 Piotr Smargol
Piotr Smargol Az észrevétlen robots.txt fájl lehetővé teszi a keresőrobotok hozzáférésének szabályozását a weboldalához. Emiatt döntő szerepet játszik a SEO-ban, és érdemes kellő figyelmet szentelni neki, különösen a fejlettebb SEO tevékenységek során. Ebben a cikkben arról lesz szó, hogy mi is az a robots.txt fájl, mire szolgál és miért fontos, majd példaszabályokkal és útmutatásokkal foglalkozunk, hogyan hozhatsz létre te magad is egy ilyen fájlt.
Legfontosabb megállapítások
- A robots.txt fájl létfontosságú a SEO szempontjából, mivel lehetővé teszi a weboldal tulajdonosok számára, hogy szabályozzák a keresőrobotok hozzáférését bizonyos oldalakhoz, ami közvetlenül befolyásolja a weboldal láthatóságát.
- Az irányelvek, mint például a „Disallow” és „Allow”, segítenek a weboldal tulajdonosainak abban, hogy kontrollálják weboldaluk indexelését és hozzáférhetőségét, ezzel optimalizálva a keresőmotorok által történő feltérképezést.
- A Google rendszeresen ellenőrzi a robots.txt fájlt, így a változtatások azonnal érvénybe lépnek, ami fontos az oldal frissítései és SEO stratégiájának gyors adaptációjához.
- Az oldaltérkép (sitemap) hozzáadása a robots.txt fájlhoz elősegíti a weboldal gyorsabb indexelését és a struktúrájának jobb megértését a keresőrobotok számára, különösen ha nincs Google Search Console profil.
- A Senuto láthatóság elemzése segíthet a robots.txt fájl hatásainak megértésében, mivel lehetővé teszi a weboldal láthatóságának és organikus forgalmának nyomon követését.
Mi az a robots.txt fájl és miért használják?
.
A robots.txt pontos nevű fájl egy egyszerű szöveges fájl – .txt formátumban mentve és közvetlenül a domain gyökérmappájába helyezve.
A fájlban irányelveket helyezünk el a weboldalunkat látogató robotok számára.
Ezekben az irányelvekben megadjuk, hogy a domain gyökeréből mely oldalakat látogathatják a robotok, és melyeket blokkoljuk a látogatás lehetőségét.
Érdemes megjegyezni, hogy a robotok megkerülhetik a robots.txt fájlban elhelyezett irányelveket, és így is lekérdezhetik az ott elhelyezett oldalakat vagy részeket.
Próbáld ki a Senuto Suite-ot 14 napig ingyen
Próbáld ki a Senuto Suite-ot 14 napig ingyenMiért fontos a robots.txt fájl?
.
A robots.txt fájl fontosságát abból tudhatjuk meg, hogy a Google robotja hogyan vizsgálja az oldalakat.
Amikor a Google robotja egy másik, már az indexében lévő domainről linkelt webhelyre bukkan, azonnal ellenőrzi a robots.txt fájlt, hogy ellenőrizze, mely webhelyen lévő erőforrásokat látogathatja. Ezután rendszeresen meglátogatja ezt a fájlt, hogy ellenőrizze, nem változott-e valami az irányelvekben.
A webhelynaplókat elemezve láthatjuk, hogy a robots.txt fájlt még a kisebb webhelyek esetében is több tucatszor vagy tucatszor látogatják meg havonta.
A már említett lehetőségen túl, hogy a robotok hozzáférését a webhely bizonyos helyeihez blokkoljuk, a robots.txt fájlt használjuk a az XML-oldaltérkép URL-jének alárendelésére. Az oldaltérkép ide linkelése különösen fontos, ha nincs profilunk a Google Search Console-ban, és ha az oldaltérképünknek van egy out-of-the-box URL címe.
Érdemes azt is megjegyezni, hogy a Google milyen aprólékosan tölti fel a robots.txt fájlt, amely az URL https://www.google.com/robots.txt címen található.
Példaszabályok a robots.txt fájlban. Milyen csoportokból és irányelvekből áll egy ilyen fájl?
.
Minden robots.txt fájl csoportokból épül fel. A direktívák csoportja a következőket tartalmazza:
- hivatkozás a bot nevére,
Minden egyes alkalmazást vagy az oldalt látogató felhasználót a kliensneve, vagy más néven bot neve mutat be. Ez az a név, amit a fájlon belül a User-agent direktívában a direktívákban elhelyezünk. - információ arról, hogy a megadott bot mely erőforrásokat zárja ki vagy engedi meg a látogatást.
.
Az ilyen csoportok mindenekelőtt lehetővé teszik számunkra:
- Kiválaszthatjuk annak a botnak a nevét, amelyre direktívákat akarunk irányítani.
User-agent: AdsBot-Google
.
- Adjunk direktívákat, hogy blokkoljuk a hozzáférést bizonyos könyvtárakhoz vagy URL-ekhez.
Disallow: /maps/api/js/
.
- Adjunk direktívákat, hogy engedélyezzük a hozzáférést bizonyos könyvtárakhoz vagy URL-ekhez.
Allow: /maps/api/js
.
Minden további csoport tartalmazhat egy másik robot nevét és direktívákat egy másik robot számára, például:
User-agent: Twitterbot Allow: /imgres
.
Összefoglalva, kapunk egy csoportkészletet:
User-agent: AdsBot-Google Disallow: /maps/api/js/ Allow: /maps/api/js Disallow: /maps/api/api/place/js/ Disallow: /maps/api/staticmap Disallow: /maps/api/streetview User-agent: Twitterbot Allow: /imgres
Figyeljük meg azonban, hogy a csoporton belüli sorokat felülről lefelé haladva dolgozzuk fel, és a felhasználói ügyfél (jelen esetben: a robot neve) csak egy szabálycsoportra, pontosabban a rá vonatkozó első, legerősebben megadott szabályra illeszkedik.
Önmagában a csoportok sorrendje a fájlban nem számít. Az is figyelemre méltó, hogy a robotok esetében a nagy- és kisbetűket megkülönböztetjük. Például a szabály:
Disallow: /file.asp
a http://www.example.com/file.asp aloldalra vonatkozik, de a http://www.example.com/FILE.asp aloldalra – már nem.
Ez azonban nem okozhat problémát, ha helyesen hozzuk létre az URL-eket a tartományunkban.
Végül, ha egy robothoz több csoport is tartozik, a duplikált csoportok direktívái egy csoportba olvadnak össze.
Belépőügynök
.
A robots.txt fájlban elhelyezett csoportok közül csak az egyiket illesztjük az egyes robotok nevéhez, a többit figyelmen kívül hagyjuk. Ezért egy Senuto nevű robot, látva a szabályokat a robots.txt fájlban a domain:
User-agent: * disallow: /search/ User-agent: Senuto allow: /search/
az alábbi szabályt fogja kiválasztani (a példában), és a /search/ könyvtárhoz fog hozzáférni, mivel pontosan arra irányul.
Disallow
.
A disallow direktíva meghatározza, hogy a kiválasztott robotok mely könyvtárakhoz, elérési utakhoz vagy URL-ekhez nem férhetnek hozzá.
disallow: [path]
.
disallow: [address-URL]
.
Az utasítás figyelmen kívül marad, ha nincs megadva elérési út vagy könyvtár.
disallow:
.
Példa az irányelv használatára:
disallow: /search
A fenti direktíva letiltja az URL-ekhez való hozzáférést:
- https://www.domena.pl/search/
- https://www.domena.pl/search/test-site/
- https://www.domena.pl/searches/
.
Érdemes megjegyezni, hogy az itt tárgyalt példa csak egyetlen szabály alkalmazására vonatkozik egyetlen kijelölt robotra.
Megengedni
.
Az engedélyezési irányelv meghatározza, hogy a kijelölt robotok mely könyvtárakhoz, elérési utakhoz vagy URL-címekhez férhetnek hozzá.
allow: [path]
.
allow: [cím-URL]
Az utasítás figyelmen kívül hagyásra kerül, ha nincs megadva elérési út vagy könyvtár.
allow:
.
Példa a direktíva használatára:
allow: /images
A fenti direktíva engedélyezi az URL-ek elérését:
- https://www.domena.pl/images/
- https://www.domena.pl/images/test-site/
- https://www.domena.pl/images-send/
.
Érdemes megjegyezni, hogy az itt tárgyalt példa csak egyetlen szabály alkalmazására vonatkozik egyetlen jelzett robotra.
Szitemap
.
A robots.txt fájlban a webhelyünk térképére mutató linket is elhelyezhetünk XML formátumban. Mivel a robots.txt oldalt rendszeresen látogatja a Google robotja, és az egyik első oldal a webhelyen, amelyet elér, határozottan érdemes a webhelytérképre mutató linket is elhelyezni.
sitemap: [unlabeled-address-URL]
.
A Google irányelvei szerint a sitemap URL-jének abszolútnak kell lennie (teljes, megfelelő URL), tehát például:
sitemap: https://www.domena.pl/sitemap.xml
Más irányelvek
.
A robots.txt fájlokban egyéb direktívákat is találhatunk, nevezetesen:
- host – a host direktíva arra szolgál, hogy az interneten elérhető számos másolat közül a preferált tartományt jelezze.
- crawl delay – a robottól függően ezt az irányelvet különbözőképpen használhatjuk. A Bing keresőrobot esetében a crawl delay-ben megadott idő a webhely egy aloldalának első és második feltérképezése közötti minimális idő lesz. A Yandex viszont úgy fogja értelmezni ezt az irányelvet, mint azt az időt, amit a robotnak várnia kell, mielőtt lekérdezné a domain minden egyes következő oldalát.
.
Mindkét direktívát a Google figyelmen kívül hagyja, és nem veszi figyelembe a webhely átvizsgálásakor.
Használhatunk reguláris kifejezéseket a szabályokban?
.
A Google keresőrobotjai (de nem csak) az elérési utakban támogatják a speciális tulajdonságokkal rendelkező egyes karaktereket. Ilyen karakterek többek között:
- Soros karakter * – bármely karakter nulla vagy több előfordulását jelzi,
- dollárjel $ – az URL végét jelöli.
.
.
Ez nem esik tökéletesen egybe azzal, amit a szabályos kifejezésekből https://pl.wikipedia.org/wiki/Wyrażenie_regularne ismerünk. Érdemes azt is megjegyezni, hogy a * és $ karaktertulajdonságok nem szerepelnek a robotkizárási szabványban https://en.wikipedia.org/wiki/Robots_exclusion_standard.
E karakterek nofollow használatára példa lenne a szabály:
disallow: *keresések*
.
Az idézett szabály megegyezik a szabállyal:
disallow: searches
és a * karaktereket egyszerűen figyelmen kívül hagyja.
Ezek a karakterek például akkor találnak felhasználásra, ha olyan oldalak elérését akarjuk letiltani, ahol az URL-ben két mappa között más mappák is lehetnek, akár egyesével, akár többszörösen.
Egy olyan szabály, amely blokkolja a hozzáférést olyan oldalakhoz, amelyeknek a cím URL mappájában van egy /search/ mappa, az oldal szerkezetében mélyebben pedig egy /on-demand/ mappa, így nézne ki:
disallow: /search/*/on-demand
A fenti szabállyal blokkolni fogjuk a hozzáférést ezekhez az URL-ekhez:
- https://www.domena.pl/search/wstawka-w-url/on-demand/wlasciwy-url/
- https://www.domena.pl/search/a/on-demand/,
.
De nem fogjuk blokkolni a hozzáférést ezekhez:
- https://www.domena.pl/search/on-demand/
- https://www.domena.pl/on-demand/
- https://www.domena.pl/search/adres-url/
Érdekes példa lenne, ha blokkolnánk a hozzáférést minden olyan .pdf kiterjesztésű fájlhoz (feltételezzük, hogy a tartományunkban minden ilyen kiterjesztésű fájl így kerül megszüntetésre), amely az URL-ben tartalmazza a /data-client/ mappát. Ehhez használjuk a direktívát:
disallow: /data-client/*.pdf$
A robots.txt fájlba foglalandó megfelelő szintaxisról és szabályokról bővebben az ABNF szintaxis specifikációban olvashat az URL: https://datatracker.ietf.org/doc/html/rfc5234 oldalon.
Mit kell tartalmaznia egy alapvető robots.txt fájlnak
.
Ahhoz, hogy egy robots.txt fájlt helyesen olvassanak, a következőkre kell törekednie:
- egy UTF-8 kódolású szöveges fájl legyen,
- a neve: robots.txt (minta URL https://www.domena.pl/robots.txt),
- közvetlenül a domain gyökérmappájában legyen elhelyezve,
- egyedi legyen a tartományon belül – nem lehet egynél több robots.txt fájl, mivel a megadottól eltérő URL-címen elhelyezett fájlokban lévő irányelvek nem lesznek elolvasva,
- a fájlon belül legalább egy irányelvcsoportot tartalmazzon
.
.
.
.
.
Néha a # jelet is megtalálhatjuk a fájlban. Ez lehetővé teszi, hogy megjegyzéseket adjunk a fájlon belül, amelyeket a Google robot nem fog elolvasni. Ha egy # jelet teszünk egy sorba, akkor az azt követő karaktereket ugyanabban a sorban a Google nem fogja elolvasni.
disallow: /search/ #a "kerítés" utáni bármelyik karaktert nem olvassa be a Google robotja
.
Hogyan hozzon létre egy robots.txt fájlt
.
Ezen a ponton készen állunk arra, hogy mi magunk is létrehozzunk egy ilyen fájlt. Ehhez bármilyen szövegszerkesztőre szükségünk lesz: MS Word, Notepad stb. A szerkesztőben hozzunk létre egy üres szöveges dokumentumot, és egyszerűen nevezzük el robots.txt-nek.
A következő lépés az, hogy a szöveges dokumentumot kiegészítjük a megfelelő irányelvekkel. Mielőtt begépeljük őket, fel kell készülnünk:
- a korlátozások által érintett robotok listája,
- a korlátozások által nem érintett robotok listája,
- listája azoknak az oldalaknak, amelyekhez a hozzáférést meg akarjuk tiltani,
- listája azoknak az oldalaknak, amelyek hozzáférését nem tudjuk blokkolni,
- az oldaltérkép URL címe,
.
.
.
.
.
A fenti adatok birtokában elkezdhetjük kézzel egymás alá gépelni a szabályokat a létrehozott szöveges dokumentumban. Példa robots.txt fájlra:
User-agent: * disallow: /business-card #blokkolja a hozzáférést a business-card mappában található oldalakhoz. disallow: /*.pdf$ #blokkolja a .pdf kiterjesztésű fájlok elérését. disallow: sortby= #blokkolja az olyan fájlok elérését, amelyeknek az url-jében szerepel a rendezés. User-agent: ownbotsc1 allow: * sitemap: <https://www.domena.pl/sitemap_product.xml> #link az xml sitemap-ra sitemap: <https://www.domena.pl/sitemap_category.xml> sitemap: <https://www.domena.pl/sitemap_static.xml> sitemap: <https://www.domena.pl/sitemap_blog.xml>
.
Az így létrehozott dokumentumot a domainünk gyökérmappájába kell elhelyeznünk azon az FTP-kiszolgálón, ahol a fájljai találhatók. Érdemes megjegyezni, hogy az olyan tartalomkezelő rendszerekben, mint például a WordPress, találunk olyan bővítményeket, amelyek lehetővé teszik számunkra az FTP-kiszolgálón található robots.txt fájl szerkesztését.
Hogyan tesztelhetjük, hogy a robots.txt fájlban található irányelvek helyesek-e?
.
Ahhoz, hogy alaposan tesztelhessük, hogy az általunk létrehozott robots.txt fájl helyesen működik-e, meg kell látogatnunk: https://www.google.com/webmasters/tools/robots-testing-tool.
Itt találunk egy tesztelőt, amely letölti a jelenleg a tartományon lévő robot.txt fájlt (a Google Search Console-ban ellenőrzött tulajdonosának kell lennünk), majd lehetővé teszi, hogy szerkesszük azt, és ellenőrizzük, hogy az általunk megadott aloldalakat blokkolják vagy átengedik-e a benne lévő direktívák.
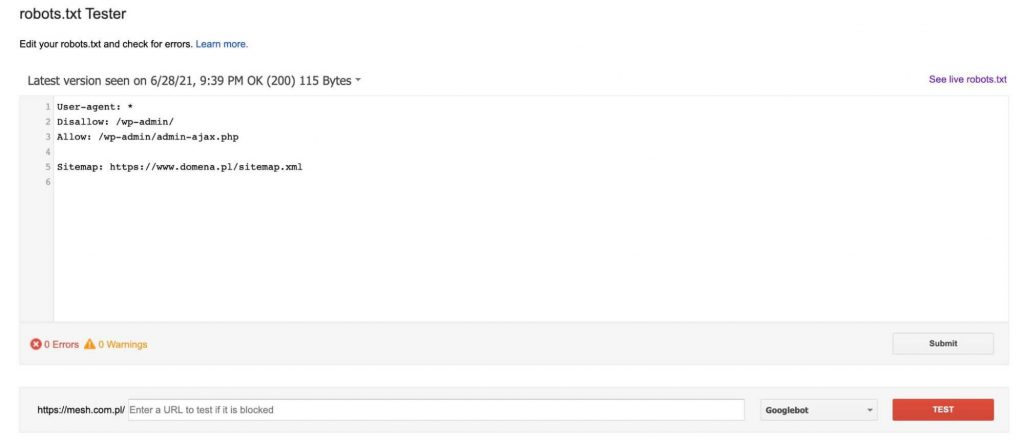
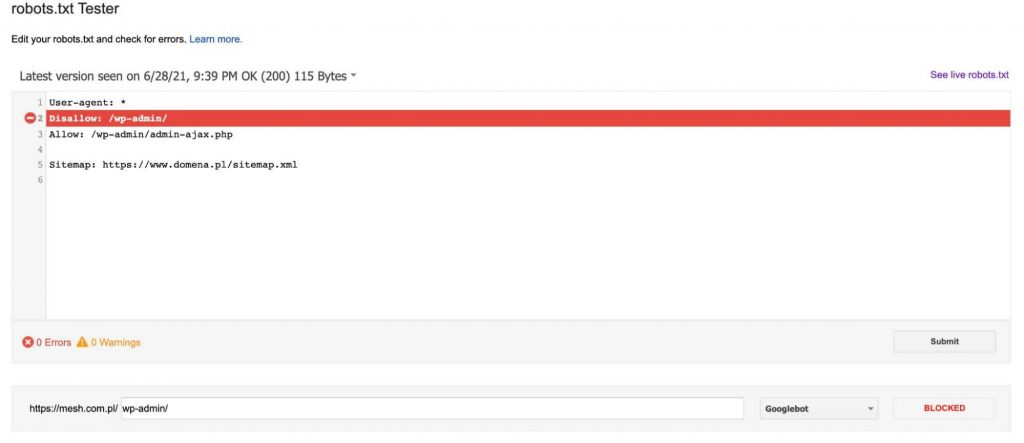
Minden alkalommal, miután egy URL-t hozzáadtunk a teszthez (a grafika alján), kattintsunk a piros „TEST” gombra, és válaszként információt kapunk arról, hogy a megadott URL-t blokkolták-e, és ha igen, akkor a robots.txt fájl melyik sora blokkolta az URL-ünket.
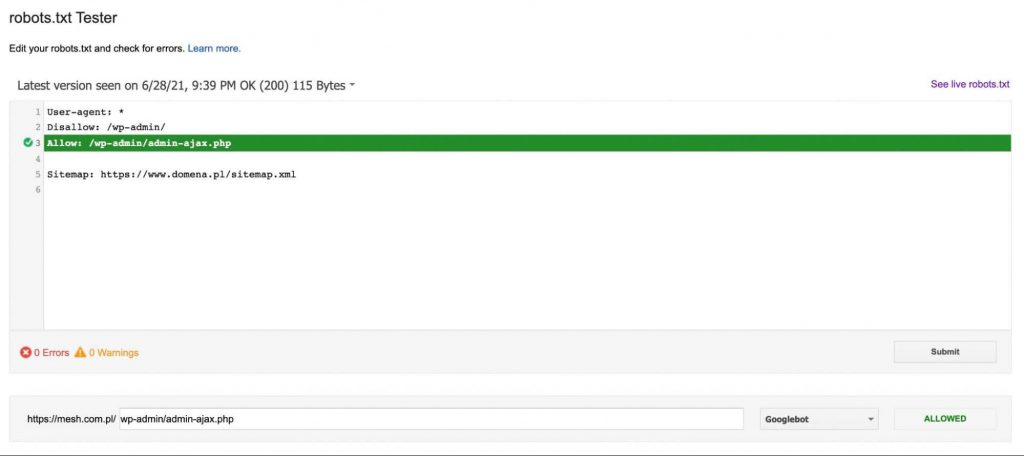
Ha az URL nincs blokkolva, akkor kapunk egy üzenetet, amely a Google robot számára elérhetővé teszi az irányelv URL-jét – ahogy az alábbi ábrán látható:
Mire kell figyelni a robots.txt fájl létrehozásakor?
.
A robots.txt fájl létrehozásakor különösen ügyeljünk arra, hogy a Google robot hozzáférését az oldalhoz teljesen vagy részben blokkoljuk. Ezért minden változtatást ebben a fájlban szakemberrel kell egyeztetni, hogy ne okozzunk még nagyobb kárt az oldalunknak.
Érdemes azonban megjegyezni, hogy a robots.txt fájl nem akadályozza meg a robotokat az oldal indexelésében. A Google megengedi azt a lehetőséget, hogy ha robotja egy másik domainről eljutott valamelyik aloldalunkra, akkor amíg ezt az oldalt értékesnek ítéli, addig az indexre kerül.
Egy másik fontos megjegyzés, hogy a legtöbb nem Google robot nem követi a robots.txt fájlban szereplő irányelveket, és figyelmen kívül hagyja az abban szereplő parancsokat.
Összefoglaló
.
A robots.txt fájl mindenképpen fontos eleme a technikai SEO-nak. A rosszul kitöltése a SEO-ból származó forgalom korlátozását kockáztatja, míg a jól kitöltése segít az oldal indexelésének és crawl költségvetésének kezelésében. Minél nagyobb az oldal forgalma, minél több aloldal létezik az oldalunkon, annál jobb gondoskodni a robots.txt helyes kitöltéséről.
.