 Łukasz Rogala
Łukasz Rogala Crawl budget analysis is among the job duties of any SEO expert (particularly if they’re dealing with large websites). An important task, decently covered in the materials provided by Google. Yet, as you can see on Twitter, even Google employees downplay the role of crawl budget in gaining better traffic and rankings:
Are they right about this one?
How does Google work and collect data?
As we broach the topic, let’s recall how the search engine collects, indexes, and organizes information. Keeping these three steps in the corner of your mind is essential during your later work on the website:
Step 1: Crawling. Scouring online resources with the purpose of discovering – and navigating across – all the existing links, files, and data. Generally, Google starts with the most popular places on the Web, and then proceeds to scan other, less trending resources.
Step 2: Indexing. Google tries to determine what the page is about and whether the content / document under analysis constitutes unique or duplicate material. At this stage, Google groups content and establishes an order of importance (by reading suggestions in the rel=”canonical” or rel=”alternate” tags or otherwise).
Step 3: Serving. Once segmented and indexed, the data are displayed in response to user queries. This is also when Google sorts the data as appropriate, by considering factors such as the user’s location.
Important: many of the available materials overlook Step 4: content rendering. By default, Googlebot indexes text content. However, as web technologies continue to evolve, Google had to devise new solutions to stop just “reading” and start “seeing” as well. That’s what rendering is all about. It serves Google to substantially improve its reach among the newly launched websites and expand the index.
Note: Issues with content rendering may be the cause of a failing crawl budget.
What is the crawl budget?
Crawl budget is nothing but the frequency at which the crawlers and search engine bots can index your website, as well as the total number of URLs they can access in a single crawl. Imagine your crawl budget as credits you can spend in a service or an app. If you don’t remember to “charge” your crawl budget, the robot will slow down and pay you fewer visits.
In SEO, “charging” refers to the work put into acquiring backlinks or improving the overall popularity of a website. Consequently, the crawl budget is an integral part of the entire ecosystem of the Web. When you’re doing a good job on the content and the backlinks, you’re raising the limit of your available crawl budget.
In its resources, Google makes no venture to explicitly define the crawl budget. Instead, it points to two fundamental components of crawling which affect the the thoroughness of Googlebot and the frequency of its visits:
- crawl rate limit;
- crawl demand.
What is the crawl rate limit and how to check it?
In most simple terms, the crawl rate limit is the number of simultaneous connections Googlebot can establish when crawling your site. Because Google doesn’t want to hurt user experience, it limits the number of connections to maintain smooth performance of your website/server. In brief, the slower your website, the smaller your crawl rate limit.
Important: Crawl limit also depends on the overall SEO health of your website – if your site triggers many redirects, 404/410 errors, or if the server often returns a 500 status code, the number of connections will go down, too.
You can analyze crawl rate limit data with the information available in Google Search Console, in the Crawl Stats report.
Crawl demand, or website popularity
While crawl rate limit requires you to polish the technical details of your website, crawl demand rewards you for your website’s popularity. Roughly speaking, the bigger the buzz around your website (and on it), the greater its crawl demand.
In this case, Google takes stock of two issues:
- Overall popularity – Google is more eager to run frequent crawls of the URLs which are generally popular on the Internet (not necessarily those with backlinks from the biggest number of URLs).
- Freshness of index data – Google strives to present only the latest information. Important: Creating more and more new content doesn’t mean that your overall crawl budget limit is going up.
Factors affecting the crawl budget
In the previous section, we defined crawl budget as a combination of the crawl rate limit and the crawl demand. Bear in mind that you need to take care of both, simultaneously, to ensure proper crawling (and thus indexing) of your website.
Below you’ll find a simple list of points to consider during crawl budget optimization
- Server – the main issue is performance. The lower your speed, the higher the risk that Google will assign less resources to indexing your new content.
- Server response codes – the bigger the number of 301 redirects and 404/410 errors on your website, the worse indexing results you’ll get. Important: Be on the lookout for redirect loops – every “hop” reduces your website’s crawl rate limit for the next visit of the bot.
- Blocks in robots.txt – if you’re basing your robots.txt directives on gut feeling, you may end up creating indexing bottlenecks. The upshot: you’ll clean up the index, but at the expense of your indexing effectiveness for new pages (when the blocked URLs were firmly embedded within the structure of the entire website).
- Faceted navigation / session identifiers / any parameters in the URLs – most importantly, watch out for the situations where an address with one parameter may be parameterized further, with no restrictions in place. If that should happen, Google will reach an infinite number of addresses, spending all the available resources on the less significant parts of our website.
- Duplicate content – copied content (aside from cannibalization) significantly hurts the effectiveness of indexing new content.
- Thin Content – which occurs when a page has a very low text to HTML ratio. As a result, Google may identify the page as a so-called Soft 404 and restrict indexation of its content (even when the content is meaningful, which may be the case, for instance, on a manufacturer’s page presenting a single product and no unique text content).
- Poor internal linking or lack thereof.
Useful tools for crawl budget analysis
Since there is no benchmark for the crawl budget (which means that it’s hard to compare limits between websites), gear up with a set of tools designed to facilitate data collection and analysis.
Google Search Console
GSC has grown up nicely over the years. During a crawl budget analysis, there are two main reports we should look into: Index Coverage and Crawl stats.
Index Coverage in GSC
The report is a massive data source. Let’s check the information on URLs excluded from the indexing. It’s a great way to understand the scale of the problem you’re facing.
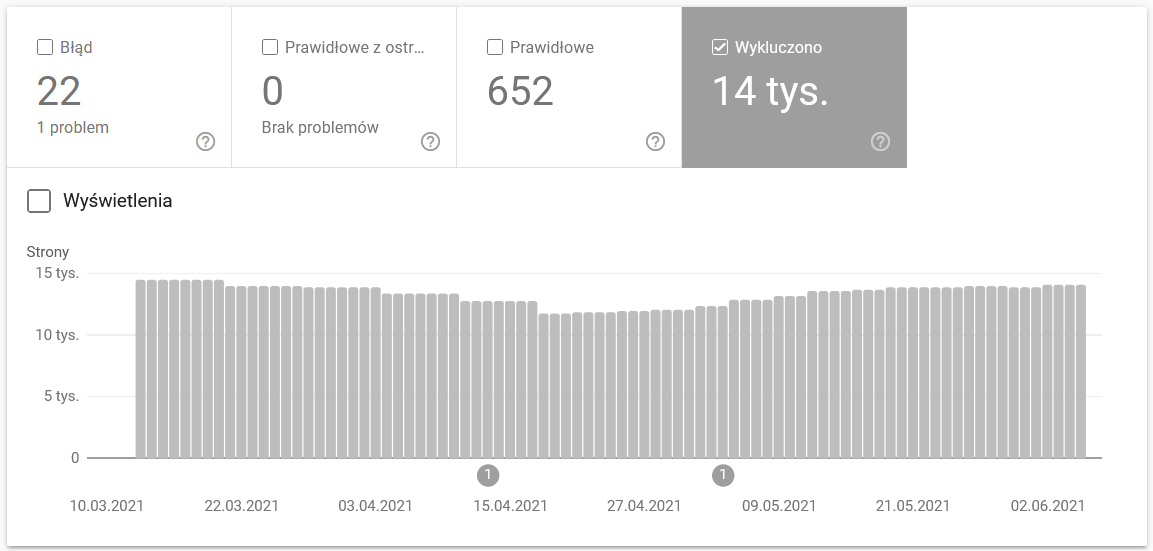
The entire reports warrants a separate article, so for now, let’s focus on the following information:
- Excluded by ‘noindex’ tag – In general, more noindex pages mean less traffic. Which begs the question – what’s the point of keeping them on the website? How to restrict access to these pages?
- Crawled – currently not indexed – if you see that, check if the content renders correctly in the eyes of Googlebot. Remember that every URL with that status wastes your crawl budget because it doesn’t generate organic traffic.
- Discovered – currently not indexed – one of the more alarming problems worth putting at the top of your priority list.
- Duplicate without user-selected canonical – all duplicate pages are extremely dangerous as they not only hurt your crawl budget but also increase the risk of cannibalization.
- Duplicate, Google chose different canonical than user – theoretically, there’s no need to worry. After all, Google should be smart enough to make a sound decision in our stead. Well, in reality, Google selects its canonicals quite randomly – often cutting off valuable pages with a canonical pointing to the homepage.
- Soft 404 – all “soft” errors are highly dangerous as they may lead to the removal of critical pages from the index.
- Duplicate, submitted URL not selected as canonical – similar to the status reporting on the lack of user-selected canonicals.
Crawl stats
The report is not perfect and as far as recommendations go, I strongly suggest playing also with the good old server logs, which give a deeper insight into the data (and more modeling options).
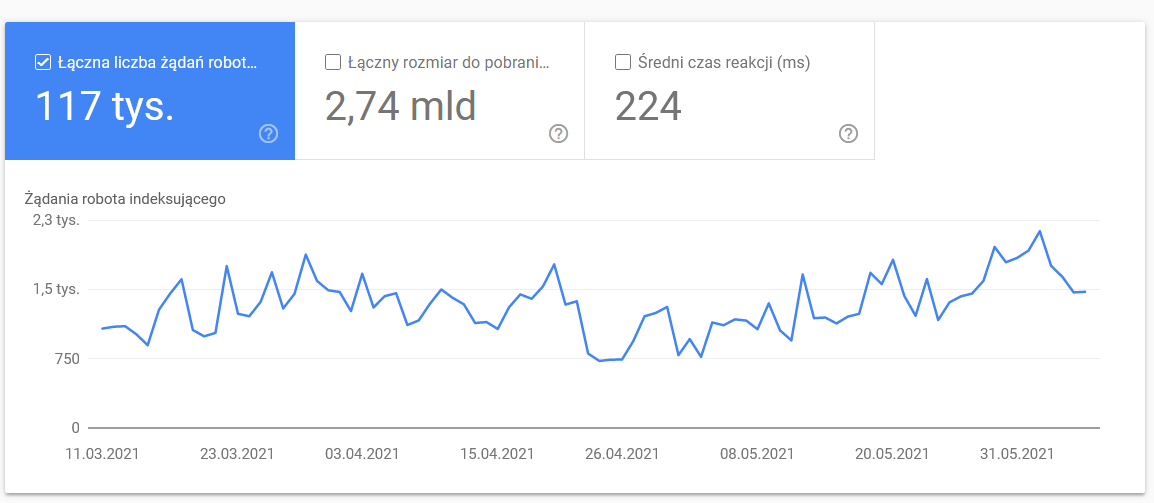
As I’ve already said, you’ll have a hard time searching for benchmarks for the figures above. However, it’s a good call to take a closer look at:
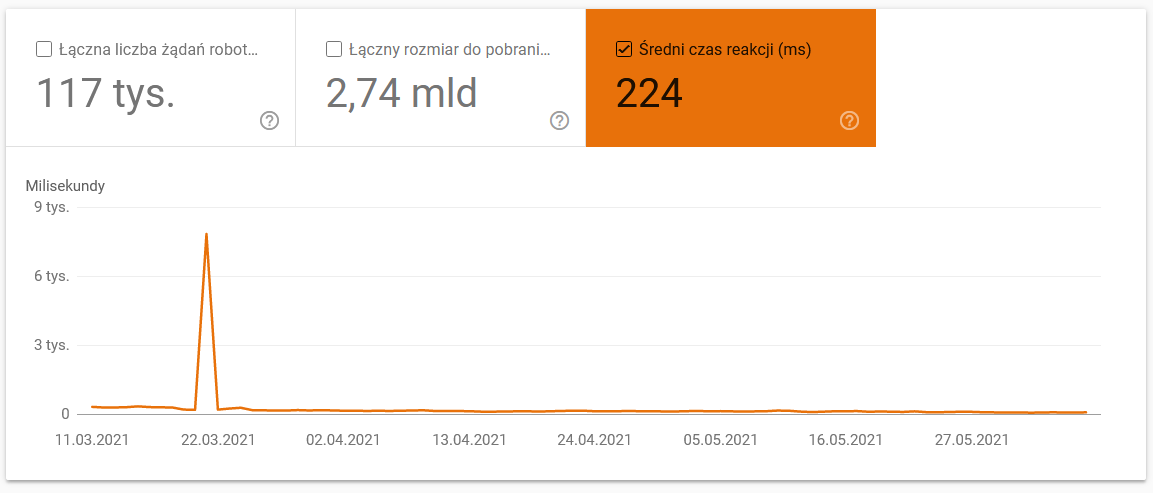
- Average download time. The screenshot below shows that the average response time took a dramatic hit, which was due to server-related problems:
- Crawl responses. Look at the report to see, in general, whether you have a problem with your website or not. Pay close attention to atypical server status codes, like the 304s below. These URLs serve no functional purpose, yet Google wastes its resources on crawling through their contents.

- Crawl purpose. In general, these data largely depend on the volume of new content on the website. The differences between the information gathered by Google and the user can be quite fascinating:
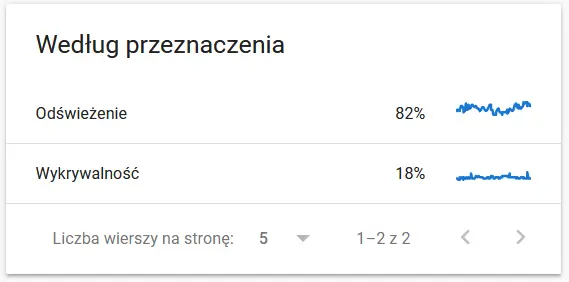
Contents of a recrawled URL in the eyes of Google:
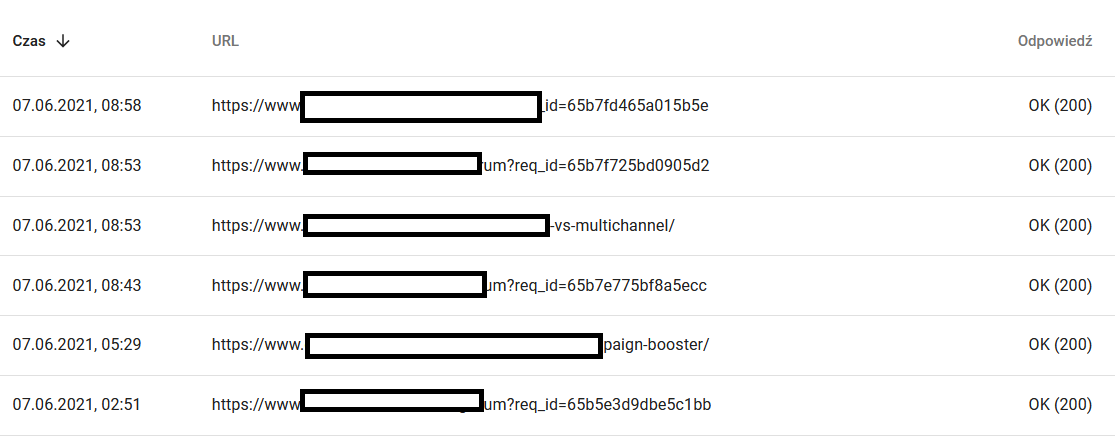
Meanwhile, here’s what the user sees in the browser:
Definitely a cause for thought and analysis : )
- Googlebot type. Here you have the bots visiting your website on a silver platter, together with their motivations for parsing your content. The screenshot below shows that 22% of requests refer to page resource load.
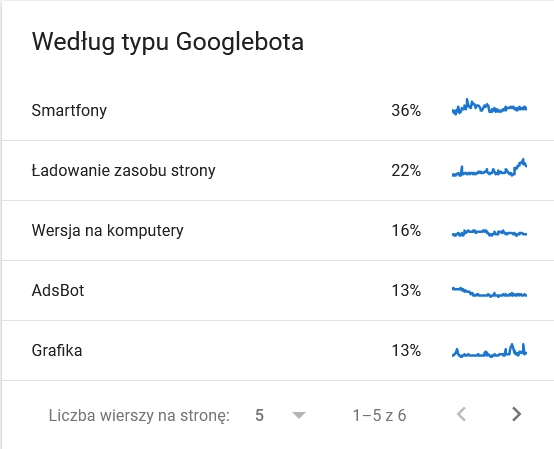
The total ballooned in the last days of the time frame:
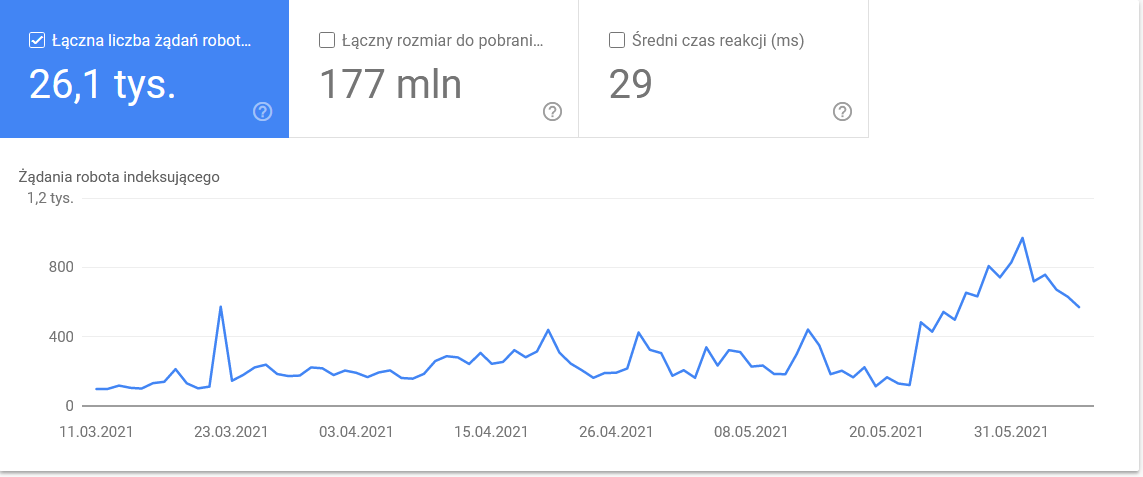
A look at the details reveals the URLs that require closer attention:
External crawlers (with examples from the Screaming Frog SEO Spider)
Crawlers are among the most important tools for analyzing your website’s crawl budget. Their prime purpose is to mimic the movements of crawling bots on the website. The simulation shows you at a glance if everything is going swimmingly.
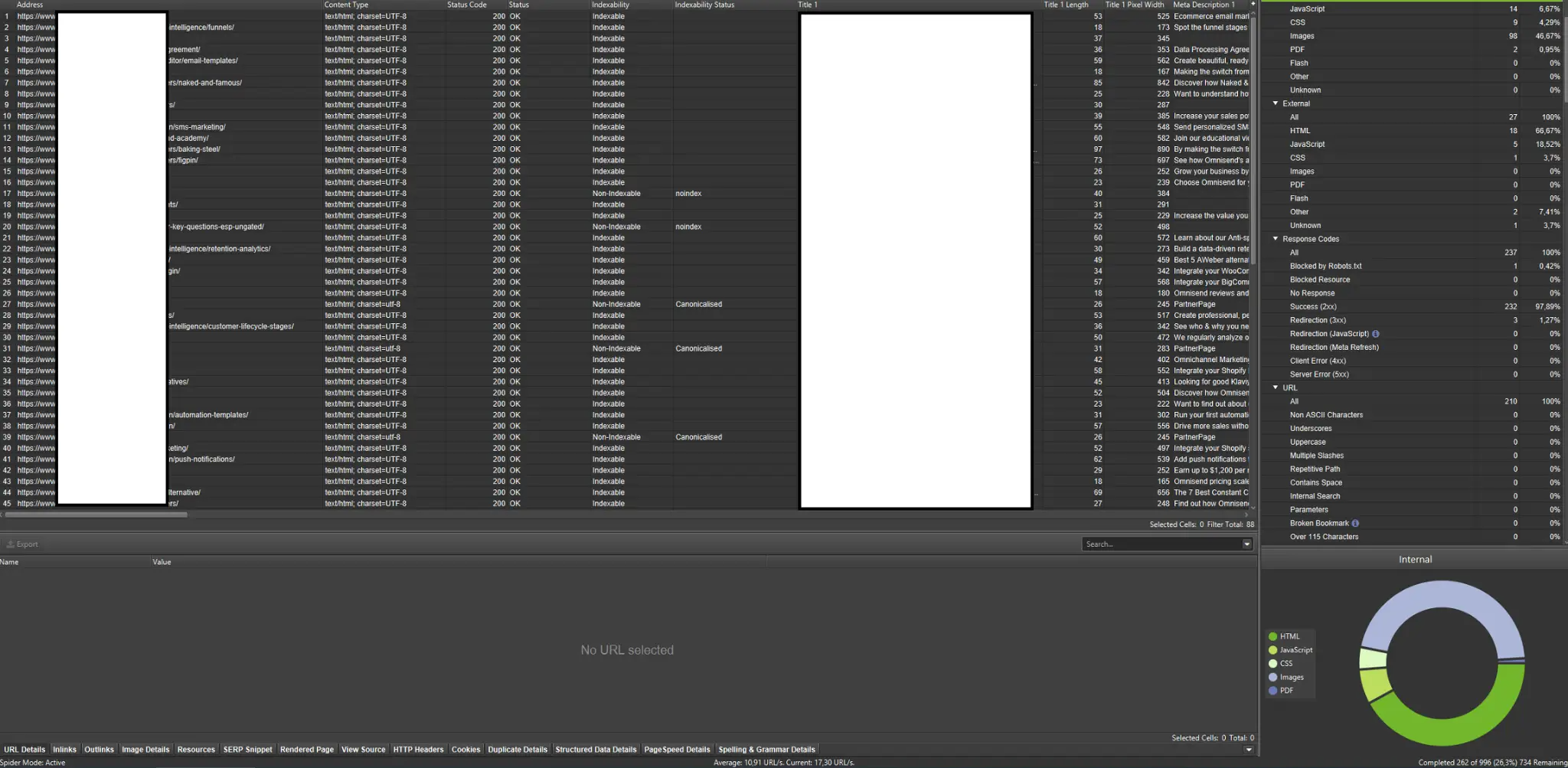
If you’re a visual learner, you should know that most solutions available on the market offer data visualizations.
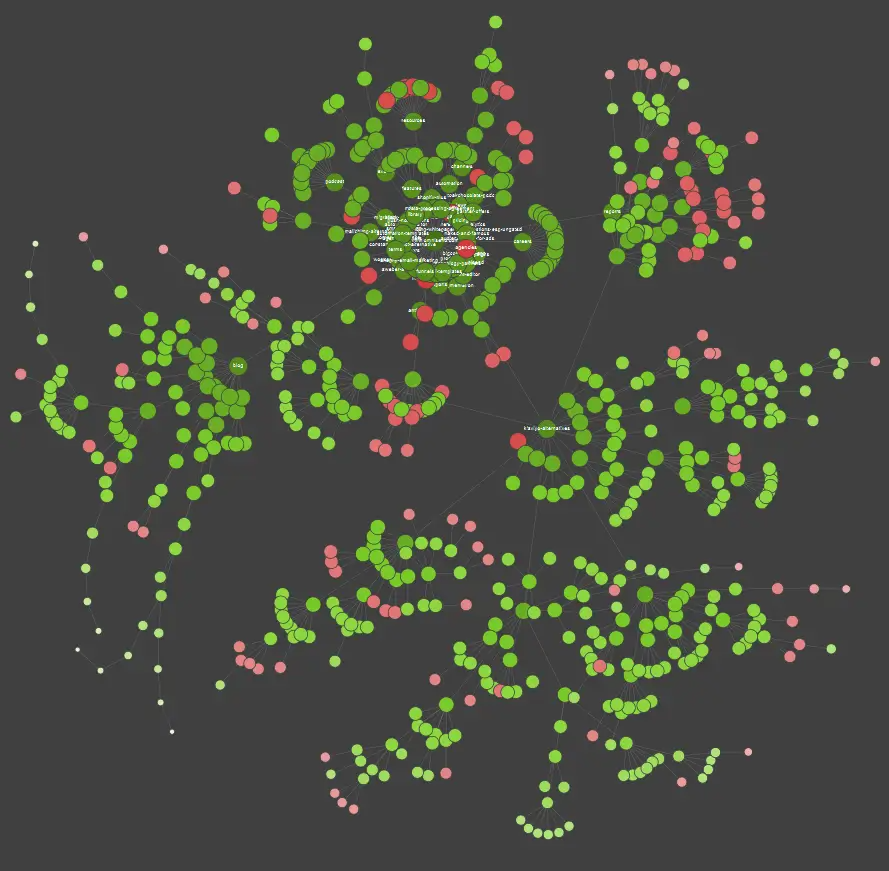
In the example above, the red dots stand for non-indexed pages. Take a while to consider their usefulness and impact on the site’s operation. If server logs reveal that these pages waste a lot of Google’s time while adding no value – it’s time to seriously revisit the point of keeping them on the website.
Important: If we want to recreate the behavior of a Googlebot as accurately as possible, the right settings are a must. Here you can see sample settings from my computer:
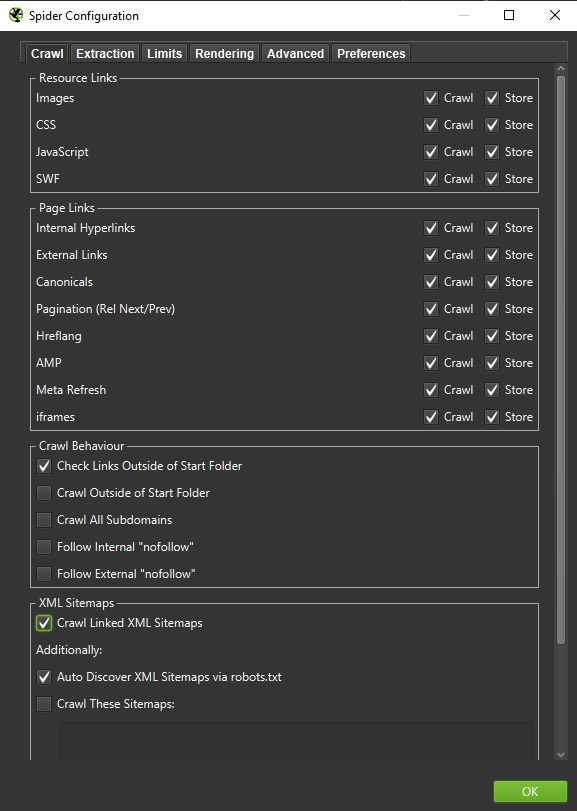
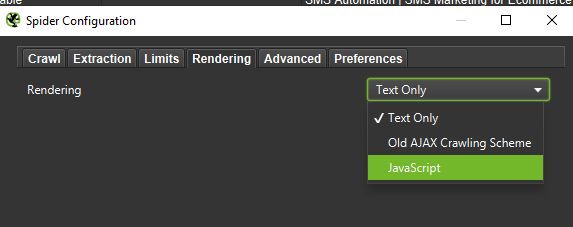
When conducting an in-depth analysis, it’s a good call to test two modes – Text Only, but also JavaScript – to compare the differences (if any).
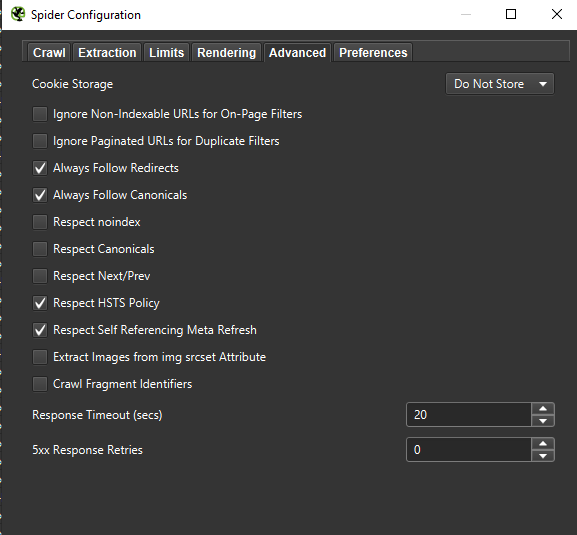
Finally, it never hurts to test the setup presented above on two different user agents:
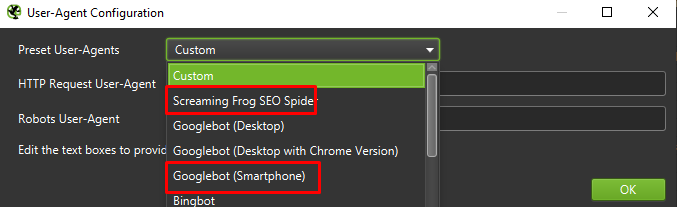
In most cases, you’ll only need to focus on the results crawled / rendered by the mobile agent.
Important: I also suggest to use the opportunity provided by Screaming Frog and feed your crawler with data from GA and Google Search Console. The integration is a quick way to identify crawl budget waste, such as a substantial body of potentially redundant URLs that receive no traffic.
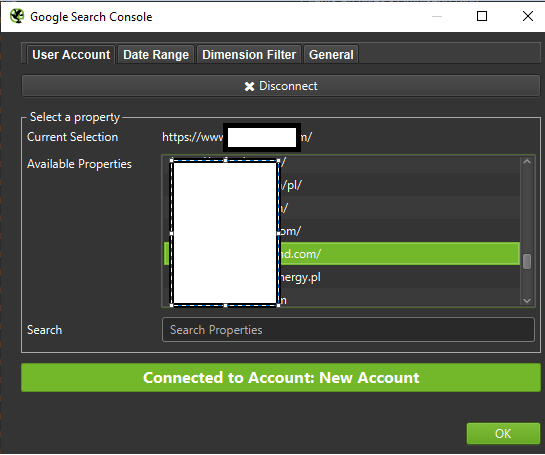
Tools for log analysis (Screaming Frog Logfile and others)
The choice of a server log analyzer is a matter of personal preference. My go-to tool is the Screaming Frog Log File Analyzer. It may not be the most efficient solution (loading a huge package of logs = hanging the application), but I like the interface. The important part is to order the system to display only verified Googlebots.
Tools for visibility tracking
A helpful aid, for they let you identify your top pages. If a page is ranking high for many keywords in Google (= receives a lot of traffic), it may potentially have a bigger crawl demand (check it in the logs – does Google really generate more hits for this particular page?).
For our purposes, we’ll need general reports in Senuto – Paths and URLs – for continued review in the future. Both reports are available in Visibility Analysis, the Sections tab. Have a look:
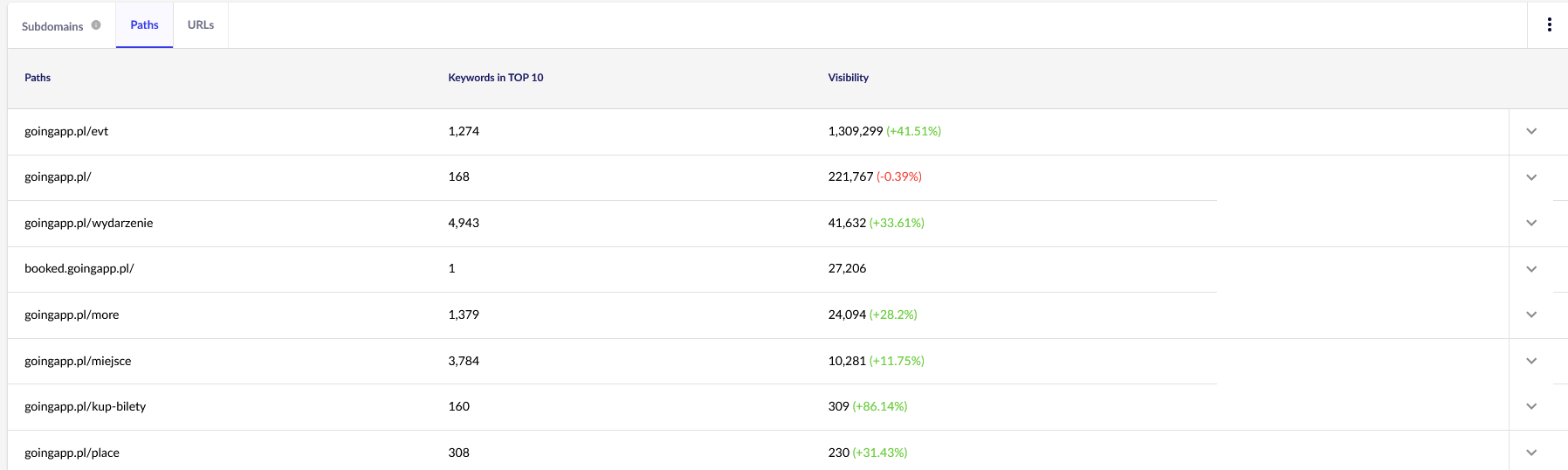
Our main point of interest is the second report. Let’s sort it to look into our keyword visibility (the list and total number of keywords for which our website ranks in the TOP 10). The results will serve us to identify the main axis for the stimulation (and efficient allocation) of our crawl budget.
Tools for backlink analysis (Ahrefs, Majestic)
If one of your pages has a high amount of inbound links, use it as a pillar of your crawl budget optimization strategy. Popular pages can take up the role of hubs which transfer the juice further. Additionally, a popular page with a decent pool of valuable links stands a better chance of attracting frequent crawls.
In Ahrefs, we need the Pages report, and to be exact, its part entitled: “Best by links”:
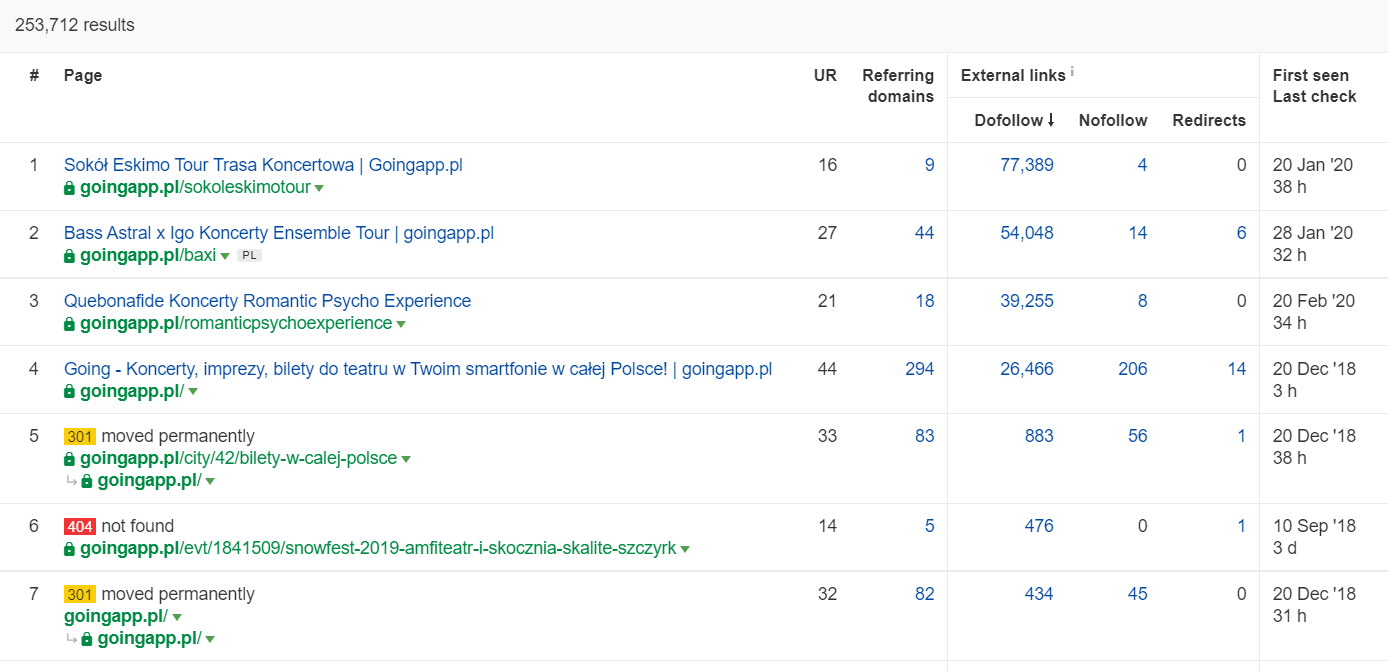
The example above shows that some concert-related LPs continued to generate solid stats for backlinks. Even with all the concerts cancelled because of the pandemic, it still pays off to use historically powerful pages to pique the curiosity of crawling bots and spread the juice to the deeper corners of your website.
What are the telling signs of a crawl budget issue?
The realization that you’re dealing with a problematic (excessively low) crawl budget doesn’t come easy. Why? Principally, because SEO is an extremely complex enterprise. Low ranks or indexing issues may just as well be the consequence of a mediocre link profile or the lack of the right content on the website.
Typically, a crawl budget diagnostic involves checking:
- How much time passes from the publication to the indexation of new pages (blog posts / products), assuming you don’t request indexing through Google Search Console?
- How long does Google keep invalid URLs in its index? Important: redirected addresses are an exception – Google stores them on purpose.
- Do you have pages that get into the index only to drop off later on?
- How much time does Google spend on pages that fail to generate value (traffic)? Go to log analysis to find out.
How to analyze and optimize the crawl budget?
The decision to plunge into crawl budget optimization is mainly dictated by the size of your website. Google suggests that in general, websites of less than 1000 pages shouldn’t agonize about making the most of their available crawl limits. In my book, you should start fighting for more efficient and effective crawling if your website includes more than 300 pages and your content is dynamically changing (for instance, you keep adding new pages / blog posts).
Why? It’s a matter of SEO hygiene. Implement good optimization habits and sound crawl budget management in the early days, and you’ll have less to rectify and redesign in the future.
Crawl budget optimization. A standard procedure
In general, the work on craw budget analysis and optimization consists of three stages:
- Data collection, which is the process of compiling everything we know about the website – from both webmasters and external tools.
- Visibility analysis and the identification of low hanging fruits. What runs like clockwork? What could be better? What areas have the highest potential for growth?
- Recommendations for the crawl budget.
Data collection for a crawl budget audit
1. A full website crawl performed with one of the commercially available tools. The goal is to complete a minimum of two crawls: the first one simulates Googlebot, while the other fetches the website as a default user agent (a browser’s user agent will do). At this stage, you’re interested only in downloading 100% of the content. If you notice that the crawler got into a loop (when, after a day of crawling, we still have only 10% of the website on our hard drive) – let it be known that there’s a problem and you can stop the crawl. A reasonable number of URLs for analysis, in the case of large websites, is around 250–300 thousand pages.
a) What we’re looking for are mainly internal 301 redirects, 404 errors, but also the situations where your texts may be categorized as thin content. Screaming Frog has the option of detecting near duplicate content:
2. Server logs. The ideal time frame should span the last month, however, in the case of large websites, two last weeks may prove sufficient. In the best-case scenario, we should have access to historical server logs to compare the movements of Googlebot at the time when everything was going swimmingly.
3. Data exports from Google Search Console. In combination with points 1 and 2 above, data from Index Coverage and Crawl Stats should give you a quite comprehensive account of all the happenings on your website.
4. Organic traffic data. Top pages as determined by Google Search Console, Google Analytics, as well as Senuto and Ahrefs. We want to identify all the pages that stand out among the crowd with their high visibility stats, traffic volume, or backlink count. These pages should become the backbone of your work on the crawl budget. We’ll use them to improve the crawling of the most important pages.
5. Manual index review. In some cases, the best friend of an SEO expert is a simple solution. In this case: a review of the data taken straight from the index! It’s a good call to check your website with the combo of the inurl: + site: operators.
Finally, we need to merge all the collected data. Typically, we’ll use an external crawler with features allowing for external data imports (GSC data, server logs, and organic traffic data).
Visibility analysis and low hanging fruits
The process warrants a separate article, but our goal today is to get a bird’s eye view of our objectives for the website and the progress made. We’re interested in everything out of the ordinary: sudden traffic drops (that cannot be explained by seasonal trends) and the concurrent shifts in organic visibility. We’re checking which groups of pages are the strongest because they’ll become our HUBS for pushing Googlebot deeper into our website.
In the perfect world, such a check should cover the entire history of our website since its launch. However, as the volume of data keeps growing every month, let’s focus on analyzing the visibility and organic traffic from the last 12-month period.
Crawl budget – our recommendations
The activities listed above will differ depending on the size of the optimized website. However, they’re the most important elements that I always consider when performing a crawl budget analysis. The overriding goal is to eliminate the bottlenecks on your website. In other words, to guarantee maximum crawlability for Googlebots (or other indexing agents).
1. Let’s start from the basics – the elimination of all sorts of 404/410 errors, the analysis of internal redirects and their removal from internal linking. We should conclude our job with a final crawl. This time, all links should return a 200 response code, with no internal redirects or 404 errors.
- At this stage, it’s a good idea to rectify all the redirect chains detected in the backlink report.
2. After the crawl, make sure that our website structure is free from glaring duplicates.
- Check against potential cannibalization as well – apart from the problems arising from targeting the same keyword with multiple pages (in brief, you stop controlling which page will get displayed by Google), cannibalization negatively affects your entire crawl budget.
- Consolidate the identified duplicates into a single URL (usually the one that ranks higher).
3. Check how many URLs have the noindex tag. As we know, Google can still navigate across those pages. They just don’t show up in the search results. We’re trying to minimize the share of noindex tags in our website structure.
- Case in point – a blog organizes its structure with tags; the authors claim that the solution is dictated by user convenience. Every post is labelled with 3–5 tags, assigned inconsistently and not indexed. Log analysis reveals that it’s the third most crawled structure on the website.
4. Review robots.txt. Remember that implementing robots.txt doesn’t mean that Google won’t display the address in the index.
- Check which of the blocked address structures are still getting crawled. Maybe cutting them off is causing a bottleneck?
- Remove the outdated/unnecessary directives.
5. Analyze the volume of non-canonical URLs on your website. Google ceased to regard rel=”canonical” as a hard directive. In many cases, the attribute is downright ignored by the search engine (sorting parameters in the index – still a nightmare).
6. Analyze filters and their underlying mechanism. Filtering the listings is the biggest headache of crawl budget optimization. Ecommerce business owners insist on implementing filters applicable in any combination (for instance, filtering by color + material + size + availability… to the umpteenth time). The solution is not optimal and should be limited to the minimum.
7. Information architecture on the website – one that considers business goals, traffic potential, and current link profile. Let’s work on the assumption that a link to the content critical for our business goals should be visible sitewide (on all pages) or on the homepage. We’re simplifying here, of course, but the homepage and top menu / sitewide links are the most powerful indicators in building value from internal linking. At the same time, we’re trying to achieve the optimal domain spread: our goal is the situation where we can start the crawl from any page and still reach the same number of pages (every URL should have one incoming link AT THE MINIMUM).
- Working towards a robust information architecture is one of the key elements of crawl budget optimization. It allows us to free some of the bot’s resources from one location and redirect them to another. It’s also one of the biggest challenges, for it requires the cooperation of business stakeholders – which often leads to huge battles and criticism undermining the SEO recommendations.
8. Content rendering. Critical in the case of websites aiming to base their internal linking on recommender systems capturing user behavior. Above all, most of these tools rely on cookie files. Google doesn’t store cookies, so it doesn’t get customized results. The upshot: Google always sees the same content or no content at all.
- It’s a common mistake to prevent Googlebot from accessing critical JS/CSS content. This move may lead to issues with page indexing (and waste Google’s time on rendering unavailable content).
9. Website performance – Core Web Vitals. While I’m skeptical about the impact of CWV on site rankings (for many reasons, including the diversity of commercially available devices and the varying speeds of the Internet connection), it’s one of the parameters most worth discussing with a coder.
10. Sitemap.xml – check if it works and contains all the key elements (nothing but canonical URLs returning a 200 status code).
- My first recommendation for optimizing sitemap.xml is to divide your pages by type or – when possible – category. The division will give you full control over Google’s movements and indexation of the content.