 Piotr Smargol
Piotr Smargol The inconspicuous robots.txt file allows you to control search engine robots’ access to your website. For this reason, it plays a crucial role in SEO and is worth giving it due attention, especially in more advanced SEO activities. In this article, we’ll discuss what a robots.txt file is, what it serves and why it’s important, and then we’ll move on to sample rules and instructions on how to create such a file yourself.
What is a robots.txt file and why is it used?
.
The file with the exact name robots.txt is a simple text file – saved in .txt format and placed directly in the root folder of the domain.
Inside the file we place guidelines for robots that visit our website.
In these guidelines, we specify which pages from the domain root can be visited by robots, and which ones we block the possibility of visiting.
It is worth noting that robots can bypass the directives placed in the robots.txt file and still query the pages or sections placed there.
Why is the robots.txt file important?
.
We can know the importance of the robots.txt file by how Google’s robot scans the pages.
When Google’s robot comes across your site linked from another domain already in its index, it immediately checks your robots.txt file to verify which resources on the site it can visit. It then regularly visits that file to see if anything in the guidelines has changed.
Analyzing website logs, we can see that the robots.txt file even in small websites is visited dozens or dozens of times a month.
In addition to the already mentioned possibility of blocking robots’ access to certain places on the site, we use the robots.txt file to sublink the URL of the XML site map. Linking the sitemap here is especially important when we don’t have a profile in Google Search Console and when our sitemap has an out-of-the-box URL.
It is also worth noting how meticulously Google populates its robots.txt file, which can be found at URL https://www.google.com/robots.txt.
Example rules in robots.txt. What groups and directives is such a file made of?
.
Each robots.txt file is built from groups. The group of directives includes:
- reference to the bot name,
Each application or user visiting the site is introduced by its client name, or otherwise known as a bot name. It is this name that we put in the directives inside the file in the User-agent directive. - information about which resources are excluded or allowed to be visited by the indicated bot.
.
Such groups enable us, first of all:
- Select the name of the bot to which we want to direct directives.
User-agent: AdsBot-Google
.
- Add directives to block access to specific directories or URLs.
Disallow: /maps/api/js/
.
- Add directives to allow access to specific directories or URLs.
Allow: /maps/api/js
.
Each subsequent group can contain another robot name and directives for another robot, for example:
User-agent: Twitterbot Allow: /imgres
.
In summary, we get a set of groups:
User-agent: AdsBot-Google Disallow: /maps/api/js/ Allow: /maps/api/js Disallow: /maps/api/place/js/ Disallow: /maps/api/staticmap Disallow: /maps/api/streetview User-agent: Twitterbot Allow: /imgres
Note, however, that the rows inside the group are processed from top to bottom, and the user’s client (in this case: the robot’s name) is matched to only one set of rules, or more precisely to the first most strongly specified rule that applies to it.
In itself, the order of the groups in the file does not matter. It is also noteworthy that robots are case-sensitive. For example, the rule:
Disallow: /file.asp
applies to the subpage http://www.example.com/file.asp, but to the subpage http://www.example.com/FILE.asp – no longer.
However, this should not cause problems if we create URLs correctly in our domain.
Finally, if there is more than one group for one robot, the directives from duplicate groups are merged into one group.
User-Agent
.
Only one of the groups placed in the robots.txt file is matched to the name of each robot, and the others are ignored. Therefore, a robot named Senuto, seeing the rules in the robots.txt file of the domain:
User-agent: * disallow: /search/ User-agent: Senuto allow: /search/
will select the rule below (in the example) and access the /search/ directory, as it is precisely targeted to it.
Disallow
.
The disallow directive specifies which directories, paths or URLs the selected robots cannot access.
disallow: [path]
.
disallow: [address-URL]
.
The directive is ignored if no path or directory is filled in.
disallow:
.
Example of using the directive:
disallow: /search
The above directive will block access to URLs:
- https://www.domena.pl/search/
- https://www.domena.pl/search/test-site/
- https://www.domena.pl/searches/
.
It is worth noting that the example discussed here applies only to the application of a single rule for a single designated robot.
Allow
.
The allow directive specifies which directories, paths or URLs the designated robots are allowed to access.
allow: [path]
.
allow: [address-URL]
The directive is ignored if no path or directory is filled in.
allow:
.
Example of directive usage:
allow: /images
The above directive will allow access to URLs:
- https://www.domena.pl/images/
- https://www.domena.pl/images/test-site/
- https://www.domena.pl/images-send/
.
It is worth noting that the example discussed here applies only to the application of a single rule for a single indicated robot.
Sitemap
.
In the robots.txt file, we can also include a link to map of our site in XML format. Since the robots.txt page is visited regularly by the Google robot and is one of the first pages on the site that it accesses, it makes strong sense to include a link to the sitemap.
sitemap: [unlabeled-address-URL]
.
Google’s guidelines state that the sitemap URL should be absolute (full, proper URL), so for example:
sitemap: https://www.domena.pl/sitemap.xml
Other directives
.
In robots.txt files we can also find other directives, namely:
- host – the host directive is used to indicate the preferred domain among the many copies of it available on the Internet.
- crawl delay – depending on the robot, this directive may be used differently. In the case of the Bing search engine robot, the time specified in crawl delay will be the minimum time between the first and second crawling of one subpage of the site. Yandex, on the other hand, will read this directive as the time the robot has to wait before querying each subsequent page in the domain.
.
Both of these directives will be ignored by Google and will not be taken into account when scanning the site.
Can we use regular expressions in the rules?
.
Google search engine robots (but not only) support single characters with special properties in paths. Such characters include:
- asterisk character * – indicates zero or more occurrences of any character,
- dollar sign $ – denotes the end of the URL.
.
.
This does not coincide perfectly with what we know from regular expressions https://pl.wikipedia.org/wiki/Wyrażenie_regularne. It is also worth noting that the * and $ character properties are not included in the Robot Exclusion Standard https://en.wikipedia.org/wiki/Robots_exclusion_standard.
An example of the nofollow use of these characters would be the rule:
disallow: *searches*
.
The quoted rule will be the same as the rule:
disallow: searches
and the * characters will simply be ignored.
These characters will find use, for example, when you want to block access to pages where there may be other folders between two folders in the URL, either singly or repeatedly.
A rule to block access to pages that have a /search/ folder in the address URL and a /on-demand/ folder deeper in the page structure would look like this:
disallow: /search/*/on-demand
With the above rule, we will block access to these URLs:
- https://www.domena.pl/search/wstawka-w-url/on-demand/wlasciwy-url/
- https://www.domena.pl/search/a/on-demand/,
.
But we will not block access to these:
- https://www.domena.pl/search/on-demand/
- https://www.domena.pl/on-demand/
- https://www.domena.pl/search/adres-url/
An interesting example would be to block access to all files with the extension .pdf (we assume that any file with this extension in our domain is terminated in this way) that contain the /data-client/ folder in the URL. We will use the directive for this:
disallow: /data-client/*.pdf$
You can read more about the proper syntax and rules to include in a robots.txt file in the ABNF syntax specification at URL: https://datatracker.ietf.org/doc/html/rfc5234
What a basic robots.txt file should contain
.
For a robots.txt file to be read correctly, it should:
- be a text file in UTF-8 encoding,
- have the name: robots.txt (sample URL https://www.domena.pl/robots.txt),
- be placed directly in the root folder of the domain,
- be unique within the domain – there should not be more than one robots.txt file, as guidelines in files placed at a URL other than the one indicated will not be read,
- contain a minimum of one group of directives inside the file
.
.
.
.
.
We can also sometimes find the # sign in the file. It allows you to add comments inside the file that will not be read by the Google robot. When you put a # in a line, any character following that character in the same line will not be read by Google.
disallow: /search/ #any of the characters after "fence" will not be read by Google robot
.
How to create a robots.txt file
.
At this point we are ready to create such a file ourselves. To do this, we will need any text editor: MS Word, Notepad, etc. In the editor, we create a blank text document and just call it robots.txt.
The next step is to complete the text document with the correct directives. Before typing them, we should prepare:
- list of robots to be affected by the restrictions,
- list of robots that will not be subject to restrictions,
- list of sites we want to block access to,
- list of sites whose access we cannot block,
- the URL of the sitemap,
.
.
.
.
.
Having the above data, we can start manually typing the rules one under the other in the text document created. Example robots.txt file:
User-agent: * disallow: /business-card #block access to pages in the business-card folder. disallow: /*.pdf$ #block access to files with extension .pdf disallow: sortby= #block access to files that have sorting in the url User-agent: ownbotsc1 allow: * sitemap: <https://www.domena.pl/sitemap_product.xml> #link to xml sitemap sitemap: <https://www.domena.pl/sitemap_category.xml> sitemap: <https://www.domena.pl/sitemap_static.xml> sitemap: <https://www.domena.pl/sitemap_blog.xml>
.
We need to place the document created this way in the root folder of our domain on the FTP server where its files are located. It is worth noting that in content management systems, such as WordPress, we will find plug-ins that will allow us to edit the robots.txt file located on the FTP server.
How to test if the guidelines in the robots.txt file are correct?
.
In order to thoroughly test whether the robots.txt file we have created will work correctly, we need to visit: https://www.google.com/webmasters/tools/robots-testing-tool.
Here we will find a tester that will download the robot.txt file currently on the domain (we must be its verified owner in Google Search Console), and then allow us to edit it and check whether the sub-pages we indicate will be blocked or passed by the directives in it.
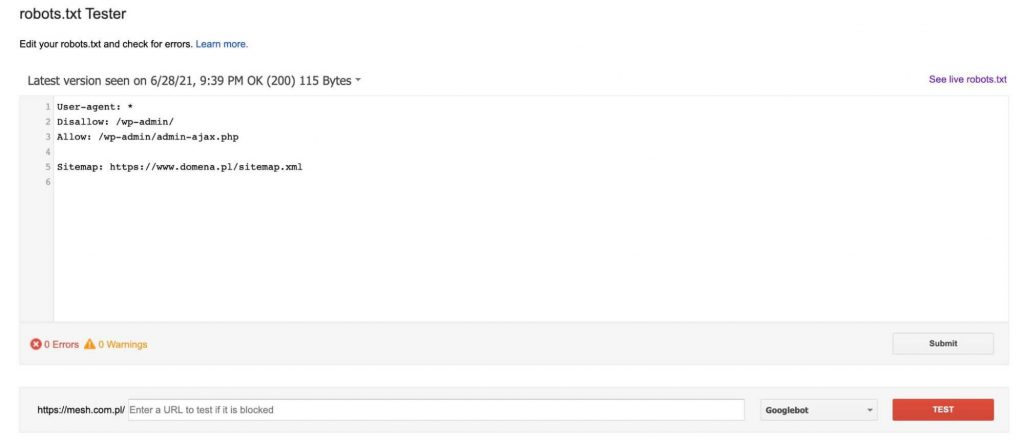
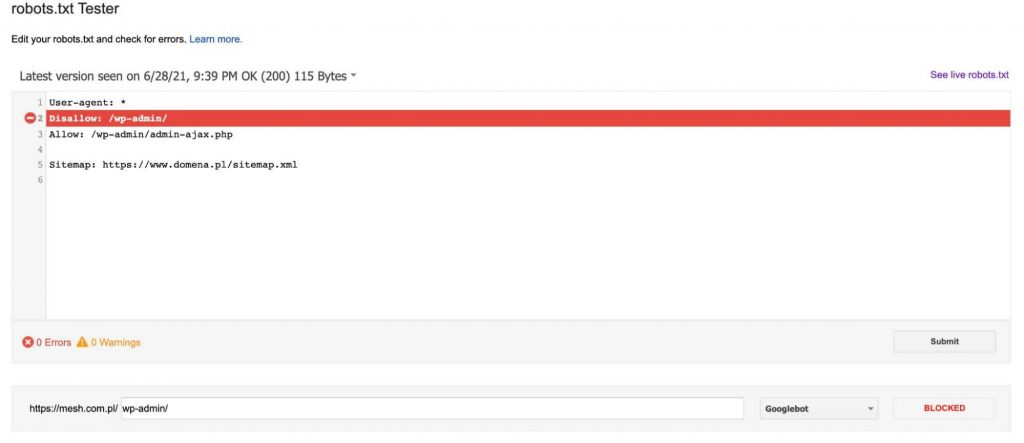
Each time after adding a URL to the test (at the bottom of the graphic), we click the red “TEST” button and in response we get information about whether the indicated URL was blocked and, if it was, which line of text in the robots.txt file blocked our URL.
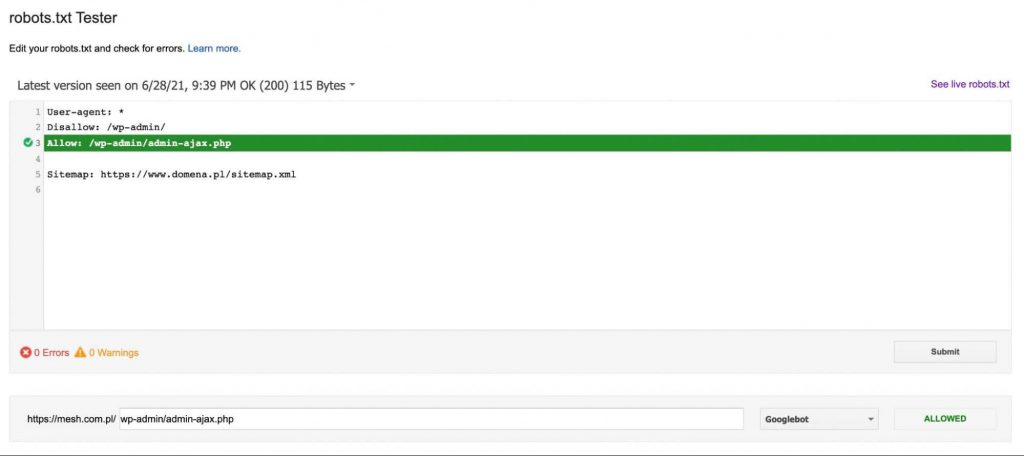
If the URL is not blocked, we will get a message that makes the directive URL accessible to the Google robot – as in the graphic below:
What to pay attention to when creating a robots.txt file?
.
When creating a robots.txt file, we should be particularly careful to block Google’s robot access to the site, either completely or partially. Therefore, all changes to this file should be consulted with a specialist, so as not to harm your site even more.
It is worth noting, however, that the robots.txt file will not block robots from indexing the site. Google allows for the possibility that if its robot has reached one of our subpages from another domain, then as long as this page is considered valuable, it will go to the index.
Another important note is that most non-Google bots do not follow the guidelines in the robots.txt file and ignore the commands in it.
Summary
.
The robots.txt file is definitely an important element in technical SEO. Filling it badly risks limiting traffic from SEO, while filling it well will help manage a site’s indexation and crawl budget. The higher the volume of traffic on the site, the more subpages exist on our site, the better to take care of the correct filling of robots.txt.
.