
User-agent: *
disallow: /search/
User-agent: Senuto
allow: /search/wybierze regułę umieszczoną niżej (w przykładzie) i uzyska dostęp do katalogu /search/, ponieważ jest ona precyzyjnie do niego skierowana.
Disallow
Dyrektywa disallow precyzuje, do których katalogów, ścieżek lub adresów URL wybrane roboty nie mogą uzyskiwać dostępu.
disallow: [ścieżka]disallow: [adres-URL]Dyrektywa jest ignorowana, jeżeli nie zostanie wypełniona żadną ścieżką lub katalogiem.
disallow:Przykład zastosowania dyrektywy:
disallow: /searchPowyższa dyrektywa zablokuje dostęp do adresów URL:
- https://www.domena.pl/search/
- https://www.domena.pl/search/test-site/
- https://www.domena.pl/searches/
Warto zauważyć, że omówiony przykład dotyczy zastosowania wyłącznie jednej reguły dla jednego wskazanego robota.
Allow
Dyrektywa allow precyzuje, do których katalogów, ścieżek lub adresów URL wskazanym robotom wolno uzyskiwać dostęp.
allow: [ścieżka]allow: [adres-URL]Dyrektywa jest ignorowana, jeżeli nie zostanie wypełniona żadną ścieżką lub katalogiem.
allow:Przykład zastosowania dyrektywy:
allow: /imagesPowyższa dyrektywa zezwoli na dostęp do adresów URL:
- https://www.domena.pl/images/
- https://www.domena.pl/images/test-site/
- https://www.domena.pl/images-send/
Warto zauważyć, że omówiony przykład dotyczy zastosowania wyłącznie jednej reguły dla jednego wskazanego robota.
Sitemap
W pliku robots.txt możemy również umieścić link do mapy naszej strony w formacie XML. Ponieważ strona robots.txt jest odwiedzana regularnie przez robota Google oraz jest to jedna z pierwszych podstron w serwisie, do których ma on dostęp, to umieszczenie w niej linka do mapy strony jest mocno uzasadnione.
sitemap: [bezwzledny-adres-URL]Wytyczne Google informują, że adres URL mapy strony powinien być adresem bezwzględnym (pełny, właściwy adres URL), czyli przykładowo:
sitemap: https://www.domena.pl/sitemap.xmlPozostałe dyrektywy
W plikach robots.txt możemy znaleźć również inne dyrektywy, a mianowicie:
- host – dyrektywa host służy do wskazania preferowanej domeny spośród wielu jej kopii dostępnych w internecie.
- crawl delay – w zależności od robota, dyrektywa ta może być wykorzystywana inaczej. W przypadku robota wyszukiwarki Bing czas określony w crawl delay będzie minimalnym czasem pomiędzy pierwszym a drugim odpytaniem jednej podstrony serwisu. Z drugiej strony Yandex odczyta tę dyrektywę jako czas, jaki robot ma odczekać przed odpytaniem każdej kolejnej strony w domenie.
Obydwie te dyrektywy zostaną pominięte przez Google i nie będą uwzględniane podczas skanowania strony.
Czy w regułach możemy wykorzystać wyrażenia regularne?
Roboty wyszukiwarki Google (ale nie tylko) obsługują w ścieżkach pojedyncze znaki ze specjalnymi właściwościami. Do takich znaków należą:
- znak gwiazdki * – oznacza zero lub więcej wystąpień dowolnego znaku,
- znak dolara $ – oznacza koniec adresu URL.
Nie pokrywa się to idealnie z tym, co znamy z wyrażeń regularnych https://pl.wikipedia.org/wiki/Wyrażenie_regularne. Warto zauważyć też, że właściwości znaków * i $ nie są uwzględnione w standardzie Robot Exclusion Standardhttps://en.wikipedia.org/wiki/Robots_exclusion_standard.
Przykładem bezsensownego wykorzystania tych znaków będzie reguła:
disallow: *searches*Przytoczona reguła będzie tożsama z regułą:
disallow: searchesa znaki * zostaną po prostu zignorowane.
Znaki te znajdą na przykład zastosowanie w sytuacji, gdy chcemy zablokować dostęp do stron, w których pomiędzy dwoma folderami w adresie URL mogą wystąpić inne, pojedynczo lub wielokrotnie.
Reguła, która ma zablokować dostęp do stron, które w adresie URL posiadają folder /search/ oraz głębiej w strukturze strony folder /on-demand/, będzie wyglądała następująco:
disallow: /search/*/on-demandDzięki powyższej regule zablokujemy dostęp do tych adresów URL:
- https://www.domena.pl/search/wstawka-w-url/on-demand/wlasciwy-url/
- https://www.domena.pl/search/a/on-demand/,
ale nie zablokujemy dostępu do tych:
- https://www.domena.pl/search/on-demand/
- https://www.domena.pl/on-demand/
- https://www.domena.pl/search/adres-url/
Interesującym przykładem może być zablokowanie dostępu do wszystkich plików o rozszerzeniu .pdf (zakładamy, że w ten sposób zakończony jest każdy plik o takim rozszerzeniu w naszej domenie), które w adresie URL zawierają folder /dane-klienta/. Posłuży do tego dyrektywa:
disallow: /dane-klienta/*.pdf$Więcej informacji o właściwej składni oraz regułach, które można umieścić w pliku robots.txt, można przeczytać w specyfikacji składni ABNF pod adresem URL:https://datatracker.ietf.org/doc/html/rfc5234
Co powinien zawierać podstawowy plik robots.txt
Aby plik robots.txt został poprawnie odczytany, powinien:
- być plikiem tekstowym w kodowaniu UTF-8,
- mieć nazwę: robots.txt (przykładowy URL https://www.domena.pl/robots.txt),
- być umieszczony bezpośrednio w głównym folderze domeny,
- być unikalny w obrębie domeny – nie powinno się umieszczać więcej niż jednego pliku robots.txt, ponieważ wytyczne w plikach umieszczonych pod adresem URL innym niż wskazany nie zostaną odczytane,
- zawierać minimum jedną grupę dyrektyw wewnątrz pliku
W pliku tym możemy też czasem znaleźć znak #. Umożliwia on dodawanie komentarzy wewnątrz pliku, które nie zostaną odczytane przez robota Google. Po umieszczeniu # w wierszu, każdy znak następujący po tym znaku w tym samym wierszu nie zostanie odczytany przez Google.
disallow: /search/ #żaden ze znaków po "płotku" nie zostanie odczytany przez robota GoogleJak stworzyć plik robots.txt
W tym momencie jesteśmy gotowi, aby samodzielnie utworzyć taki plik. W tym celu będziemy potrzebować dowolnego edytora tekstowego: MS Word, Notatnik itp. W edytorze tworzymy pusty dokument tekstowy i nazywamy go właśnie robots.txt.
Kolejnym krokiem jest uzupełnienie dokumentu tekstowego o właściwe dyrektywy. Przed ich wpisaniem powinniśmy przygotować:
- listę robotów, których dotyczyć mają restrykcje,
- listę robotów, które nie będą podlegać pod restrykcje,
- listę stron, do których dostęp chcemy zablokować,
- listę stron, do których dostępu nie możemy zablokować,
- adres URL mapy strony.
Posiadając powyższe dane, możemy zacząć ręcznie wpisywać reguły jedna pod drugą w utworzonym dokumencie tekstowym. Przykładowy plik robots.txt:
User-agent: *
disallow: /business-card #blokada dostepu do stron w folderze business-card
disallow: /*.pdf$ #blokada dostepu do plików o rozszerzeniu .pdf
disallow: sortby= #blokada dostepu do plikow, ktore posiadaja sortowanie w adresie url
User-agent: wlasnybotsc1
allow: *
sitemap: <https://www.domena.pl/sitemap_product.xml> #link do mapy strony w formacie xml
sitemap: <https://www.domena.pl/sitemap_category.xml>
sitemap: <https://www.domena.pl/sitemap_static.xml>
sitemap: <https://www.domena.pl/sitemap_blog.xml>Tak utworzony dokument musimy umieścić w folderze głównym naszej domeny na serwerze FTP, na którym znajdują się jej pliki. Warto zauważyć, że w systemach zarządzania treścią, takich jak WordPress, znajdziemy wtyczki, które pozwolą nam edytować plik robots.txt znajdujący się na serwerze FTP.
Jak przetestować, czy wytyczne w pliku robots.txt są poprawne?
W celu dokładnego przetestowania, czy utworzony przez nas plik robots.txt będzie działał poprawnie, musimy odwiedzić stronę: https://www.google.com/webmasters/tools/robots-testing-tool
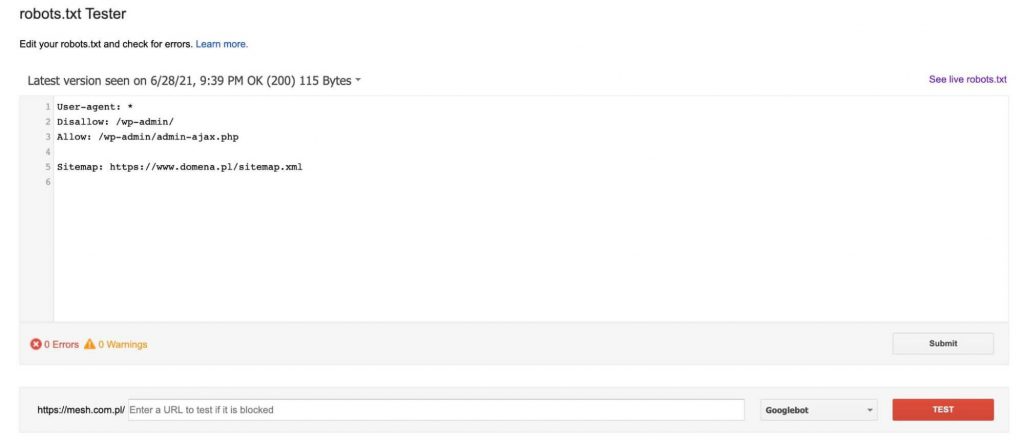
Znajdziemy tutaj tester, który pobierze plik robot.txt obecnie znajdujący się w domenie (musimy być jej zweryfikowanym właścicielem w Google Search Console), a następnie umożliwi jego edycję oraz sprawdzanie, czy wskazane przez nas podstrony zostaną zablokowane lub przepuszczone przez dyrektywy w nim umieszczone.
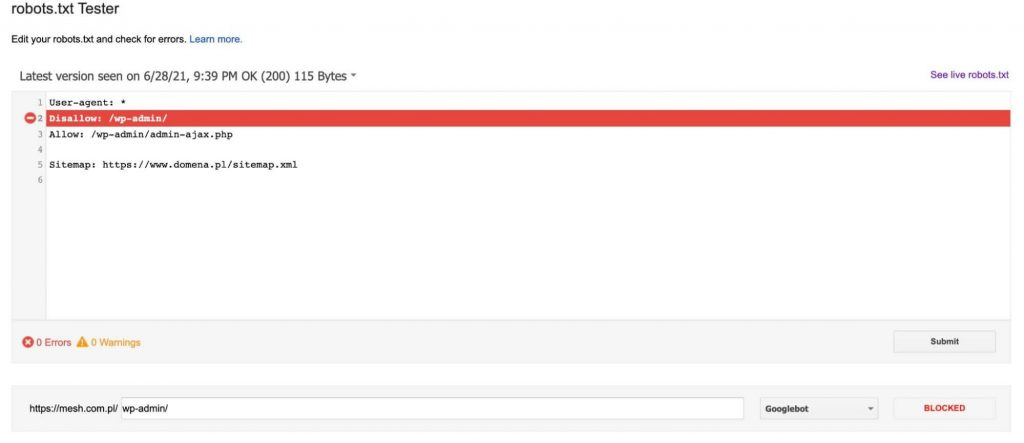
Za każdym razem po dodaniu URL do testu (na dole grafiki) klikamy czerwony przycisk “TEST” i w odpowiedzi dostajemy informację, czy wskazany URL został zablokowany i jeżeli tak się stało, to która linia tekstu w pliku robots.txt zablokowała nasz adres URL.
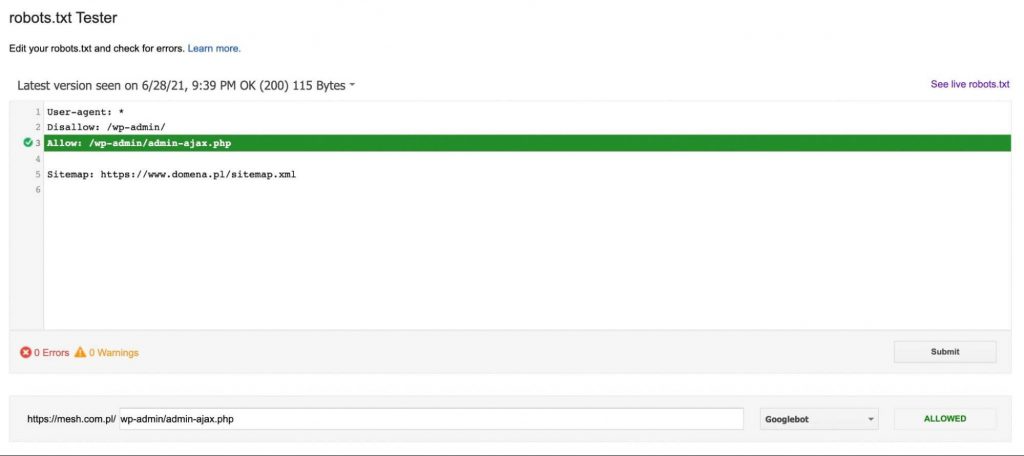
Jeżeli adres URL nie zostanie zablokowany, to dostaniemy informację, dzięki której dyrektywie adres URL jest dostępny dla robota Google – tak jak na poniższej grafice:
Na co zwrócić uwagę, tworząc plik robot.txt?
Podczas tworzenia pliku robots.txt powinniśmy uważać w szczególności na zablokowanie dostępu robota Google do strony, całkowicie lub częściowo. Dlatego wszystkie zmiany w tym pliku powinny być konsultowane ze specjalistą, aby nie zaszkodzić swojej stronie jeszcze bardziej.
Warto zauważyć jednak, że plik robots.txt nie zablokuje robotów przed indeksacją strony. Google dopuszcza możliwość, że jeżeli jego robot dotarł na jedną z naszych podstron z innej domeny, to o ile strona ta zostanie uznana za wartościową, trafi do indeksu.
Istotną informacją jest też fakt, że większość botów nienależących do Google’a nie stosuje się do wytycznych w pliku robots.txt i ignoruje polecenia znajdujące się w nim.
Podsumowanie
Plik robots.txt to zdecydowanie ważny element w technicznym SEO. Złe wypełnienie go grozi ograniczeniem ruchu z SEO, z kolei dobre wypełnienie pomoże zarządzać indeksacją strony i budżetem crawlowania. Im większy wolumen ruchu na stronie, im więcej podstron istnieje w naszym serwisie, tym lepiej zadbać o prawidłowe wypełnienie robots.txt.

Piotr Smargol
Lubi nowe wyzwania i nie boi się zmian. Pracę w branży SEO zaczął w 2018 roku, a pół roku później trafił do Vestigio, gdzie dziś zajmuje się kluczowymi projektami jako Senior SEO Specialist. Prywatnie miłośnik aktywnego spędzania wolnego czasu, w pracy — z lenistwa automatyzuje, co może. Specjalizuje się w technicznym SEO i analizie danych.
Wszystkie artykuły →