Czym jest crawl budget i jak go mądrze zoptymalizować?

Jednym z zadań, jakie stoi przed każdym specjalistą SEO (a w szczególności przed takim, który pracuje przy dużych stronach internetowych) jest analiza crawl budgetu. Pomimo swojej wagi i całkiem dobrego wsparcia materiałów od Google – sami pracownicy wyszukiwarki bagatelizują na Twitterze rolę tego elementu w pracy nad pozycją i ruchem organicznym. Ale czy słusznie?
Jak działa Google oraz jak zbiera informacje?
Poruszając temat budżetu crawlowania warto przypomnieć sobie, w jaki sposób wyszukiwarka pozyskuje, indeksuje i porządkuje informacje. Pamiętanie o tych trzech krokach stanowi fundamentalny element w późniejszej pracy nad stroną www:
Krok 1: Skanowanie. Przeszukiwanie zasobów internetu w celu wykrycia wszystkich możliwych odnośników, plików i danych – a także poruszanie się po nich. Zazwyczaj Google zaczyna skanowanie od najpopularniejszych miejsc w sieci, a potem przechodzi dalej, do kolejnych zasobów.
Krok 2: Indeksowanie. Google stara się rozpoznać tematykę pobieranej strony, a także określić czy dana zawartość/dany dokument jest unikalny czy może jest duplikatem innej strony. Na tym etapie dochodzi do grupowania treści i określenia ich ważności (np. poprzez odczytywanie sugestii w tagach rel=”canonical” lub rel=”alternate”).
Krok 3: Wyświetlanie wyników. Posegmentowane i zaindeksowane dane Google wyświetla w oparciu o zapytania użytkowników. Dodatkowo na tym etapie treści są odpowiednio sortowane z uwzględnieniem lokalizacji wyników.
Ważne: Krokiem 4, który często jest pomijany w omówieniach, jest także renderowanie zawartości. Google jako crawler jest domyślnie robotem indeksującym zawartość tekstową. Ewolucja technologii webowych wymusza na Google stosowanie nowych rozwiązań, które pozwalają nie tylko “czytać” ale też “widzieć” – i właśnie do tego sprowadza się renderowanie. Dzięki niemu Google znacząco zwiększa swoje dotarcie do nowych stron w sieci i poszerza swój indeks wyników wyszukiwania.
Uwaga: Problemy z renderowaniem zawartości mogą być także jedną z przyczyn problemów z crawl budget strony www.
Czym jest crawl budget?
Crawl budget to nic innego, jak określona częstotliwość, z jaką crawlery i boty wyszukiwarek mogą indeksować Twoją stronę, a także całkowita ilość adresów, które mogą crawlować jednorazowo. O crawl budget dobrze myśleć jako o kredytach do wykorzystania w ramach usługi lub aplikacji – jeżeli nie zadbamy o to, aby “doładować” budżet crawlowania, to prędkość i częstotliwość odwiedzin robota spadnie.
Wspomniane zasilenia w przypadku SEO oznacza pracę związaną z pozyskiwaniem linków do strony lub budowaniem ogólnej popularności witryny. W związku z tym crawl budget jest nierozerwalną częścią całego ekosystemu sieci web. Robiąc dobrą pracę contentową i pozyskując wartościowe linki do strony rozszerzasz ilość dostępnego dla ciebie budżetu crawlowania.
Google w swoich materiałach nie podejmuje się bezpośrednio podania definicji crawl budget – zamiast tego wskazują na istnienie dwóch elementarnych składników crawlowania, które przekładają się na częstotliwość i skalę wizyt robota Google:
- Crawl rate limit
- Crawl demand
Przyjrzyjmy się obu tym składnikom.
Senuto MCP Server - połącz AI ze swoim SEO
Pierwszy most między Twoim LLM a polskim TOP10 Google. Twój asystent AI z dostępem do danych SEO w czasie rzeczywistym.
Zobacz, jak działaCzym jest crawl rate limit i jak go sprawdzać?
Crawl Rate Limit to w dużym uproszczeniu ilość jednoczesnych połączeń, jakie może nawiązać Googlebot podczas crawlowania Twojej witryny. Ponieważ Google nie chce obniżać doświadczenia dla odwiedzających stronę – dopasowuje ilość jednoczesnych połączeń do wydajności Twojej strony/Twojego serwera. Krótko mówiąc, im wolniejszą stronę posiadasz, tym mniejszy crawl rate limit Google Ci przydzieli.
Ważne: Na poziom crawl rate limit wpływa także ogólna kondycja SEO witryny – jeżeli masz na stronie wiele przekierowań, błędów 404/410 lub serwer często odpowiada kodem 500, to ilość połączeń także będzie spadać.
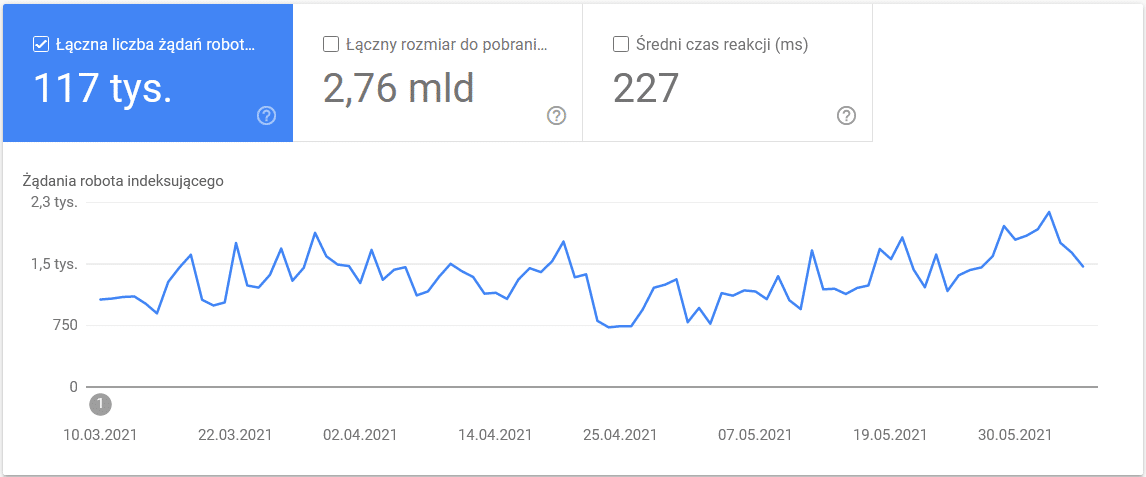
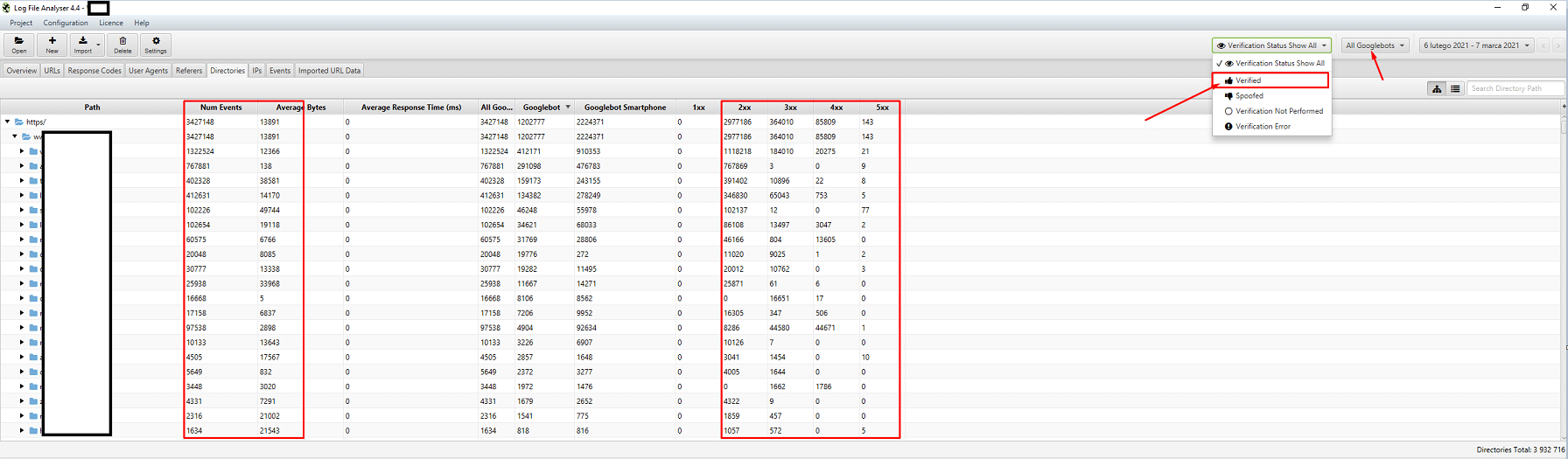
Analizę danych dotyczących crawl rate limit przeprowadzić można z wykorzystaniem danych dostępnych w Google Search Console, w sekcji “Statystyki Indeksowania”:
Crawl demand, czyli popularność witryny
O ile Crawl Rate Limit wymaga od nas dbania o techniczne aspekty witryny, tak Crawl Demand to nagroda za budowanie jej popularności w sieci. W dużym uproszczeniu – im więcej dzieje się wokół Twojej strony (i na niej), tym większy Crawl Demand ona odnotowuje.
W tym przypadku Google bierze pod uwagę dwie rzeczy:
- Po pierwsze chętniej i częściej crawluje się adresy URL/strony, które cieszą się większą popularnością w internecie (niekoniecznie kieruje do nich więcej adresów URL).
- Świeżość danych w indeksie – Google dąży do tego, aby wyświetlać w indeksie tylko najbardziej aktualne informacje. Ważne: Tworzenie coraz to nowszych treści nie oznacza, że ogólny poziom Crawl budget wzrośnie.
Czynniki wpływające na crawl budget
W poprzednim punkcie zdefiniowaliśmy crawl budget jako kombinację crawl rate limit oraz crawl demand. Trzeba pamiętać, że tylko jednoczesne zatroszczenie się o oba powyższe elementy zapewni odpowiednie crawlowanie (a w rezultacie indeksowanie) naszej strony www.
Poniżej umieszczam prostą listę elementów, które warto brać pod uwagę przy pracy z budżetem crawlowania:
- Serwer – przede wszystkim jego wydajność. Im wolniejsze działanie, tym większe prawdopodobieństwo, że Google poświęci mniej zasobów na indeksowanie nowych treści.
- Kody odpowiedzi serwera – im więcej adresów będących przekierowaniem 301 lub błędem 404/410, tym mniejsza skuteczność indeksowania strony. Ważne: Szczególną uwagę należy zwracać na pętle przekierowań – każdy kolejny “skok” obniża Crawl Rate Limit strony podczas kolejnej wizyty Google.
- Blokady w pliku robots.txt – stosowanie reguł w robots.txt “na czuja” powoduje powstawanie tzw. wąskich gardeł indeksowania. W efekcie co prawda porządkujemy zawartość indeksu, ale jednocześnie tracimy skuteczność indeksowania nowych podstron (bo zablokowane adresy były mocno osadzone w strukturze całego serwisu).
- Nawigacja fasetowa/identyfikatory sesji/wszelkie parametry w adresach – zwłaszcza sytuacje, w których do jednego parametru można dopisać wiele innych, a także nie ma wprowadzonych ograniczeń co do tego. W efekcie Google będzie w stanie dotrzeć do nieskończenie wielu adresów i poświęci całe dostępne zasoby na nie te elementy strony, na jakich nam zależy.
- Duplicate content – zduplikowany content (abstrahując od kanibalizacji) obniża w znaczący sposób skuteczność indeksowania nowych treści.
- Thin Content – czyli sytuacja, w której stosunek treści do kodu HTML jest bardzo niski – wtedy Google może uznać podstrony za tzw. soft 404 i ograniczyć indeksowanie zawartości (nawet gdy ma ona znaczenie – np. strony producentów z jednym produktem, bez unikalnej warstwy tekstowej).
- Brak lub słabe linkowanie wewnętrzne.
Narzędzia przydatne w analizie crawl budget
Ponieważ crawl budget nie ma benchmarków (tzn. że ciężko go porównywać między sobą), warto uzbroić się w zestaw narzędzi, które ułatwią zbieranie i analizowanie danych.
Google Search Console
GSC w fajny sposób rozwinęło swoje możliwości na przestrzeni lat. W przypadku analizy crawl budget interesują nas dwa główne raporty – Index Coverage (Stan indeksu) oraz Statystyki indeksowania.
Chcesz być mistrzem GSC? Sprawdź nasz Poradnik Google Search Console krok po kroku.
Index Coverage w GSC
Raport ten jest bardzo obszerny, natomiast dane o adresach, które zostały wykluczone z indeksowania to świetna okazja do tego, żeby zrozumieć z jakiego kalibru problemem przychodzi Ci się zmierzyć.
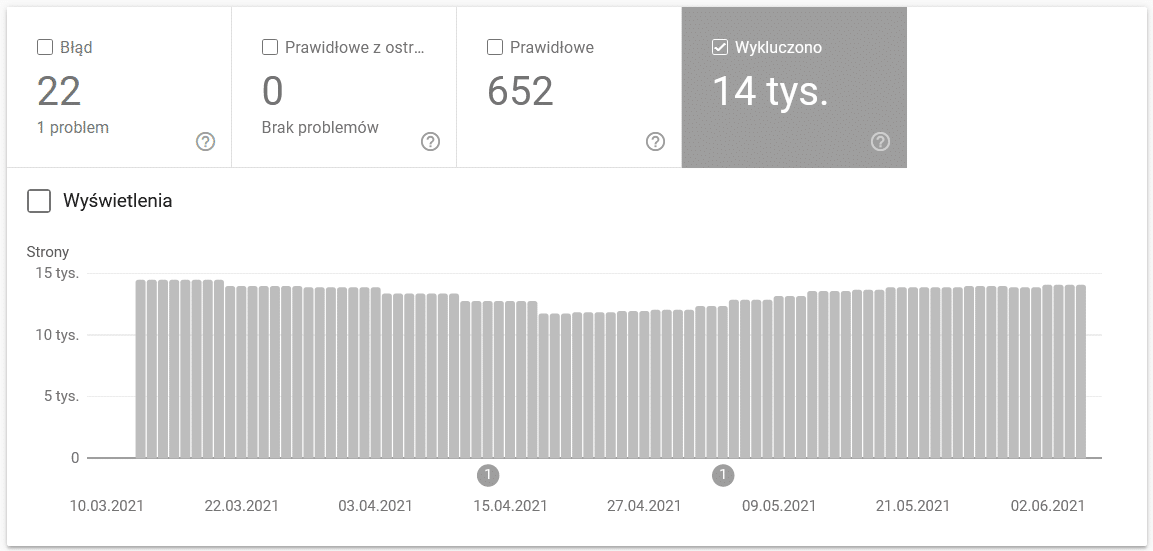
Samo omówienie tego raportu zasługuje na oddzielny dokument, natomiast sugeruję Ci zwracać szczególną uwagę na następujące dane w raporcie:
- Strona wykluczona za pomocą tagu „noindex” – generalnie im więcej podstron ma noindex, tym mniej ruchu budują. Rodzi się zatem pytanie – po co te strony w serwisie? Jak ograniczyć dopływ do nich?
- Strona zeskanowana, ale jeszcze nie zindeksowana – w tej sytuacji warto sprawdzić, czy robot Google może poprawnie zrenderować zawartość. Warto pamiętać, że każdy taki URL marnuje budżet crawlowania, bo nie przekłada się na nowy ruch organiczny.
- Strona wykryta, a obecnie nie zindeksowana – to jeden z większych problemów, na który warto zwrócić uwagę w pierwszej kolejności.
- Duplikat, użytkownik nie oznaczył strony kanonicznej – wszelkie duplikaty stron są bardzo niebezpieczne nie tylko dlatego, że obniżają crawl budget, ale również wzmagają ryzyko wystąpienia kanibalizacji.
- Duplikat, wyszukiwarka Google wybrała inną stronę kanoniczną niż użytkownik – teoretycznie problem nie jest poważny, w końcu Google jest na tyle sprytne, że potrafi podjąć dobre decyzje za nas. W praktyce wyszukiwarka Google podejmuje decyzje o tym, jaki adres uznaje za kanoniczny, w sposób mocno przypadkowy – niejednokrotnie obcinając wartościowe strony poprzez canonical na stronę główną.
- Pozorny błąd 404 – wszelkie błędy “soft” są bardzo niebezpieczne, bo mogą prowadzić do wyindeksowania kluczowych podstron w serwisie.
- Duplikat, przesłany URL nie został oznaczony jako strona kanoniczna – case podobny do tego, gdy użytkownik nie oznaczył duplikatów.
Statystyki indeksowania
Raport Statystyki indeksowania nie jest idealny i zdecydowanie bardziej od niego polecam zabawę ze starymi dobrymi logami serwerowymi, które pozwalają nieco głębiej wejść w dane (i nieco bardziej je modelować).
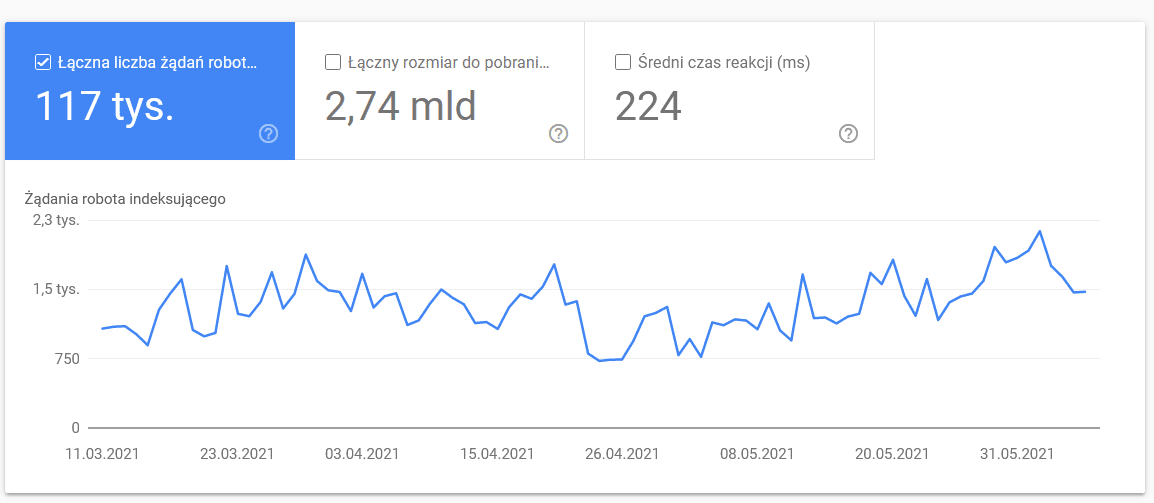
Jak wspomniałem wcześniej, ciężko o benchmarki dotyczące tego, jak powinny wyglądać liczby na powyższym wykresie. To, na co warto szczególnie zwrócić uwagę, to:
- Średni czas pobierania. Na screenie poniżej widać, że średni czas drastycznie się wydłużył i wynikało to z problemów dotyczących serwera:
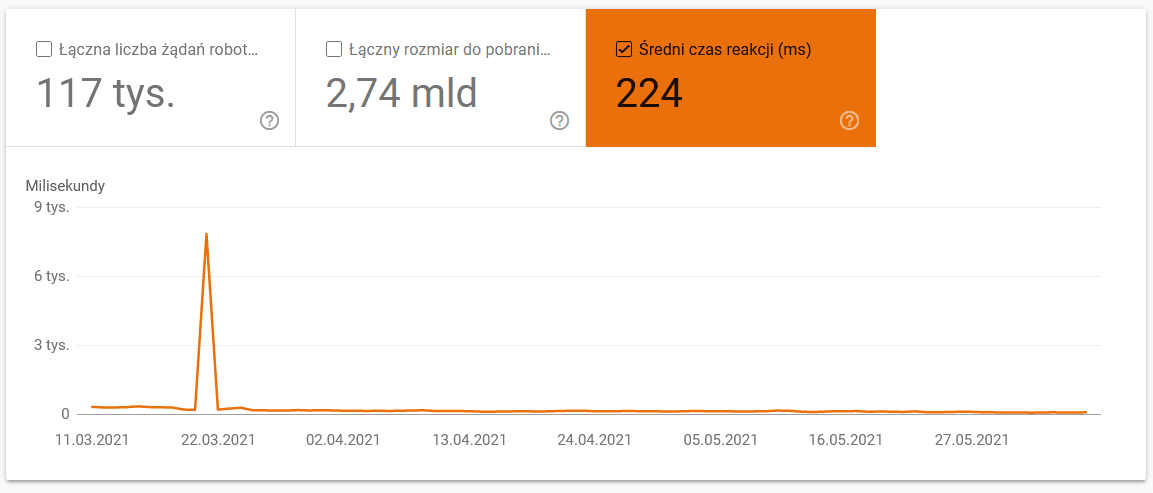
- Według typu odpowiedzi. Raport pozwala znaleźć ogólny pogląd na to, czy jest problem z działaniem strony www. Powinny Cię interesować wszystkie nietypowe kody odpowiedzi serwera, jak np. na poniższym 304-ki. Są to adresy, które funkcjonalnie nie spełniają żadnej roli, jednak Google marnuje swoje zasoby na to, żeby po nich się poruszać.

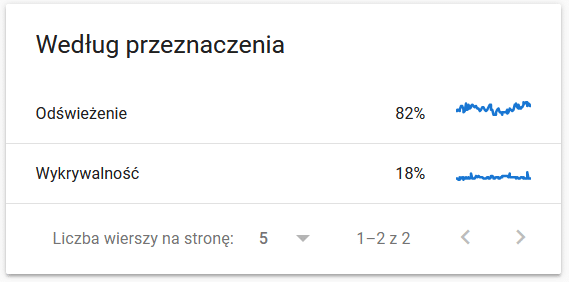
- Według przeznaczenia. Generalnie dane tutaj zależą w dużej mierze od tego, jak dużo nowych treści pojawia się na stronie, natomiast dane, które wyłapuje Google, w porównaniu do tego, co widzi użytkownik, bywają bardzo ciekawe:
Zawartość jednego z odświeżanych adresów dla Google:
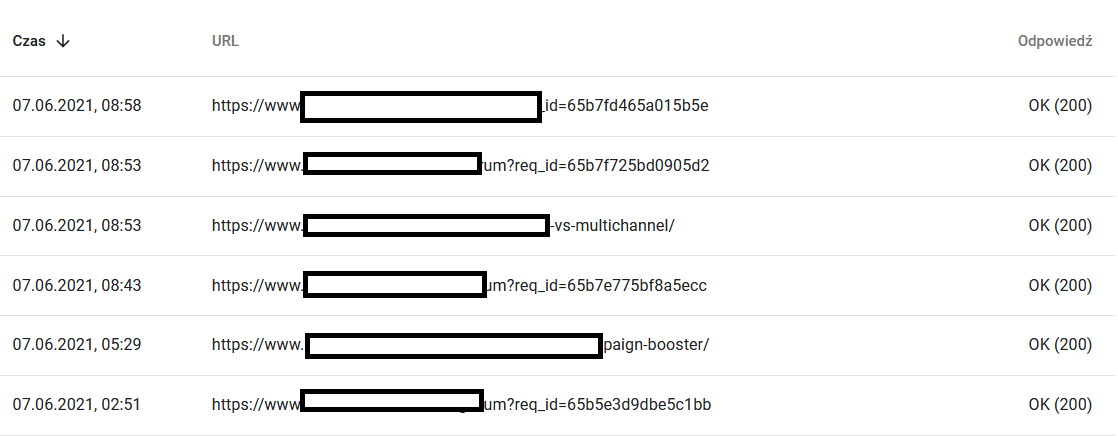
Tymczasem co widzi user w przeglądarce:
Zdecydowanie jest potencjał do analizy. :)
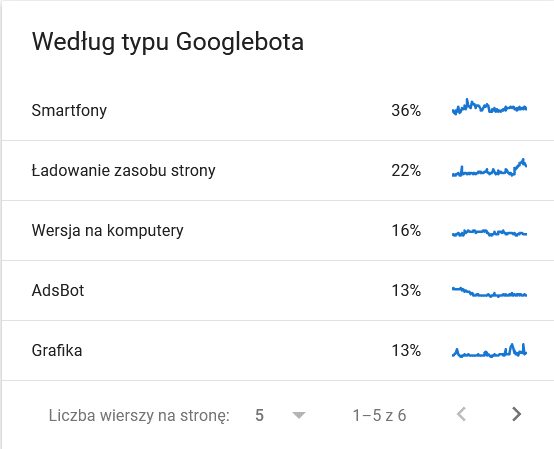
- Według typu Googlebota. Tutaj mamy na tacy informację, jaki bot i co chce zrobić z naszą zawartością. Na screenie poniżej widać, że 22% całości to ładowanie zasobu strony:
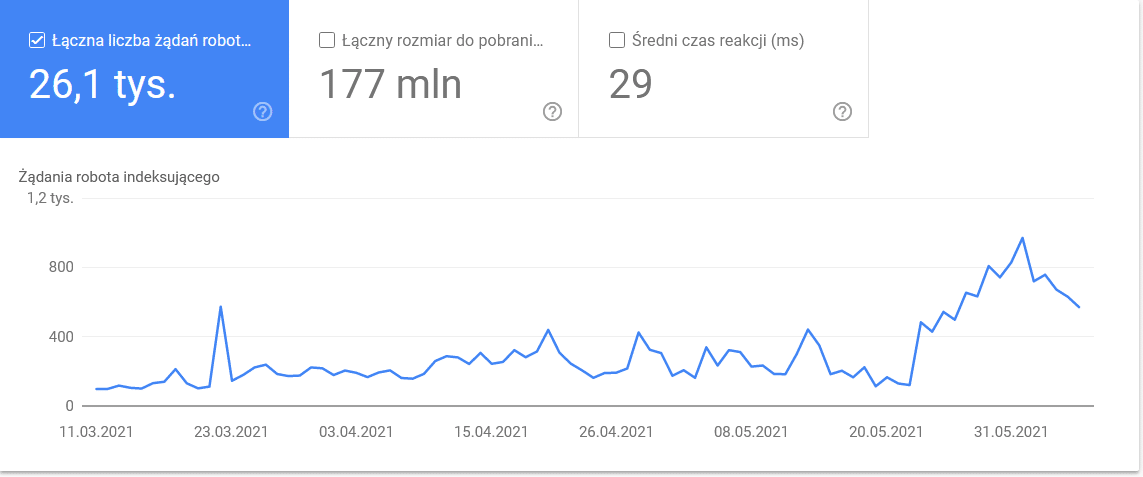
Całość mocno się rozpasła w ostatnich dniach przed wygenerowaniem wykresu:
I znów schodząc na szczegóły widzimy, że te adresy wymagają szczególnej uwagi:
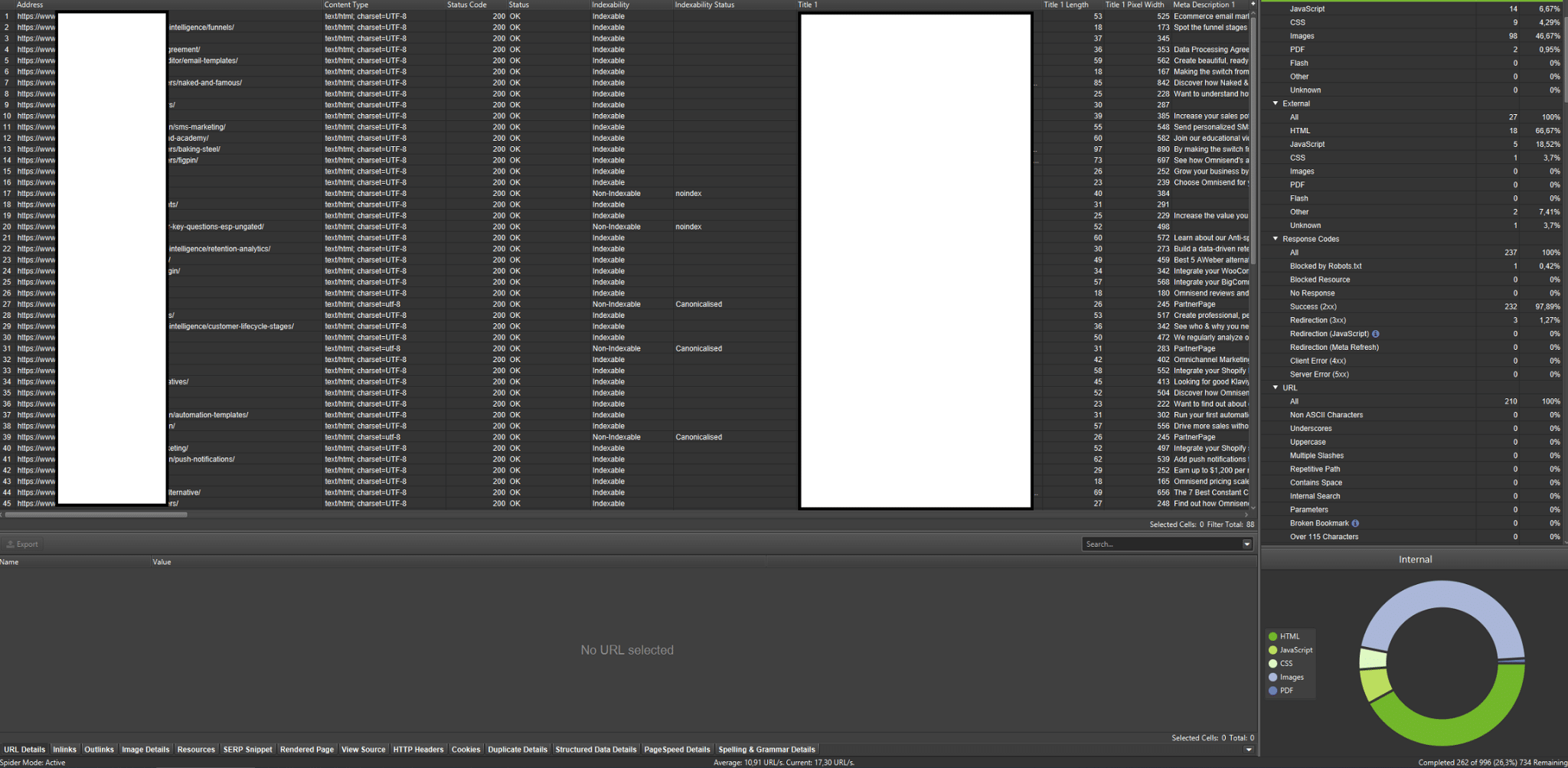
Crawlery zewnętrzne (na przykładzie Screaming Frog SEO Spider)
Nadrzędnym celem narzędzi związanych z analizą crawl budget na stronie jest zasymulowanie tego, w jaki sposób boty crawlujące poruszają się po stronie. Dzięki nim możesz szybko zidentyfikować, czy wszystko, co się dzieje na stronie, jest tak, jak być powinno. Screaming Frog SEO Spider to jedno z najważniejszych tego typu narzędzi.
Jeżeli jesteś wzrokowcem to większość dostępnych na rynku rozwiązań pozwala na wizualizację danych:
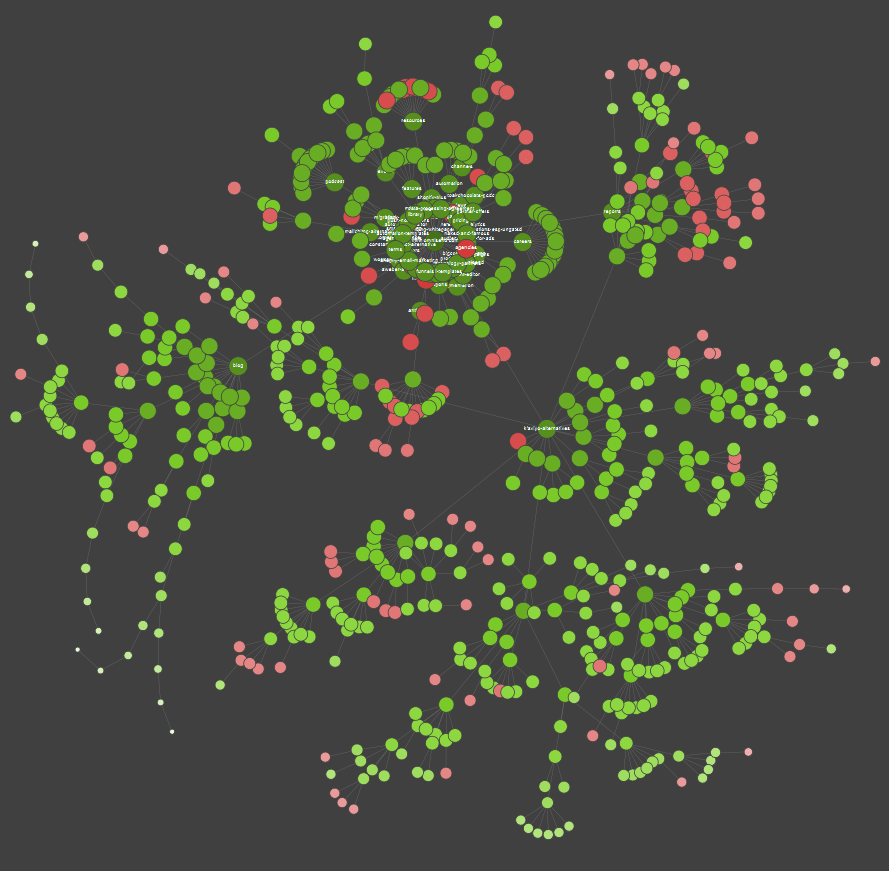
Na przykładzie powyżej czerwone punkty oznaczają podstrony, które nie są indeksowane. Warto zastanowić się, jaki jest ich wpływ na działanie serwisu oraz czy są nam potrzebne. Jeżeli w logach serwerowych widzimy, że Google traci na nich dużo czasu, a nie generują one wartości – należy poważnie rozważyć sens ich posiadania.
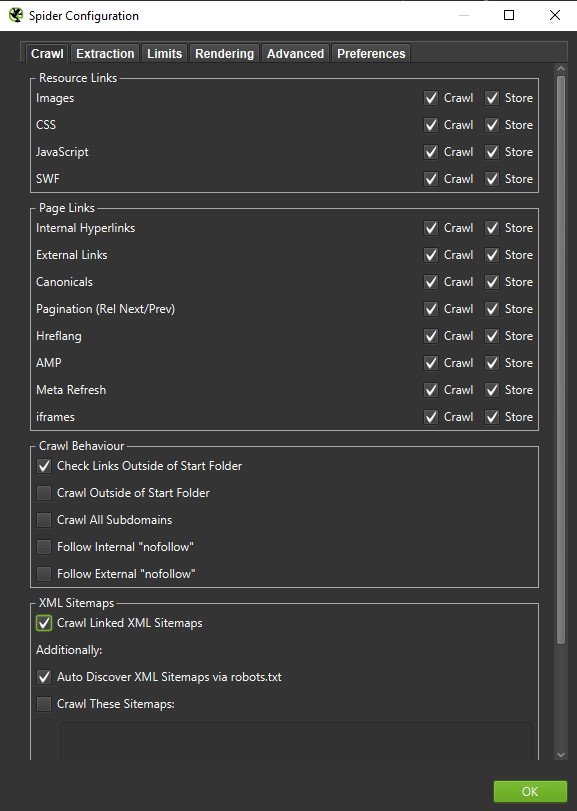
Ważne: Kluczowe jest zastosowanie dobrych ustawień crawlera, tak aby zachowywać się jak robot Google (na tyle na ile to możliwe). Przykładowe ustawienia na moim komputerze:
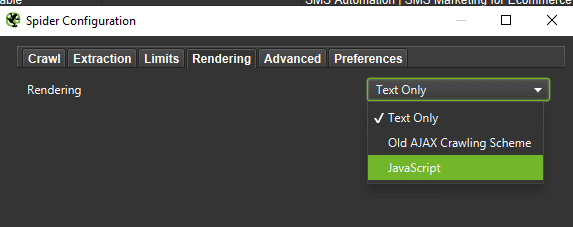
Na potrzeby dokładnej analizy warto zrobić crawl Text Only, ale także JavaScript – żeby porównać różnice (o ile takie są):
Na sam koniec warto wyżej pokazaną konfigurację przećwiczyć na dwóch różnych User Agentach:
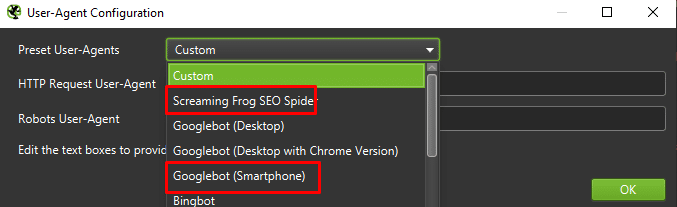
W większości przypadków wystarczy skupić się na tym, co crawluje/renderuje Googlebot mobilny.
Ważne: Warto skorzystać z możliwości, jakie daje Screaming Frog i połączyć crawler z danymi GA oraz Google Search Console. W ten sposób możemy szybko zidentyfikować crawl budget waste, czyli np. sporą ilość adresów bez ruchu, które mogą być zbyteczne.
Narzędzia do analizy logów (np. Screaming Frog Logfile analyzer)
Dobór narzędzia do analizowania logów serwerowych to kwestia indywidualna. Ja na co dzień korzystam ze Screaming Frog Log File Analyzer, które nie jest co prawda najwydajniejszym narzędziem (załadowanie ogromnej paczki logów = zawieszenie oprogramowania), ale podoba mi się jego interfejs. Kluczowe jest, abyś wybrał przeglądanie tylko zidentyfikowanych botów Google.
Narzędzia do monitorowania widoczności
Przydatne, bo pozwalają zidentyfikować topowe podstrony. Jeżeli podstrona ma dużo fraz w top wynikach wyszukiwania w Google (= notuje dużo ruchu), to znaczy, że ma potencjalnie większy crawl demand (do sprawdzenia w logach czy tak jest, tzn. czy Google faktycznie robi więcej hitów do wybranych adresów).
Interesują nas dwa ogólne raporty w Senuto, do późniejszego dalszego przeglądu. Znajdują się one w Analizie widoczności, w zakładce “Sekcje” – Ścieżki oraz URLs. Widać poniżej:
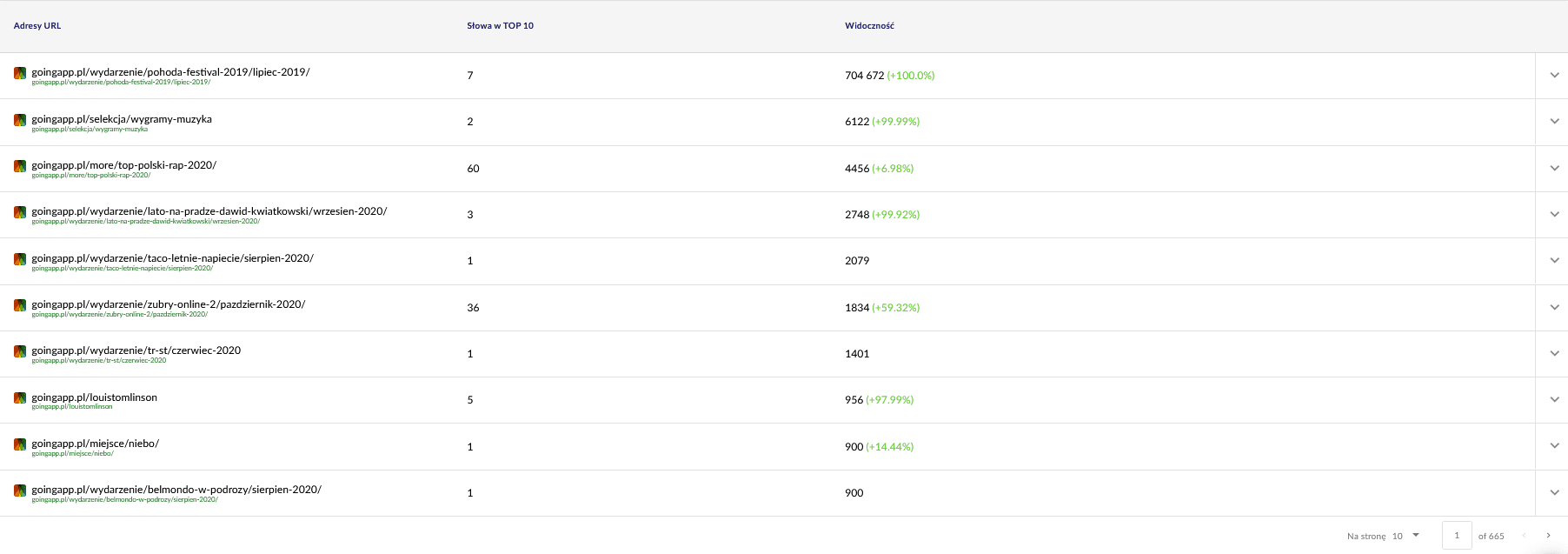
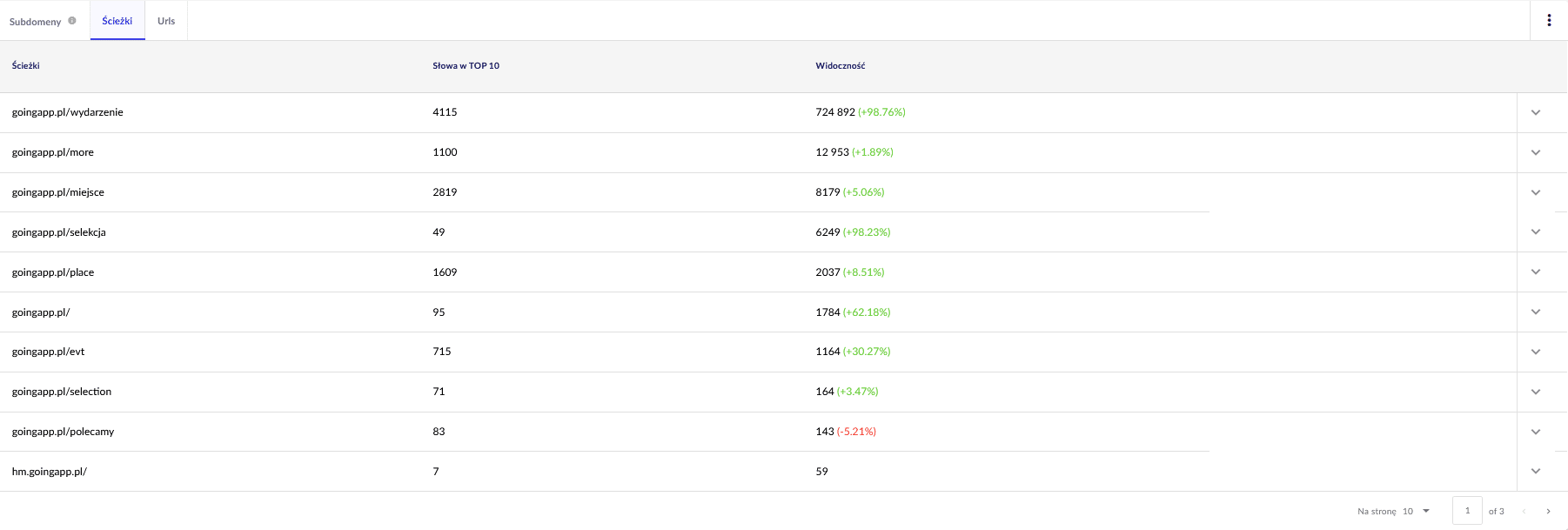
Interesuje nas zwłaszcza ten drugi raport. Sortujemy i sprawdzamy, jak wygląda kwestia widoczności słów kluczowych (na ile i jakich słów kluczowych serwis jest widoczny w top 10). W ten sposób możemy potem zidentyfikować główną oś do stymulacji budżetu crawlowania (i jego efektywnego wykorzystania).
Narzędzia do backlinków (Ahrefs, Majestic)
Duża ilość linków do konkretnej strony/podstrony to okazja do optymalizacji crawl budgetu wokół niej. W takiej sytuacji popularne podstrony przyjmują rolę hubów i ułatwiają przekazywanie mocy dalej. Dodatkowo popularna podstrona ze sporą ilością wartościowych linków ma większe szanse na bycie crawlowaną częściej.
W Ahrefs interesuje nas raport “Pages”, a dokładnie “Best by links”:
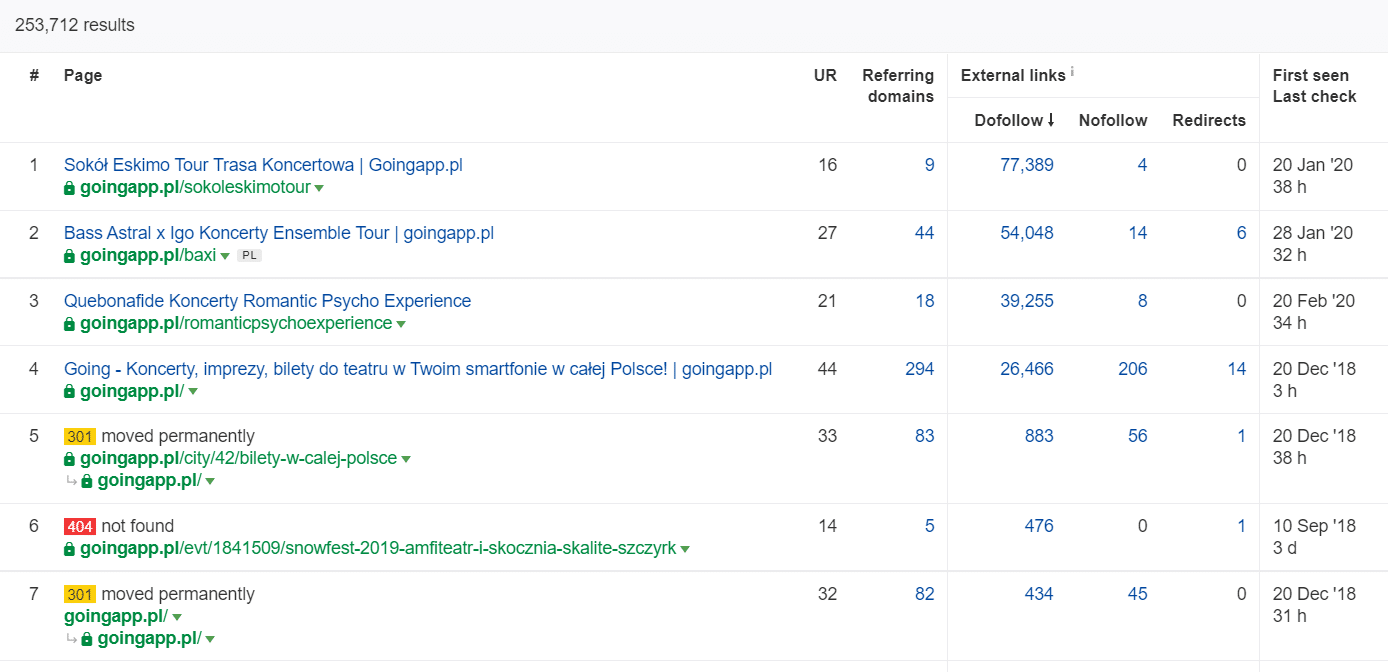
Na przykładzie poniżej widać, że niektóre z LP koncertowych generowały całkiem sensowne parametry w zakresie ilości linków przychodzących. Pomimo tego, że koncerty podczas pandemii się nie odbywają, to nawet w takim okresie warto wykorzystywać tak mocne historycznie podstrony do generowania zainteresowania robotów crawlujących i rozprowadzania mocy w głąb serwisu.
Kiedy wiesz, że masz problem z crawl budget?
Zrozumienie, że strona ma problematyczny crawl budget (za niski) nie jest proste. Przede wszystkim dlatego, że całe pozycjonowanie jest bardzo kompleksowym zagadnieniem. W związku z czym często brak dobrej pozycji albo indeksowania się produktów może wynikać z niskiej jakości linków do strony lub braku odpowiednich treści na stronie.
Typowa diagnostyka w przypadku crawl budget wymaga sprawdzenia:
- Ile czasu zajmuje zaindeksowanie się nowych podstron (wpisów/produktów) od momentu publikacji (wykluczając prośbę o zaindeksowanie w Google Search Console).
- Jak długo Google utrzymuje w swoim indeksie nieaktualne adresy URL? Ważne: wyjątkiem są adresy przekierowane – Google specjalnie utrzymuje je w indeksie.
- Czy strona łapie indeksację, ale potem ją traci?
- W analizie logów – jak dużo czasu Google poświęca na podstronach, które nie budują żadnej wartości (ruchu)?
Jak analizować i optymalizować crawl budget?
Przede wszystkim o tym, czy warto bawić się w optymalizację budżetu crawlowania decyduje wielkość serwisu. Google sugeruje, że strony poniżej 1000 podstron generalnie nie powinny się przejmować tym, jak wykorzystują zasoby botów crawlujących na swoją korzyść. Moim zdaniem walkę o wydajność i efektywne crawlowanie powinien podjąć każdy, którego strona ma więcej niż 300 podstron, a zawartość ciągle ulega zmianie (np. dochodzą nowe podstrony/wpisy na blogu).
Dlaczego? Ze względów higienicznych. Wdrożenie odpowiednich nawyków związanych z optymalizacją i dobrym wykorzystaniem budżetu crawlowania na wczesnym etapie rozwoju serwisu pozwala ograniczyć ilość koniecznych napraw i przebudowy w przyszłości.
Typowy proces w optymalizacji crawl budget
Prace związane z analizą i optymalizacją budżetu crawlowania dzielimy zazwyczaj na trzy etapy:
- Zbieranie danych, czyli kompilacja wszystkiego, co wiemy o stronie – zarówno od webmasterów, jak i w oparciu o zewnętrzne narzędzia.
- Analiza widoczności i low hanging fruits, czyli co obecnie najlepiej działa, co może działać lepiej i gdzie mamy najszybszy potencjał wzrostu.
- Rekomendacje dotyczące crawl budget.
Zbieranie danych pod audyt crawl budget
1. Pełen crawl serwisu z wykorzystaniem jednego z dostępnych na rynku narzędzi. Staramy się wykonać co najmniej dwa crawle: jeden symulujący Googlebota i drugi, który pobiera stronę jako domyślny user agent (może być jakiś typowy przeglądarkowy user agent). Na tym etapie interesuje nas tylko pobranie 100% zawartości. Jeżeli z jakiegoś powodu widzimy, że crawler zaczyna się zapętlać (po jednym dniu crawlowania mamy ciągle 10% serwisu na dysku) – wiedz, że masz problem i możesz zatrzymać crawlowanie. Rozsądna ilość adresów do analizy, w przypadku dużych serwisów, to 250-300 tys. podstron.
- Szukamy tu przede wszystkim wewnętrznych przekierowań 301, błędów 404, ale także sytuacji, w których zawartość serwisu może zostać zaklasyfikowana jako thin content. W Screaming Frog istnieje możliwość skonfigurowania narzędzia tak, aby wykrywało near duplicate content:
2. Logi serwera. Idealny zakres czasu to ostatni miesiąc, jednak dla dużych serwisów wystarczą czasami dwa ostatnie tygodnie. W idealnym świecie powinniśmy mieć dostęp do historycznych logów serwerowych, aby porównywać, jak poruszał się po stronie Googlebot, kiedy wszystko z serwisem było idealnie.
3. Eksport danych z Google Search Console. Raport Stan Indeksu oraz Statystyki Indeksowania w połączeniu z danymi z punktów 1 oraz 2 powinny dać w miarę pełny obraz tego, co się dzieje na stronie.
4. Dane dotyczące ruchu organicznego. Top podstrony wg Google Search Console, Google Analytics, a także Senuto i Ahrefs. Chcemy zidentyfikować wszystkie podstrony, które wyróżniają się na tle pozostałych – mają dużą widoczność, dużo ruchu lub dużo linków przychodzących. Podstrony te powinny zostać Twoimi najważniejszymi elementami w pracy nad crawl budget. Wykorzystamy je do poprawy crawlowania dla najważniejszych podstron.
5. Manualny przegląd indeksu. W niektórych przypadkach najlepszym przyjacielem specjalisty SEO są najprostsze rozwiązania, czyli przegląd danych prosto z indeksu. Warto pokusić się o zebranie wyników dla kombinacji inurl oraz site: dla Twojej strony www.
Tak pozyskane dane łączymy w jedno. Osią do pracy będą zazwyczaj zewnętrzne crawlery, które pozwalają na dodanie danych z zewnątrz (GSC, logi i organic traffic).
Jaka jest sytuacja Twojej strony w Google?
Analiza widoczności i low-hanging fruit
Ten proces zasługuje co prawda na oddzielny artykuł, ale chodzi o przegląd managerski (z lotu ptaka) celów i skuteczności ich realizacji na stronie. Interesują nas wszelkie sytuacje nietypowe: nagły spadek ruchu (wykluczając sezonowość) oraz pokrywające się z tym spadkiem ruchy w zakresie widoczności organicznej. Sprawdzamy, które grupy podstron są najmocniejsze, ponieważ będą one stanowiły nasze HUBy do rozprowadzania Googlebota w głąb serwisu.
W idealnym świecie taki przegląd warto zrobić od początku istnienia serwisu. Ponieważ jednak ilość danych z miesiąca na miesiąc wzrasta, warto skupić się na przeanalizowaniu widoczności i ruchu organicznego do 12 miesięcy wstecz.
Rekomendacje dotyczące crawl budget
Poniższe działania będą różne w zależności od wielkości serwisu, z jakim przyjdzie Ci się mierzyć, niemniej są to najważniejsze elementy, które zawsze biorę pod uwagę podczas pracy nad analizą wydatkowania budżetu crawlowania. Nadrzędnym celem tych prac jest rozwiązanie problemu wąskich gardeł w serwisie – czyli zapewnienie maksymalnego crawlability dla robotów Google (lub innych botów indeksujących).
1. Zaczynamy od podstaw – eliminacja wszelkiego rodzaju błędów 404/410, analiza przekierowań wewnętrznych oraz ich usunięcie z linkowania wewnętrznego. Wynikiem analizy powinien być kolejny crawl, gdzie wszystkie odnośniki będą odpowiadać kodem odpowiedzi 200 – żadnych przekierowań i błędów 404 w serwisie.
- Na tym etapie warto też poprawić wszelkie łańcuchy przekierowań, które widzimy w raporcie backlinków do strony.
2. Po ponownym crawlu upewniamy się, czy w strukturze serwisu nie występują oczywiste duplikaty.
- Sprawdzamy też możliwość występowania potencjalnej kanibalizacji – poza problemami z pozycjonowaniem dwóch i więcej stron na tę samą frazę kluczową (brak kontroli nad tym, co wyświetli Google) wpływa to negatywnie na cały crawl budget.
Tak namierzone duplikaty konsolidujemy do jednego (zazwyczaj lepiej pozycjonującego się) adresu URL.
3. Sprawdzamy, jak wiele jest adresów mających noindex. Jak wiemy, Google w dalszym ciągu może się po nich poruszać, po prostu nie wyświetlają się w wynikach organicznych. Staramy się maksymalnie zmniejszyć udział adresów z noindex w strukturze serwisu.
- Przykład – blog wykorzystujący tagi w swojej strukturze, argumentując to wygodą użytkownika. Każdy wpis posiada 3 do 5 tagów, które są prowadzone nieskładnie i jednocześnie nie są indeksowane. Analiza logów wykazuje, że to trzecia najczęściej crawlowana struktura w serwisie.
4. Przegląd robots.txt. Pamiętamy, że zastosowanie robots.txt nie oznacza, że Google nie wyświetli adresu w indeksie.
- Sprawdzamy, które z blokowanych struktur adresów są nadal crawlowane i czy czasami ich wycięcie w ten sposób nie powoduje problemu wąskiego gardła.
- Usuwamy nieaktualne/niepotrzebne reguły.
5. Analizujemy, jak dużo adresów wewnątrz serwisu nie jest kanonicznych. Sam znacznik rel=”canonical” przestał być twardą dyrektywą dla Google i w bardzo wielu sytuacjach jest całkowicie ignorowany przez wyszukiwarkę (parametry sortowania ciągle w indeksie – koszmar).
6. Analiza filtrowania – mechanika działania. Filtrowanie listingów to największy koszmar w pracy nad crawl budget strony. Właściciele sklepów internetowych upierają się, by filtry mogły być dowolnie ze sobą kombinowane (np. kolor z materiałem, ceną, rozmiarem i dostępnością – i tak n-razy). Nie jest to optymalne rozwiązanie i należy dążyć do minimalizacji takich sytuacji.
7. Architektura informacji w serwisie – z uwzględnieniem celów biznesowych, potencjału budowy ruchu i obecnego podlinkowania. Kierujemy się zasadą, że to, co najważniejsze dla nas biznesowo powinno zostać podlinkowane sitewide (link wyświetlany na wszystkich podstronach) lub ze strony głównej. Założenie to jest mocno uproszczone na potrzeby artykułu, ale strona główna i top menu/sitewide linki to najmocniejszy wskaźnik w budowaniu wartości z linkowania wewnętrznego. Jednocześnie staramy się maksymalnie dobrze rozciągnąć site domeny: dążymy do sytuacji, w której nieważne, z której podstrony zaczniemy crawlować domenę, powinniśmy dotrzeć do takiej samej ilości podstron w serwisie (każdy URL powinien mieć PRZYNAJMNIEJ jeden link wewnętrzny kierujący do siebie).
- Praca z architekturą informacji to jeden z najważniejszych elementów optymalizacji crawl budget. To dzięki niej możemy odzyskać zasoby robota z jednego miejsca i przekierować je w inne. Jest to także jeden z najcięższych procesów, ponieważ wymaga włączenia w całość interesariuszy biznesowych – niejednokrotnie prowadząc do batalii i kwestionowania rekomendacji SEO.
8. Renderowanie zawartości. Kluczowe w przypadku serwisów, które całe linkowanie wewnętrzne próbują oprzeć o systemy rekomendacji na podstawie zachowania userów. Przede wszystkim znaczna ich część działa w oparciu o wykorzystywanie ciastek. Google nie zapisuje cookies, więc nie może podlegać personalizacji = nie widzi zawartości/widzi to samo.
- Częsty błąd to blokowanie kluczowej zawartości JS/CSS dla robota Google. W ten sposób mogą pojawić się problemy z indeksowaniem podstron (a także Google będzie marnować czas na renderowanie niedostępnej zawartości).
9. Wydajność strony – Core Web Vitals. O ile nie wierzę w duży wpływ CWV na pozycję strony (za duża różnorodność urządzeń na rynku, nie wszędzie wysoka jakość połączenia internetowego itd.) to jest to jeden z lepszych wskaźników do rozmów z programistami.
10. Sitemap.xml – czy działa oraz czy zawiera wszystkie najważniejsze elementy (same kanoniczne adresy URL odpowiadające kodem 200).
- W pracy z sitemap.xml rekomenduję przede wszystkim podział ich ze względu na typ podstron lub - jeśli to możliwe - kategorię. W ten sposób mamy pełną kontrolę nad tym czy i jak radzi sobie Google z odczytem i indeksowaniem zawartości.

Lukasz Rogala
Gdy zaczynał interesować się SEO ponad 10 lat temu nie przypuszczał, że początkowo przelotny romans przerodzi się w namiętne uczucie i cudowną relację. I chociaż SEO potrafi dać w kość swoją nieprzewidywalnością to pomimo upływu lat uczucie nie słabnie. Fan technicznego SEO, które jest przede wszystkim SKALOWALNE. Entuzjasta dobrego (SEO Friendly) contentu oraz nietypowych działań związanych z pozyskiwaniem linków. Administrator grupy "seowcy" na Facebooku.
Wszystkie artykuły →