Semantyczne SEO. Poznaj, jak naprawdę działa Google i wykorzystaj to dla wyższych pozycji

Pojęcia takie jak semantyka, intencje czy topical authority dominują dziś większość wystąpień na konferencjach SEO. Działanie wyszukiwarek ewoluuje w bardzo szybkim tempie i jeśli nie chcesz zostać z tyłu – musisz nadążać za zmianami, rozumieć najnowsze trendy i przekuwać tę wiedzę na skuteczne działania.
Ten artykuł ma za zadanie Ci w tym pomóc.
Dzięki zawartym tu odwołaniom do patentów Google oraz analizom algorytmów i modeli językowych zrozumiesz, czym jest semantyczne SEO.
Oprócz wiedzy teoretycznej znajdziesz tu także praktyczne wskazówki i porady, które zastosujesz w swoich działaniach SEO oraz pisaniu treści skrojonych pod oczekiwania Google (i użytkowników).
Z lektury tekstu dowiesz się między innymi:
- Jak historycznie zmieniały się wyszukiwarki, aby dojść do wersji, które znamy dzisiaj,
- Jakich modeli językowych używa dziś Google do lepszego rozumienia zapytań użytkowników,
- Czym jest semantyczne SEO i dlaczego jest tak istotne dla optymalizacji pod wyszukiwarki,
- Czym jest intencja użytkownika i w jaki sposób Google stara się ją zaspokajać,
- Czym są entities i jaki mają wpływ na SEO,
- Co to jest topical authority i w jaki sposób działa,
- Czym są klastry tematyczne i jak je tworzyć,
- Czym są huby contentowe i jak je tworzyć,
- Jak tworzyć treści i serwisy zgodne z zasadami semantycznego SEO,
- Jaka jest przyszłość semantycznego SEO i jak się na nią przygotować.
Do czego przyda Ci się wiedza o semantycznym SEO?
Jeśli jesteś:
- Specjalistą SEO: zawarta tu wiedza pomoże Ci tworzyć skuteczniejsze strategie SEO, zwłaszcza w obszarze architektury informacji i treści w serwisie.
- **Content marketerem / SEO copywriterem:**wiedza o semantycznym SEO rzuci nowe światło na Twoją pracę – wykorzystasz ją do tego, by pisać lepsze (skuteczniejsze) treści.
- Marketingowcem: zrozumiesz, jak zaawansowanym narzędziem są dzisiejsze wyszukiwarki i w jaki sposób możesz odpowiedzieć na ich potrzeby.
Jeśli nie należysz do żadnej z wymienionych grup, ale SEO jest w obszarze Twoich zainteresowań, to również znajdziesz tu interesujących dla siebie zagadnień.
Zachęcam również do obejrzenia webinaru o semantycznym SEO, w którym omawiam kluczowe zagadnienia związane z tematem.
Nota od autora:
W 2016 napisałem artykuł o jednym z kluczowych pojęć w semantycznym SEO, jakim jest topical authority (znajdziesz go tu). Od tego czasu został on przeczytany ponad 100 tysięcy razy i nadal jest jednym z najpopularniejszych wpisów na naszym blogu. Sześć lat w SEO to bardzo dużo. Wyszukiwarki poczyniły w tym czasie ogromne postępy, świadomość branży SEO na opisywane przeze mnie zagadnienia również uległa drastycznej zmianie. Doszedłem więc do wniosku, że to dobry czas aby zaktualizować i poszerzyć mój poprzedni artykuł o nową wiedzę.
Czym jest semantyczne SEO?
Aby zrozumieć, czym jest semantyczne SEO, zacznijmy od wyjaśnienia, czym jest semantyczna wyszukiwarka.
Semantyczna wyszukiwarka to taka, która rozumie znaczenie, intencję i kontekst zapytania użytkownika. Taką wyszukiwarką od mniej więcej 2013 roku jest Google.
Wcześniej o Google można było mówić jako o wyszukiwarce leksykalnej, która wyszukiwała za pomocą dopasowań zapytań do dokumentów – bez rozumienia znaczenia tych zapytań. Z punktu widzenia użytkownika, jej działanie było więc niedoskonałe.
Właśnie w odniesieniu do semantycznego sposobu działania wyszukiwarki powstało pojęcie semantycznego SEO. W zależności od źródła semantyczne SEO definiowane jest nieco inaczej – nie zdziw się, jeśli napotkasz na nieco inną definicję niż poniższa:
Semantyczne SEO to sposób prowadzenia działań SEO skupiający się na rozumieniu intencji użytkownika i mający na celu w pełni zaspokoić tę intencję. Odbywa się to poprzez dostarczanie w treści wszystkich odpowiedzi, których użytkownik może poszukiwać, w formie, w której ich szuka. Semantyczne SEO skupia się na holistycznym (całościowym) podejściu do optymalizacji treści i architektury informacji serwisu.
W dalszej części artykułu zapoznam Cię z pojęciami, technikami, modelami i wszystkim co wiąże się z semantyczną wyszukiwarką i semantycznym SEO.
Jak czytać artykuł o semantycznym SEO?
Pamiętaj, że prezentowane w tekście patenty i sposób ich działania nie obrazują rzeczywistego działania wyników wyszukiwania.
Google może aktualnie używać trochę innych technik niż te, które są opisane w wymienionych patentach – nie mamy oficjalnej, w pełni aktualnej wiedzy na temat sposobu działania wyszukiwarki. Zwłaszcza przy tak szybkim rozwoju sztucznej inteligencji.
Jeśli nawet któryś z prezentowanych tu patentów nie jest obecnie używany, nie znaczy to, że nie warto go znać, gdyż sama metodologia działania nie uległa dużym zmianom.
Google mógł zmienić model językowy wykorzystywany do analizy, ale nie zmienił sposobu oceny określonych parametrów (np. inaczej analizuje tekst, ale bierze pod uwagę te same parametry do jego oceny).
Jeśli niektóre części tego artykułu będą dla Ciebie zbyt trudne do zrozumienia z uwagi na wiedzę techniczną, przejdź do sekcji z poradami praktycznymi. Nie musisz rozumieć wszystkich patentów Google, żeby osiągać dobre pozycje w wynikach wyszukiwania.
Historia. Droga do semantycznej wyszukiwarki
Dla pełnego zrozumienia zagadnień, które będę tu opisywać, warto znać historię zmian w wyszukiwarce Google. Dla specjalistów SEO z dużych bagażem doświadczeń nie będą to rzeczy nowe, jeśli jednak w SEO jesteś krócej niż 10 lat, ta wiedza może być dla Ciebie nowa.
O historii SEO w trochę innym kontekście rozmawiałem też w jednym z moich odcinków podcastu, którego gościem był Robert Niechciał. Jeśli interesuje Cię historia wyszukiwarki, zachęcam do jego wysłuchania lub obejrzenia.
Dane strukturalne, czyli schema.org (rok 2011)
W 2011 większość dużych wyszukiwarek zaczęło korzystać z dobrodziejstw sztucznej inteligencji, próbując poprawić jakość swoich wyników wyszukiwania. Jednym z istotnych elementów na tej drodze było uruchomienie słownika schema.org, który powstał w 2011 roku z inicjatywy największych wyszukiwarek (Google, Bing, Yahoo!). Opisywanie treści w internecie za pomocą danych strukturalnych umożliwiło wyszukiwarkom znacznie lepsze rozumienie zawartości witryn.
Za pomocą danych strukturalnych opisać można takie elementy jak: media, wydarzenia, organizacje, osoby, miejsca i wiele więcej. Obecnie można w ten sposób nadać tysiące unikatowych cech informacjom umieszczonych na stronach www.
Z tego standardu korzysta dziś większość większych stron www. Dzięki temu wyszukiwarki mają do dyspozycji ogromną bazę danych, która umożliwia dalszy rozwój algorytmów. Więcej o tych algorytmach będzie w dalszej części artykułu.
Dane strukturalne można opisywać w trzech różnych formatach:

źródło: https://developers.google.com/search/docs/advanced/structured-data/intro-structured-data?hl=pl
Tak wygląda przykładowy opis w formacie JSON-LD, który można by było umieścić na stronie poświęconej Johnowi Lennonowi:
{
"@context": "https://json-ld.org/contexts/person.jsonld",
"@id": "http://dbpedia.org/resource/John_Lennon",
"name": "John Lennon",
"born": "1940-10-09",
"spouse": "http://dbpedia.org/resource/Cynthia_Lennon"
}Ze standardem schema.org możemy zetknąć się bezpośrednio w wynikach wyszukiwania.
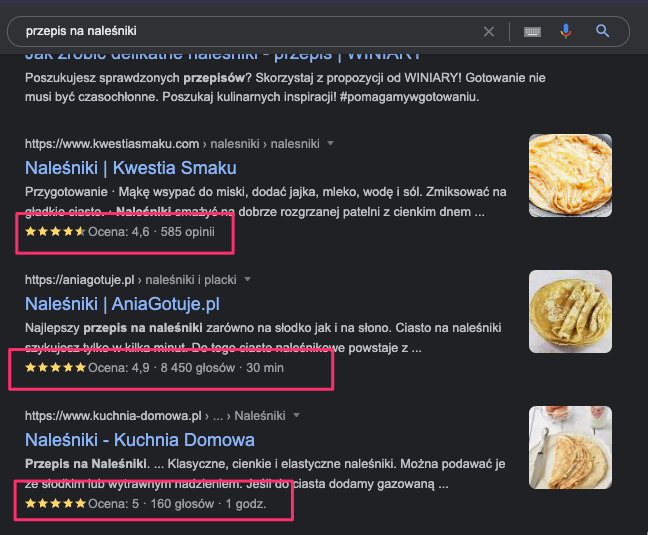
Zaznaczone na zrzucie ekranu elementy (oceny użytkowników) są to wyniki rozszerzone, do których dane pochodzą z danych strukturalnych opisanych standardem Schema.
Za pomocą narzędzia do testowania danych strukturalnych można przetestować, jakich dokładnie mikroformatów używa dana witryna.
Kluczem jest tu słowo “ustrukturyzowane” – wyszukiwarki dzięki słownikowi schema.org zaczęły otrzymywać dane w takiej formie, w jakiej oczekiwały jej algorytmy (algorytm wyszukiwarki nie musiał się „domyślać”, że dana strona to np. przepis kulinarny – dostał te dane opisane). W 2011 algorytmy nie do końca radziły sobie z nieustrukturyzowanymi danymi, bez schemy utworzenie semantycznej wyszukiwarki nie byłoby w tamtym okresie możliwe.
Opisanie informacji za pomocą standardu schema.org nie wpływa na pozycję w wynikach wyszukiwania, ale może mieć istotny wpływ na CTR (stosunek liczby kliknięć do wyświetleń). Samo opisanie informacji przy pomocy danych strukturalnych nie gwarantuje również tego, że pojawią się one w wynikach wyszukiwania.
Dodatkowe źródła wiedzy:
- https://developers.google.com/search/docs/advanced/structured-data/intro-structured-data?hl=pl
- https://json-ld.org/
- https://schema.org/
- https://rdfa.info/
- https://html.spec.whatwg.org/multipage/
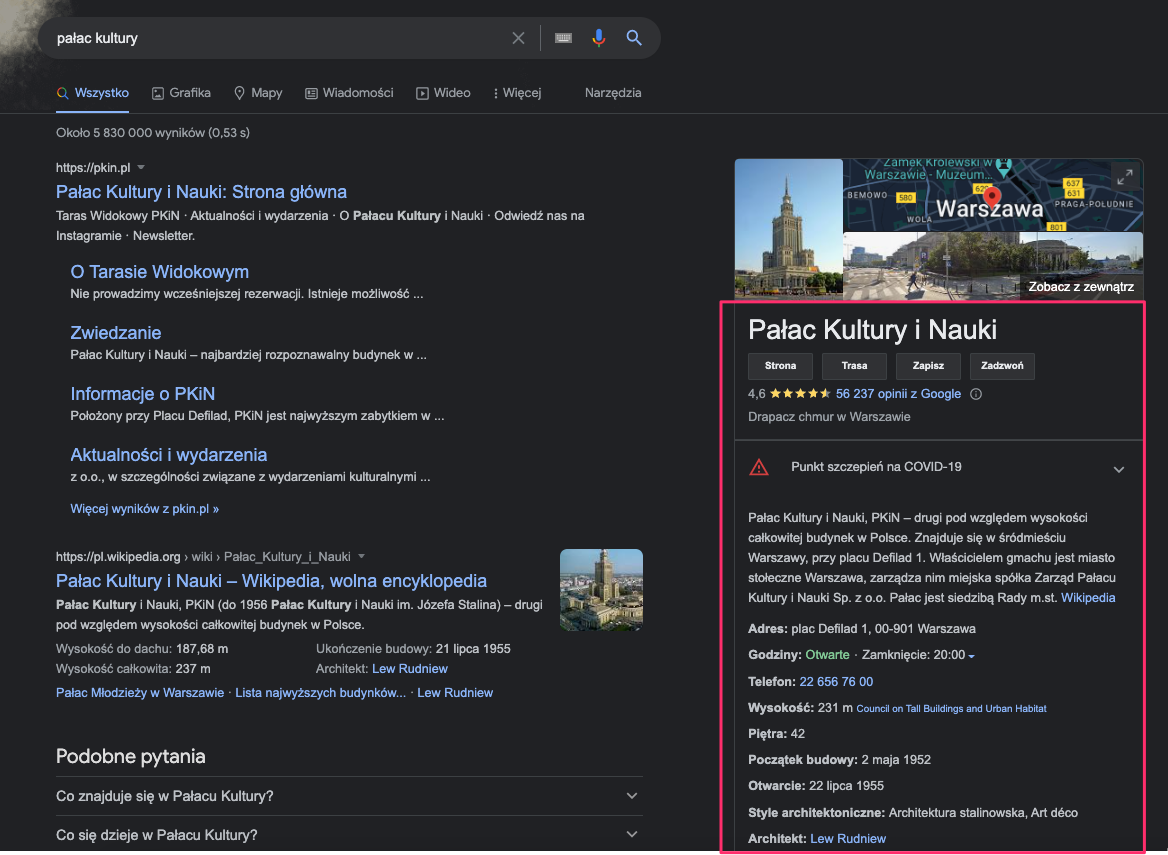
Things not strings – knowledge graph (rok 2012)
Do 2012 algorytmy Google nie rozumiały zapytań. Zapytanie “pałac kultury” dla algorytmu było dwoma słowami. Nie rozumiał on ich znaczenia. Starał się dopasować najlepsze dokumenty z internetu na bazie znanych nam parametrów: optymalizacji metadanych, treści czy linków.
W maju 2012 Google ogłosił wprowadzenie grafu wiedzy (knowledge graph), tytułując tę zmianę: “things, not strings”. Między innymi dzięki danym zebranym z danych strukturalnych (dane pochodziły też z Wikipedii czy CIA World Factbook) algorytm wyszukiwarki zaczął rozumieć znaczenie słów. “Pałac kultury” przestał być zlepkiem dwóch wyrazów, zaczął być miejscem.
Na rok 2012 Google był w stanie rozpoznać 500 milionów miejsc i 3,5 miliarda faktów (dziś ta liczba jest na pewno znacznie większa).
Wideo, na którym Google prezentuje graf wiedzy:
Dla użytkowników wprowadzenie grafu wiedzy skutkowało zmianą wyglądu wyników wyszukiwania. Gdy wyszukujemy miejsc, ludzi czy innych informacji, które są zapisane w grafie wiedzy, Google wyświetla dodatkowe informacje.
Dla specjalistów SEO nie była to korzystna zmiana.
Dla zapytań, w których pojawił się graf wiedzy, współczynnik CTR drastycznie spadł. Na przykład w przypadku zapytania “ile lat ma Maryla Rodowicz” liczba przeklików z Google spadła praktycznie do zera, ponieważ Google zaczął udzielać odpowiedzi bezpośrednio w wynikach wyszukiwania.
Dziś graf wiedzy znajdziemy na 10-12% wyników desktopowych i 15-20% wyników mobilnych (w zależności od rynku).
Wprowadzenie grafu wiedzy nie zmieniło tylko wyglądu wyników wyszukiwania, ale również możliwości Google w zakresie rozumienia treści i intencji użytkownika. Zmiana ta uwydatniła się stopniowo w kolejnych latach.
Algorytm Koliber (rok 2013)

W okresie 2011-2016, kiedy Google wprowadzał do algorytmu kolejne duże zmiany (symbolizowane różnymi zwierzątkami), branża SEO odczuwała niemały strach. Algorytmy takie jak Panda czy Pingwin siały spustoszenie w wynikach wyszukiwania (kiedyś to były update’y!).
W przypadku algorytmu Koliber tak jednak nie było.
Aktualizacja przeszła raczej bez większego echa. Nie zmieniła wyników wyszukiwania z dnia na dzień. W odróżnieniu od takich aktualizacji algorytmów jak Panda i Pingwin, które działały jako dodatek do głównego algorytmu (Pingwin w wersji 4.0 został wprowadzony do głównego algorytmu), aktualizacja Koliber od początku była zmianą w głównym algorytmie wyszukiwarki (stała się częścią jego działania).
Firma Google opisywała, że jest to największa zmiana w algorytmie od 2001 roku. Matt Cutts w jednym z wywiadów zaznaczył, że aktualizacja miała wpływ na 90% wyników wyszukiwania.
Aktualizację Koliber uznajemy za początek semantycznego SEO.
To początki funkcjonowania algorytmów do przetwarzania języka naturalnego (NLP) w wyszukiwarce. Użytkownicy wyszukiwarki w tamtym okresie byli już bardziej świadomi, wpisywali coraz dłuższe zapytania, przypominające język naturalny. Mechanizm działania wyszukiwarki musiał zostać do tej zmiany przystosowany.
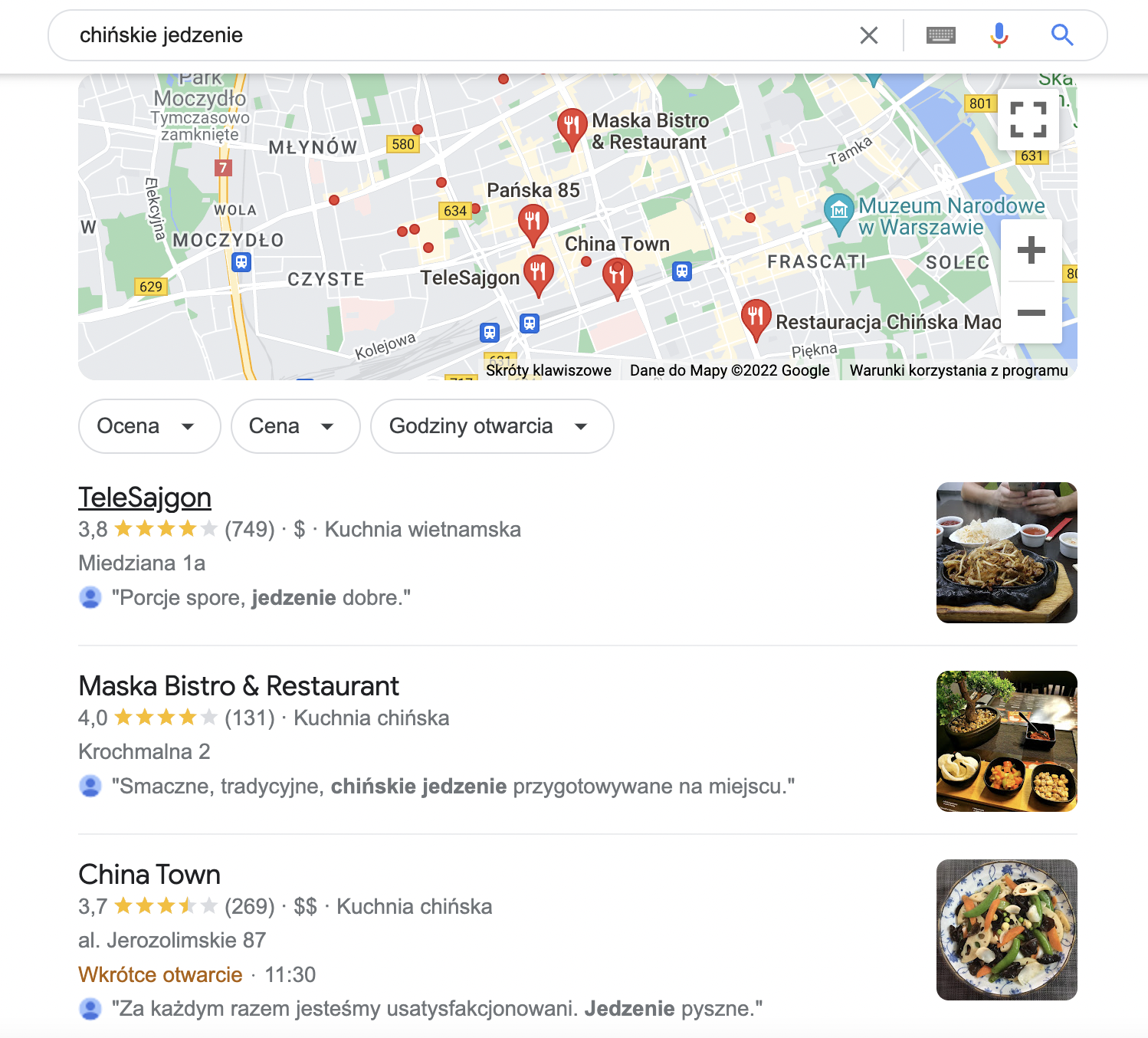
Do momentu wprowadzenia Kolibra wpisanie zapytania “chińskie jedzenie” kierowało by najpewniej do stron z przepisami. Po wprowadzeniu Kolibra użytkownik otrzymywał listę najlepszych restauracji w okolicach.
Sam algorytm największe zmiany poczynił w zapytaniach lokalnych. Od jego wprowadzenia coraz więcej wyników poza standardowymi odnośnikami do witryn internetowych zawierała tak zwany “local pack”, czyli wyniki z Google Moja firma.
Obecnie w zależności od urządzenia i lokalizacji aż około 45% wszystkich wyników zawiera wyniki lokalne.
Rok 2013 to też rok, w którym wyszukiwanie głosowe zaczęło zyskiwać na popularności. Google musiał rozumieć język naturalny, aby odpowiedzieć na tę potrzebę.
Dziś Google korzysta z dużo bardziej zaawansowanych modeli NLP (opisuję je w dalszej części artykułu). 10 lat w technologii, w której rozwój jest wykładniczy, to wieki.
Panda 4.0 (rok 2014)

Aktualizacji algorytmu Panda było kilka (pierwsza w 2011). Jedne dotyczyły kopiowanych treści, inne thin contentu – dzięki Pandzie dziś już każdy specjalista SEO wie, że Google nie lubi kopiowanych i nic nie wnoszących treści.
Panda 4.0 wprowadziła do SEO pojęcie topical authority (będę je dokładnie wyjaśniać w dalszej części), czyli premiowanie witryn, które są eksperckie w danej dziedzinie.
Pierwsze doniesienia dotyczące Pandy 4.0 mówiły o tym, że dotknęła ona 7,5% wszystkich wyników wyszukiwania. Sam Google twierdził, że ta aktualizacja, tak jak poprzednie iteracje Pandy, miała za zadanie walczyć ze spamem. Google nigdy nie potwierdził, że ta aktualizacja zaczęła premiować serwisy eksperckie w danej dziedzinie, ale na to wskazują wszystkie testy i przewidywania ekspertów.
Świetne badanie w tym temacie przeprowadził Razvan Gavrilas z Cognitive SEO.
W okresie wprowadzenia czwartej wersji Pandy, z wyników wyszukiwania zaczęły znikać małe serwisy, które były zoptymalizowane pod ograniczoną liczbę słów kluczowych i nie były eksperckie w swoich dziedzinach. Wyniki zaczęły dominować duże lub wyspecjalizowane w określonych tematach serwisy.
Jak działa Panda 4.0?
Przed okresem Pandy 4.0 różne domeny w wynikach dla dwóch poniższych fraz nie byłyby niczym dziwnym:
- Cukrzyca Typu 1
- Cukrzyca Typu 2
Po wprowadzeniu Pandy 4.0 wyniki dla takich dwóch fraz będą zdominowane przez podobne domeny, gdyż obie frazy należą do tej samej dziedziny wiedzy.
W roku 2014 Google miał już graf wiedzy oraz pierwsze algorytmy do badania intencji. Badał też topical authority. Wyszukiwarka miała już zatem wszystkie składniki tego, co dziś nazywamy semantycznym SEO. Dalsze lata to ewolucja w zakresie tych obszarów i wprowadzanie coraz to bardziej zaawansowanych rozwiązań.
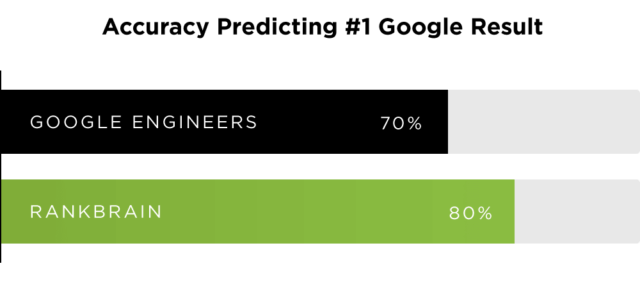
RankBrain (rok 2015)

RankBrain wprowadził niemałe zamieszanie w branży SEO. Trudno żeby było inaczej kiedy jeden z najważniejszych inżynierów w Google Paul Haahr, na konferencji SMX (w 2016 roku) mówi, że sami nie do końca rozumieją, jak działa RankBrain.
RankBrain to pierwszy przejaw działania nienadzorowanej sztucznej inteligencji w wynikach wyszukiwania. I to sztucznej inteligencji samouczącej się, na co wskazują słowa Paula Haahra.
Do momentu wprowadzenia RankBraina wszystkie reguły algorytmów tworzone były przez inżynierów Google – potem regułami potrafiła już zarządzać sztuczna inteligencja (reguły nie są predefiniowane). Wedle badań, RankBrain w 2015 roku przewidywał wyniki o 10 p.p. lepiej od inżynierów.
RankBrain realizuje kilka zadań:
- Rozumienie nowych, nigdy wcześniej nie wpisanych zapytań (według dostępnych badań takie zapytania stanowią 15% wszystkich zapytań)
- Rozumienie długich zapytań (np. tych z voice search)
- Lepsze powiązanie pojęć ze stronami
- Analiza historycznych zachowań użytkownika celem ustalenia jego preferencji co do otrzymanych wyników
Jak RankBrain wpływa na wyniki wyszukiwania?
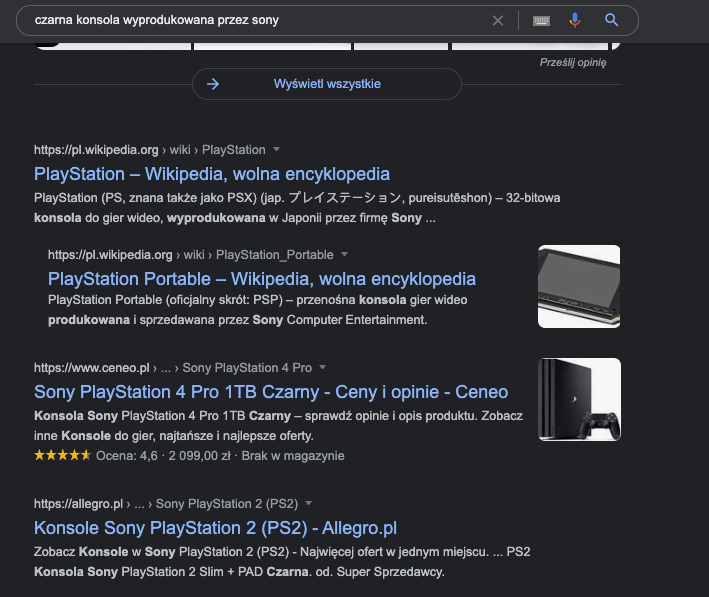
Przykład działania RankBrain można zaobserwować np. przy zapytaniu “czarna konsola wyprodukowana przez sony” – dzięki RankBrain Google wie, że chodzi o PlayStation.
Fakt, że od jakiegoś czasu wyszukiwarka posługuje się pojęciami, a nie frazami (między innymi dzięki RankBrain), wymusił nieco inny sposób podejścia do wyszukiwania słów kluczowych.
Jeśli dwie frazy są do siebie bardzo podobne i realizują tę samą intencję, Google połączy je w jedno pojęcie. Dzięki temu możliwe jest pojawianie się w wynikach wyszukiwania nawet na frazy, które nie występują w treści, a jedna podstrona może być widoczna na tysiące słów kluczowych.
Przykład: „Kalkulator ciąży i terminu porodu” na medonet.pl
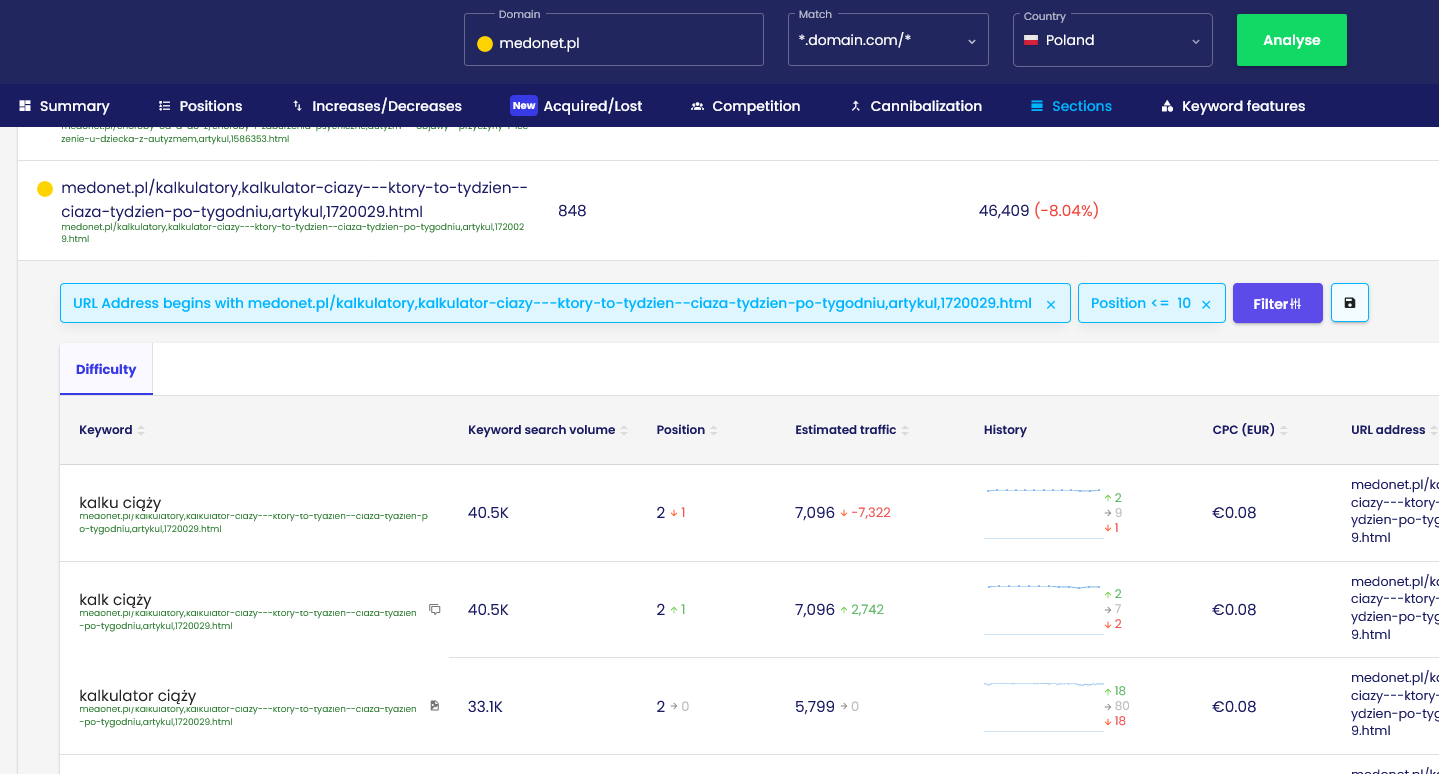
źródło danych: https://app.senuto.com/visibility-analysis/sections?domain=medonet.pl&fetch_mode=subdomain&country_id=1
Ten artykuł widoczny jest aż na 856 słów kluczowych w TOP10, i to nie tylko na takie frazy jak “kalkulator ciąży”, ale również:
- Ile dni trwa ciąża – 1. pozycja
- w którym tygodniu ciąży jestem – 2. pozycja
- data porodu – 6. pozycja
Żadna z tych fraz nie występuje w treści w dosłownym znaczeniu. Przykładów takich fraz w samym tym artykule są dziesiątki.
Czy RankBrain bierze pod uwagę czynniki behawioralne?
W internecie można znaleźć wiele tekstów na temat tego, że RankBrain używa czynników behawioralnych do ustalania rankingu, takich jak CTR czy dwell time. Takie były pierwotne przewidywania branży.
Jednak w 2019 roku odbyło się AMA w serwisie Reddit z Garym Illyesem z Google, w którym odpowiadał między innymi na pytania dotyczące RankBrain. Gary podał kilka ciekawych informacji, które wrzuciły spory znak zapytania do kwestii wykorzystania czynników behawioralnych przez RankBrain:
“RankBrain is a PR-sexy machine learning ranking component that uses historical search data to predict what would a user most likely click on for a previously unseen query.” (RankBrain to komponent rankingu oparty na uczeniu maszynowym, który wykorzystuje historyczne dane wyszukiwania, aby przewidzieć, na co użytkownik najprawdopodobniej kliknie w przypadku wcześniej niewidzianego zapytania.)
“Dwell time, CTR, whatever Fishkin’s new theory is, those are generally made up crap. Search is much more simple than people think.” (Dwell time, CTR, czy jaka tam jest nowa teoria Fishkina, generalnie wszystko to jest bzdura. Wyszukiwanie [w Google] jest znacznie prostsze niż się ludziom wydaje.)
Oczywiście jako branża SEO wiemy, że Google wielokrotnie wypowiada się niejasno na temat działania własnych mechanizmów. Obecnie istnieje zarówno wiele testów potwierdzających tezę, jakoby czynniki behawioralne rzeczywiście miały znaczenie, jak i testów obalających tę tezę.
Google tu podkreśla, że czynniki behawioralne mają znaczenie, ale w obrębie wyników wyszukiwania, a nie samej strony. Nawet jeśli teza niektórych ekspertów SEO jest prawdziwa, to nie musi być to efekt działania RankBrain.
Neural matching (rok 2018)
 Neural matching to rodzaj sieci neuronowej, która funkcjonuje w ramach algorytmu Google.
Neural matching to rodzaj sieci neuronowej, która funkcjonuje w ramach algorytmu Google.
W praktyce Neural matching, wykorzystując sztuczną inteligencję (sieci neuronowe), pozwala wyszukiwarce lepiej zrozumieć relacje zapytanie <> strona, zwłaszcza dla zapytań, które nie mają jednoznacznej intencji.
Te relacje to kluczowy element dla poprawnego działania semantycznej wyszukiwarki – i dla skutecznych działań w zakresie semantycznego SEO.
Google mówi o Neural matching jako o super słowniku synonimów. Wprowadzenie tego elementu to kolejny krok w kierunku lepszego dopasowania wyników do intencji użytkownika.
Z tweeta Danny’ego Sullivana z Google możemy się dowiedzieć, że w tamtym okresie (2018) Neural matching wpłynął na prawie 30% wszystkich zapytań. Dla wielu specjalistów SEO znanym algorytmem jest algorytm TF * IDF – Neural matching jest znacznie bardziej zaawansowanym sposobem rozwiązywania podobnego problemu.
Jak działa Neural matching?
Jak wynika z dokumentu naukowego Google, Neural Matching dopasowuje wyniki tylko i wyłącznie na bazie zapytania i treści serwisu, pomijając wszystkie inne czynniki algorytmiczne. Kiedy algorytm ten był wprowadzany, w branży SEO powstała duża obawa o to, że Google przestanie brać pod uwagę takie czynniki jak linki.
Obawy te okazały się bezzasadne, gdyż działa on jako uzupełnienie dla głównego algorytmu i tylko w obszarze stron, które już znajdują się wysoko w wynikach wyszukiwania.
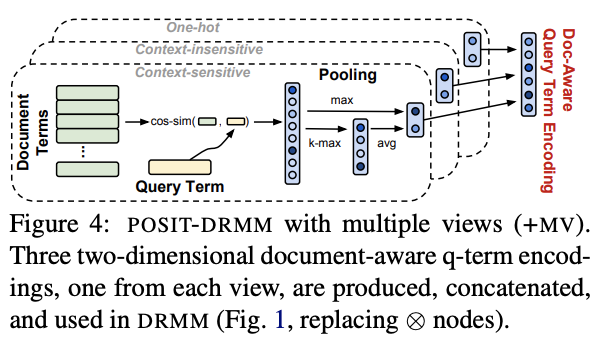
Schemat działania neural matching.
Przykład działania Neural matching można zaobserwować na bazie poniższego zapytania:
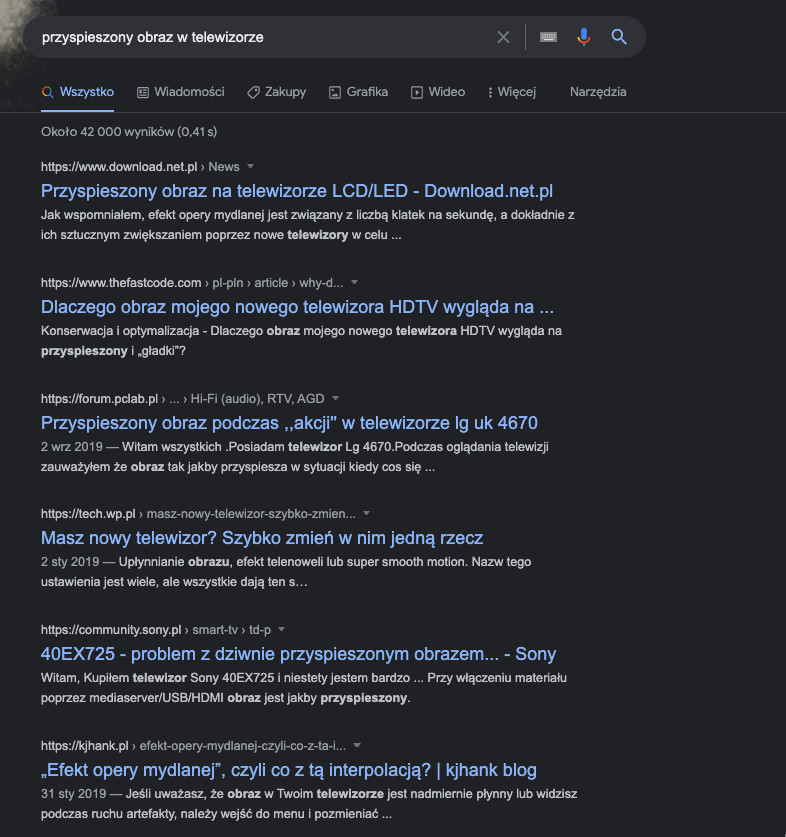
Przyspieszony obraz na telewizorze nazywany jest “efektem opery mydlanej”. Google jest w stanie wykryć to powiązanie dzięki temu, że łączy zapytanie użytkownika z całym dokumentem (stroną).
W efekcie w skrajnych przypadkach w wynikach wyszukiwania mogą się pojawiać strony, które nie zawierają w sobie słów zawartych w zapytaniu.
Może się wydawać, że Neural matching działa na tej samej zasadzie co RankBrain. Między tymi algorytmami jest jednak różnica i Google tłumaczy ją w taki sposób:
- RankBrain pozwala wyszukiwarce łączyć pojęcia ze stronami (przykład PlayStation)
- Neural matching pozwala wyszukiwarce łączyć słowa z pojęciami (przykład Opery mydlanej)
Różnice pomiędzy Neural matching a RankBrain, Google wyjaśniał w jednej z serii tweetów w 2019 roku.
Więcej na temat Neural matching przeczytasz na blogu Google.
BERT (rok 2019)

W październiku 2019 Google wykonał kolejny krok w stronę lepszego rozumienia zapytań i intencji użytkownika.
BERT (Bidirectional Encoder Representations from Transformers) to model językowy, w którego nazwie znajdziemy “Bidirectional”, co jest dość istotne. Oznacza bowiem, że BERT pozwala rozumieć znaczenie słów w relacji do wyrazów, które znajdują się przed i po tym słowie.
BERT to algorytm samouczący się. Potrafi uczyć się na jednym języku i aplikować tę w wiedzę w innym. BERT-a można wytrenować do różnych typów zadań. W machine learningu używa się pojęcia fine tuning (strojenie) w odniesieniu do trenowania modelu do spełniania innych zadań – i to ma właśnie zastosowanie w przypadku BERT-a.
O modelu, który nie rozumiał kontekstu
Dotychczasowe metody wyznaczania semantycznych powiązań, takie jak model Word2Vec, były pozbawione kontekstu.
Word2Vec tworzy jednowyrazowe reprezentacje wektorowe. Dla przykładu słowo “zamek” będzie miało w tym modelu taką samą reprezentację w zapytaniu “zamek z piasku” jak “zamek w malborku”.
W związku z takim działaniem algorytmy tego typu nie są w stanie analizować kontekstu zapytania.
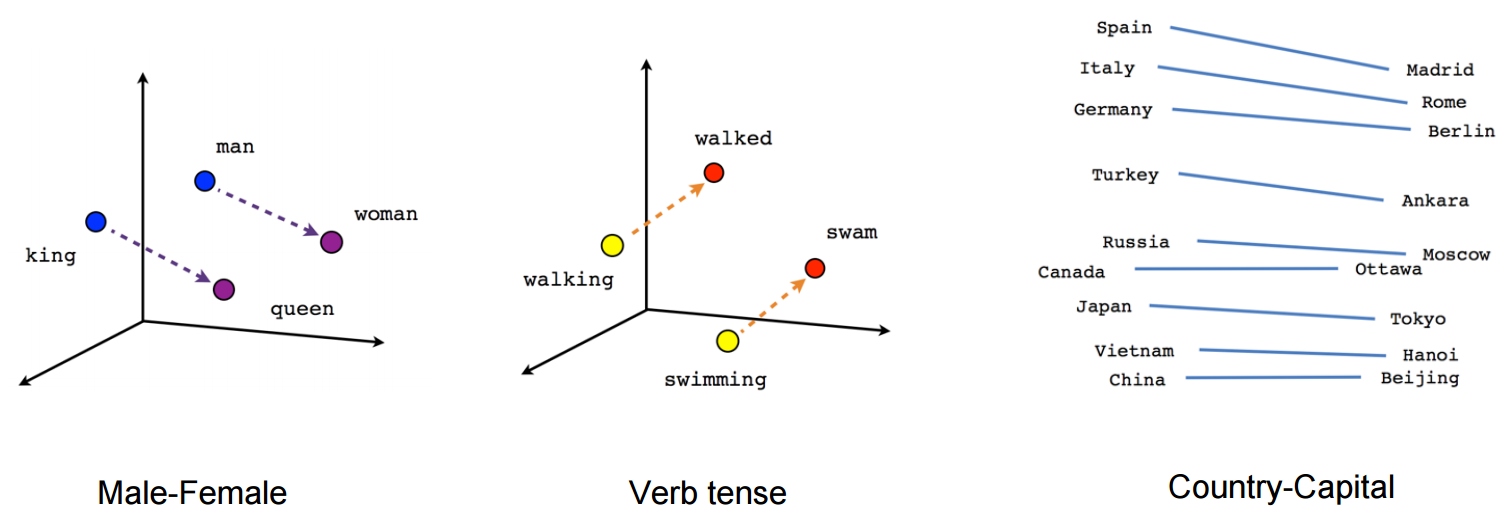
Schemat działania Word2Vec. Źródło: https://israelg99.github.io/2017-03-23-Word2Vec-Explained/
Powyższy przykład pokazuje, że dzięki zamianie słów na wektory model Word2Vec może wyznaczać powiązane ze sobą wyrazy. Są one jednak pozbawione kontekstu.
Jeśli chcesz zobaczyć jak działa model Word2Vec obejrzyj poniższy film:
Działanie modelu Word2Vec możesz sprawdzić na tej stronie.
Jak działa BERT?
Word2Vec to świetny sposób na wyznaczanie słów semantycznie powiązanych ze sobą. W zapytaniach do wyszukiwarki ważne jest jednak każde słowo, każde może zmienić sens zapytania. Tę lukę wypełnia BERT.
Przykład działania BERT-a w wynikach wyszukiwania, zapytanie “2019 czy brazylijski podróżnik potrzebuje wizy do USA”:
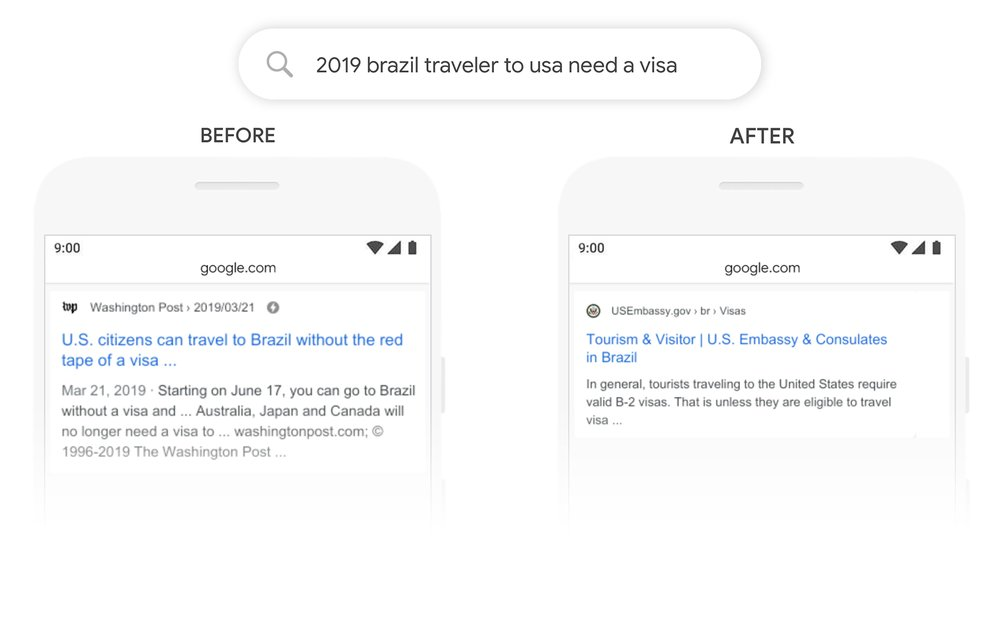
źródło: https://blog.google/products/search/search-language-understanding-bert/
Przed wprowadzeniem BERT-a Google nie rozumiał relacji Brazylia > USA (słowo do jest tu kluczowe) i zwracał w wynikach również informacje dla podróżujących z USA do Brazylii, co było niezgodne z intencją zapytania.
BERT jest wytrenowany też do rozumienia relacji pomiędzy zdaniami.
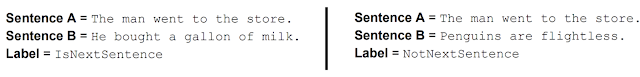
Potrafi on rozpoznać, czy dwa losowe zdania są zdaniami występującymi po sobie.
Skuteczność BERT-a
Google w 2018 wskazywał, że BERT osiąga najlepszą skuteczność ze wszystkich modeli NLP w odpowiadaniu na pytania z bazy danych pytań Stanford (SQuAD2.0).
SQuAD2.0 jest to projekt z bazą ponad 100 tysięcy pytań, w których zawarta jest odpowiedź, a także takich, na które nie da się odpowiedzieć. Skuteczność modeli mierzy się skutecznością odpowiedzi na pytania zawarte we wzmiankowanej bazie.
BERT został uruchomiony w 2019 roku – i, jak widać na poniższym zestawieniu, dziś dostępne są już modele, które lepiej radzą sobie z tym zadaniem (należy pamiętać, że ten test testuje tylko jeden typ zadania!).
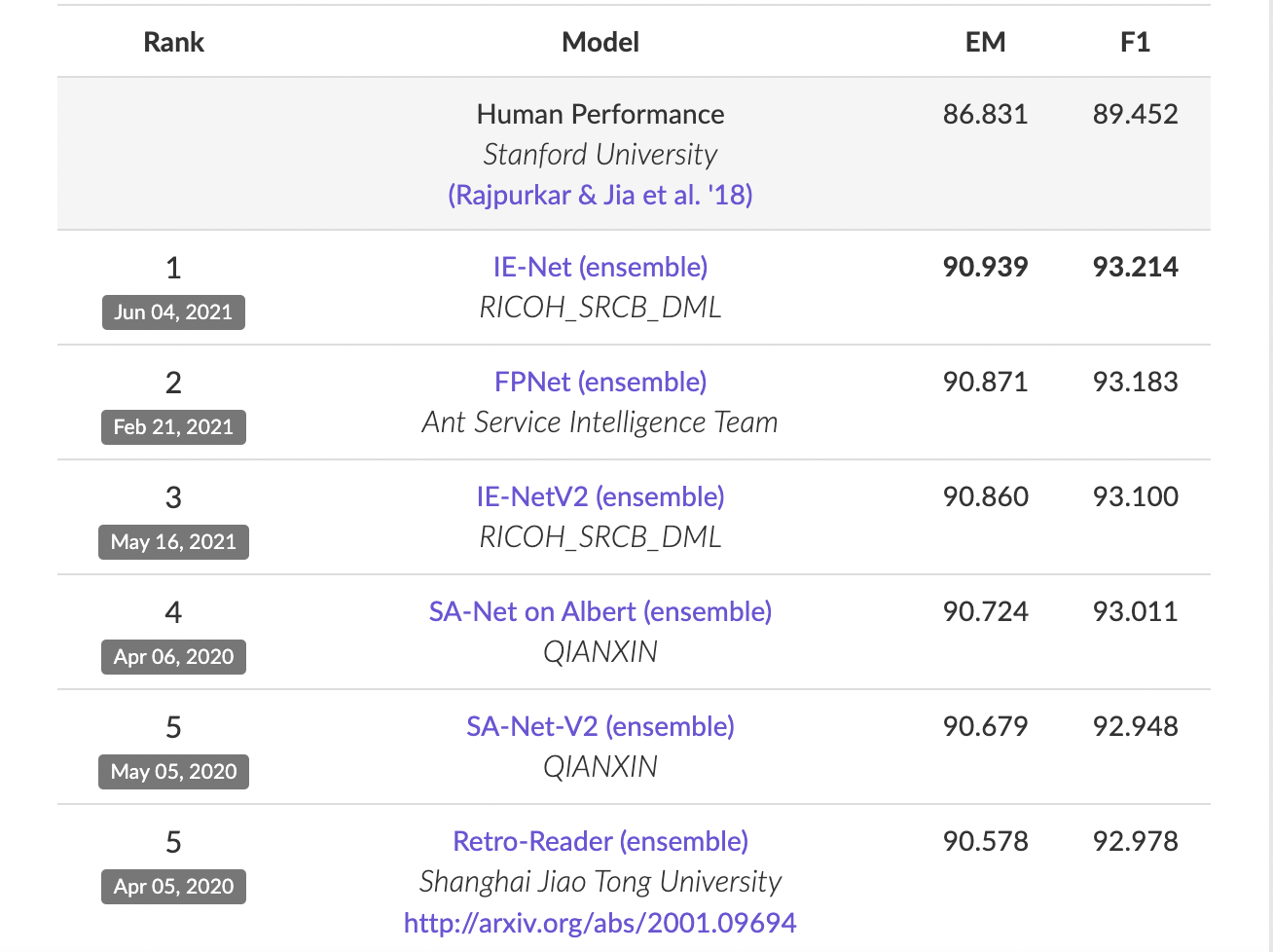
Najlepsze modele z badania wskazanego przez Google. BERT osiągał wynik na poziomie EM = 87.4, F1 = 93,16. Źródło: https://rajpurkar.github.io/SQuAD-explorer/
Do jakich zadań można wytrenować BERT-a?
Jak wspomniałem, BERT to model językowy, który można wytrenować do różnych zadań. Google w swoim dokumencie naukowym wskazuje niektóre z nich:
- Analiza sentymentu (np. czy wypowiedź w internecie jest pozytywna czy negatywna)
- System odpowiadania na pytania
- Przewidywanie dalszej części zdania
- Wyznaczanie najważniejszych słów w tekście
Padło tu wiele skomplikowanych stwierdzeń, jeśli jednak myślisz, że korzystanie z takich modeli jak BERT jest trudne, to chcę Cię wyprowadzić z błędu. W internecie jest wiele wytrenowanych modeli, a przy podstawowych umiejętnościach kodowania w języku Python możesz korzystać z dobrodziejstw, jakie daje ten model językowy.
- Google obiecuje, że każdy może wytrenować własny model BERT-a w około 30-60 minut . Własnego modelu BERT-a używa między innymi firma Allegro i udostępniła go za darmo do dalszego użytku.
- BERT jest modelem open source, możesz z niego skorzystać za darmo.
- Możesz też sprawdzić inne wytrenowane modele BERT-a w języku Polskim.
- Więcej na temat BERT-a przeczytasz w dokumencie od Google.
Jest wiele algorytmów i modeli językowych, które decydują o tym, jak dziś wyglądają wyniki wyszukiwania. Współpracują one ze sobą, aby dopasować wyniki jak najlepiej do intencji użytkownika. Pokazałem te, które miały najbardziej istotny wpływ na dzisiejszą rzeczywistość. Część z nich powoli odchodzi do lamusa, a część jest nadal rozwijana. Jedno jest pewne – dynamika zmian jest bardzo duża, wzrost możliwości w zasadzie wykładniczy, przyszłość będzie ciekawa!
Senuto MCP Server - połącz AI ze swoim SEO
Pierwszy most między Twoim LLM a polskim TOP10 Google. Twój asystent AI z dostępem do danych SEO w czasie rzeczywistym.
Zobacz, jak działaPojęcia w semantycznym SEO
W semantycznym SEO istnieje zbiór pojęć, które często się przewijają. W tej sekcji postaram się je przybliżyć. Używane są one w różnych kontekstach, dlatego moje wytłumaczenie może nie mieć zastosowania do każdego kontekstu w jakim dane pojęcie usłyszysz. Niektórzy używają również tych pojęć w różnych znaczeniach. Nie przywiązuj się do nich – ważne aby zrozumieć ich istotę i wpływ na SEO.
Intencja użytkownika
Jeśli zapoznałeś(-aś) się z poprzednią częścią artykułu, to wiesz, że Google przykłada niezwykłą wagę do tego, aby odpowiednio odpowiedzieć na intencję użytkownika. Jest to wpisane w misję tej firmy i działania w ostatnich latach udowadniają, że nie jest to zwykły frazes.
Aby dobrze zrozumieć jak Google postrzega intencję warto zajrzeć do Search Quality Evaluator Guidelines. To dokument przeznaczony dla zespołu oceniającego jakość wyników wyszukiwania (Google ma taki zespół w Irlandii, jego celem jest ocenianie stron w wynikach wyszukiwania i wsparcie pracy algorytmów). Cały dokument dostępny jest tutaj (od strony 74).
Co to jest intencja użytkownika?
Google definiuje ją w taki sposób:
“Kiedy użytkownik wpisuje lub dyktuje zapytanie próbuje osiągnąć jakiś cel. Mówimy o tym celu jako o intencji.”
W rozdziale 12 (12.7) Google mówi o tym jakie intencje należy wyróżnić:
-
**Know albo know simple:**w przypadku intencji Know użytkownik wyszukiwarki chce poszerzyć wiedzę na jakiś temat (wpisuje np. Maryla Rodowicz). W przypadku intencji know simple interesuje go prosta informacja na jakiś temat lub fakt (np. ile lat ma Maryla Rodowicz).
-
**Do:**użytkownik ma intencję “chcę coś zrobić”, np. pobrać grę, kupić coś. Wpisuje np. “jakie jest moje bmi?” chcąc wykonać test bmi. Google wyróżnia tu też intencję “device action” – kiedy użytkownik chce, aby telefon wykonał dla niego jakąś akcję, wpisuje lub mówi np. “nawiguj do pałacu kultury”.
-
**Website:**inaczej intencja nawigacyjna. Użytkownik z taką intencją chce odwiedzić jakiś konkretny serwis. Wpisuje np. “facebook”.
-
**Visit-in-person:**użytkownik z taką intencją chce osobiście odwiedzić jakieś miejsce. Wpisuje lub mówi “chińskie restauracje”.
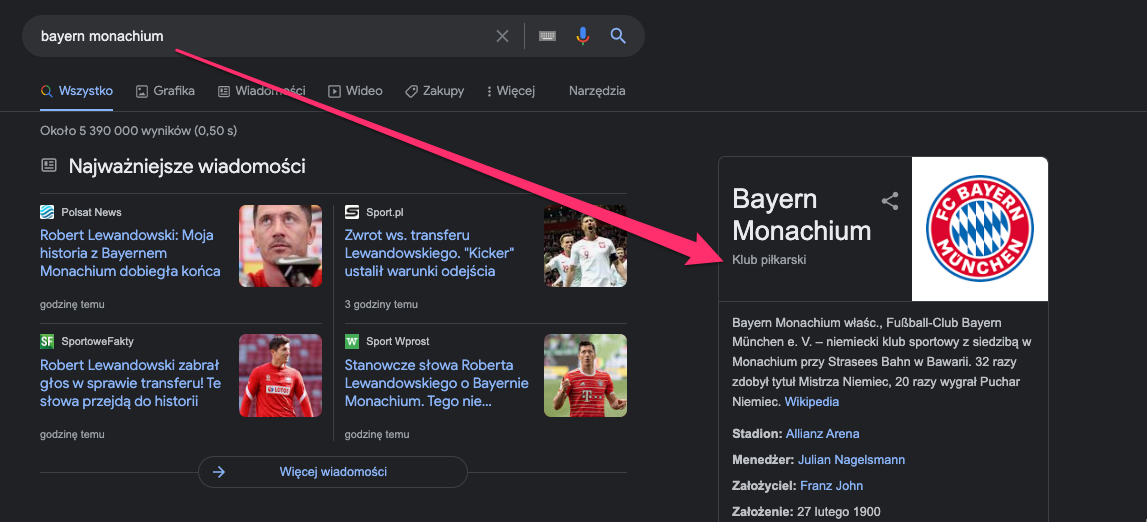
Google w dokumencie mówi też o intencjach mieszanych. Wpisując lub mówiąc Bayern Monachium użytkownik może: chęć odwiedzić stadion, dowiedzieć się czegoś o klubie bądź wejść na stronę klubu.
Jak Google określa intencję użytkownika?
W całym procesie używanych jest wiele modeli NLP i AI, o których wspominałem wcześniej (kluczowe były tu algorytmy Koliber, RankBrain i BERT). Google dodatkowo używa:
- Języka i lokalizacji użytkownika
- Profilu demograficznego (nie musisz być zalogowany(-a); na bazie Twoich poprzednich zapytań Google określa Twój profil demograficzny – możesz go sprawdzić samodzielnie)
- Informacji z poprzednich wyszukiwań (RankBrain)
- Czynników behawioralnych (mowa o czynnikach behawioralnych w wynikach wyszukiwania, a nie interakcji z witryną)
W praktyce w zależności od lokalizacji czy języka to samo zapytanie może mieć inną intencję.
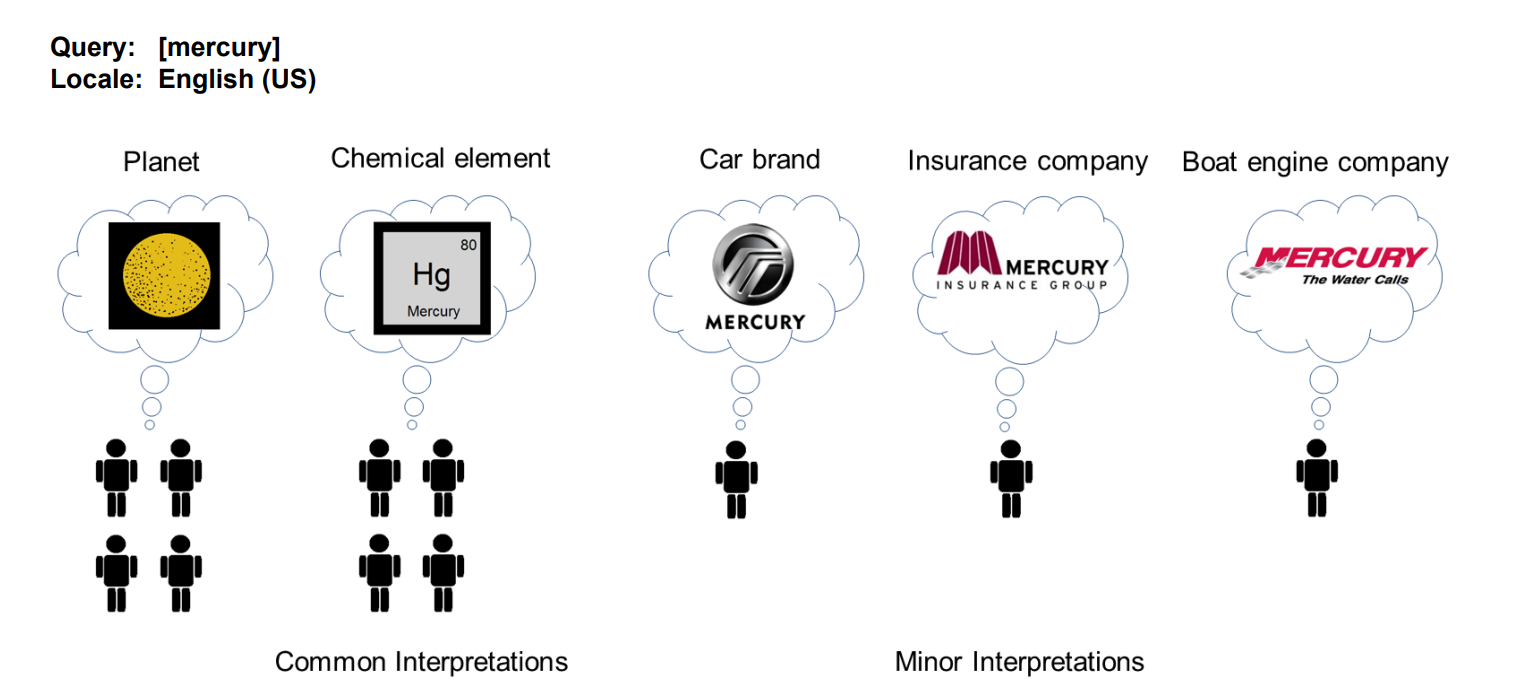
W przypadku zapytań z mieszaną intencją (takich jak mercury), Google rozróżnia 3 typy interpretacji:
- **Interpretacja dominująca (dominant interpretation):**to, co większość ludzi ma na myśli, wpisując dane zapytanie. Nie wszystkie zapytania mają interpretacje dominującą.
- **Interpretacja powszechna (common interpretation):**to, co na myśli ma znaczna część użytkowników. Zapytanie może mieć wiele interpretacji powszechnych.
- **Interpretacja rzadka (minor interpretations):**to, co na myśli ma niewielka liczba użytkowników.
W przypadku zapytania “mercury”:
- Interpretacja dominująca: planeta
- Interpretacja powszechna: pierwiastek
- Interpretacja rzadka: producent samochodów, firma ubezpieczeniowa, firma produkująca silniki do łodzi
Efekt takiego przypisania intencji możemy zaobserwować np. przy zapytaniu “mars”, gdzie Google wyświetla różne wyniki:
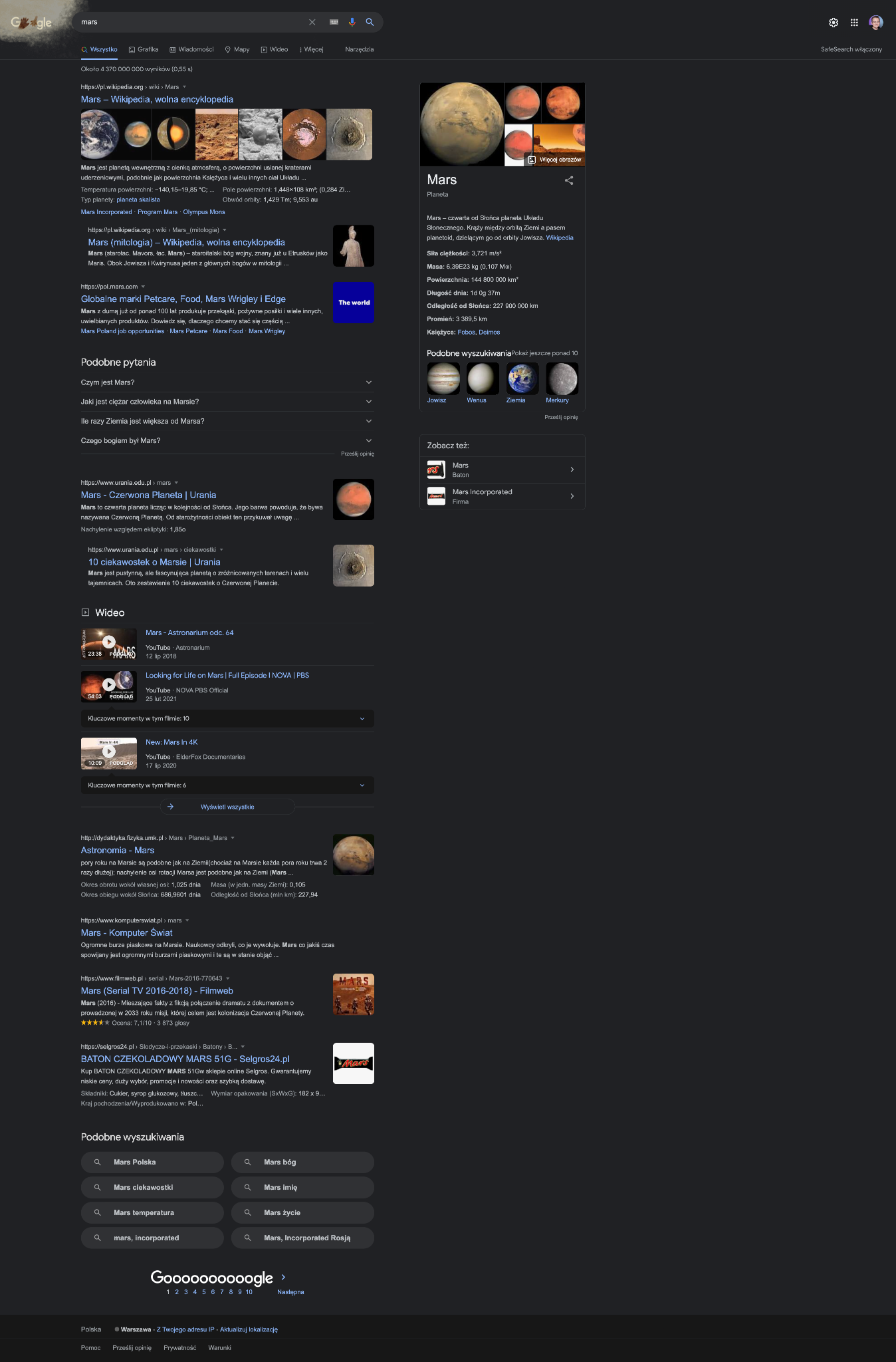
- Interpretacja dominująca – planeta
- Interpretacje powszechne – bóg wojny, baton czekoladowy
Warto również wiedzieć, że intencja może zmieniać się w czasie.
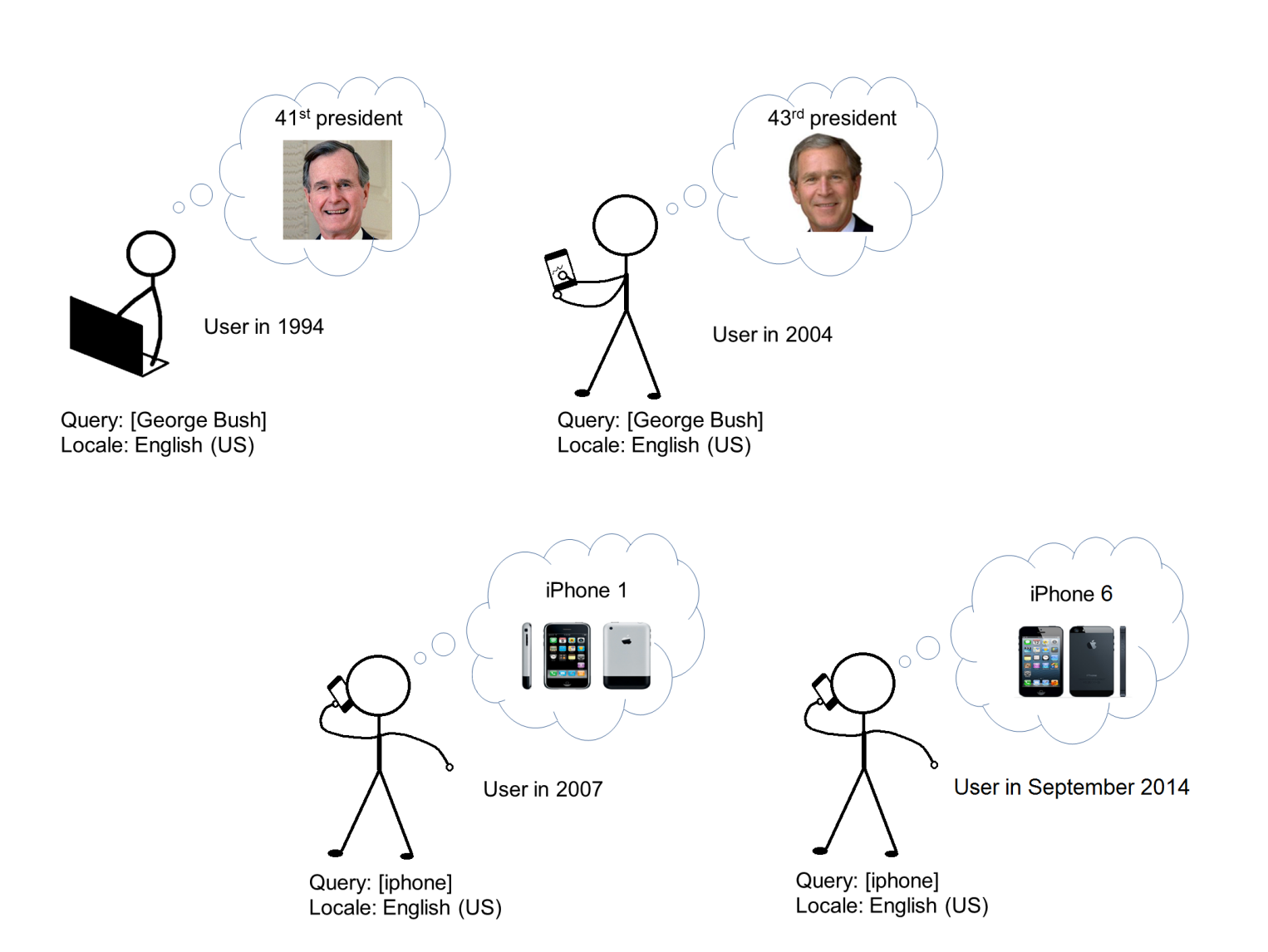
Użytkownik wpisujący zapytanie “iPhone” w 2007 miał inną intencję (znalezienie iPhone 1) niż w 2014 (znalezienie iPhone 6). Takich przykładów jest znacznie więcej:
- Dzień niepodległości w USA – w niektórych okresach roku intencją dominującą może być tytuł filmu, w innych święto.
- PlayStation – w okresie Black Friday i świąt dominującą intencją będzie intencja zakupowa (Google będzie wyświetlał więcej sklepów), a w innych okresach dominującą intencją będzie research.
Techniczne aspekty określania intencji opisane są w patencie Google.
Jak Google zaspokaja intencję użytkownika?
Google zaspokaja intencje użytkownika nie tylko poprzez wyświetlanie najlepiej dopasowanych wyników. Dziś dużą rolę odgrywają też wyniki rozszerzone (snippety). Do najczęściej występujących snippetów można zaliczyć:
- Direct answer
- Wyniki lokalne
- Opinie
- Sitelinki
- Video
- Top Stories
- Obrazki
- Panel wiedzy
- FAQs
- People Also Ask
- Powiązane zapytania
- Google Flights
- Hotel Pack
- Oferty pracy
- Google Ads
- Product Listing Ads
Z roku na rok wyniki rozszerzone stają się coraz bardziej powszechne. W wielu przypadkach są one zmorą dla specjalistów SEO – ale dla użytkowników są bardzo pomocne. Czasy, kiedy w wynikach wyszukiwania było 10 niebieskich linków (“czyste” odnośniki do stron, nie snippety) bezpowrotnie minęły. Obecnie w Polskich wynikach wyszukiwania doliczyłem się aż 1598 unikalnych sposobów wyświetlania wyników wyszukiwania.
Przykład tego, jak Google wykorzystuje moją lokalizację i snippety, aby zaspokoić moją intencję sprawdzenia aktualnej pogody:
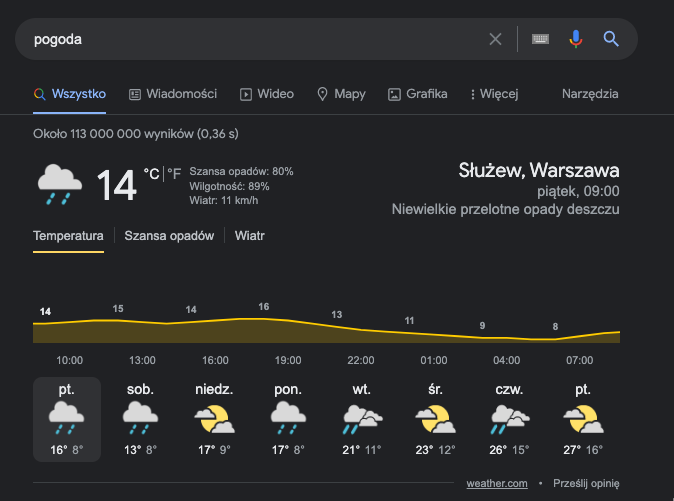
Dlaczego Google stawia na snippety?
Jak podaje Statista, dziś zdecydowanie ponad 50% użytkowników korzysta z urządzeń mobilnych (w niektórych kategoriach wyszukiwań współczynnik ten przekracza 90%). Użytkownicy na urządzeniach mobilnych potrzebują szybkiego dostępu do informacji.
Stąd snippety i różne wyniki rozszerzone, które obecnie serwuje nam Google, rozwijały się wraz z rozwojem urządzeń mobilnych.
Również rozwój wyszukiwania głosowego wpływa na rozwój wyników rozszerzonych. W przypadku komunikacji głosowej użytkownik oczekuje bezpośredniej odpowiedzi – i taką też dostaje w coraz większej liczbie zapytań. W związku z tym mówi się, że Google przestaje być “search engine” (silnikiem wyszukiwań), a zaczyna być “answer engine” (silnikiem odpowiedzi).
Metody identyfikacji intencji
Istotnym zadaniem w SEO jest dziś dopasowanie informacji na stronie www do intencji użytkownika. Pierwszym krokiem do tego, aby to zrobić jest jej identyfikacja. Istnieje na to wiele metod, pokrótce omówię te, które są moim zdaniem najciekawsze.
1. Wykorzystanie snippetów – Google poprzez to, w jaki sposób konstruuje wygląd danego wyniku wyszukiwania, niejako sugeruje nam, jaką intencję ma dane zapytanie. Jeśli wyświetla wyniki map, to najpewniej chodzi o intencję “visit-in-person”, jeśli wyświetla snippet najczęstszych pytań, to najpewniej chodzi o intencję “know”.
Intencje według snippetów można sklasyfikować w następujący sposób:
| | |
Snippet |
Intencja |
Przykład |
| | |
Mapy (local pack) |
Visit-in-person |
“Chińskie restauracje Mokotów” |
| | |
Obrazki (image pack) |
Know |
“Krzesła do biura” |
| | |
Featured snippet (direct answer) |
Know simple |
“Ile kalorii ma banan |
| | |
People also ask |
Know |
“ile kosztuje pozycjonowanie stron” |
| | |
Graf wiedzy |
Know simple, Website |
“Legia Warszawa” |
| | |
Aplikacja mobilna |
Website |
“Instagram” |
| | |
Site-linki |
Website |
“Senuto” |
| | |
Product Listing Ads |
Do |
“Tanie sukienki na studniówkę” |
| | |
Google News |
Know, Know simple, Website |
“PiS” |
Oczywiście taki sposób klasyfikacji nie gwarantuje 100% skuteczności. Należy też pamiętać, że zapytania mogą mieć fragmentaryczne intencje. Szablonem do takich przypadków podzielił się Kevin Indig – na bazie eksportu danych z Senuto możesz w Google Sheets określić intencje swoich słów kluczowych (w eksporcie z każdego modułu przy słowach kluczowych znajdują się snippety występujące w wynikach wyszukiwania, w przypadku modułu Content Planner podajemy gotową intencję).
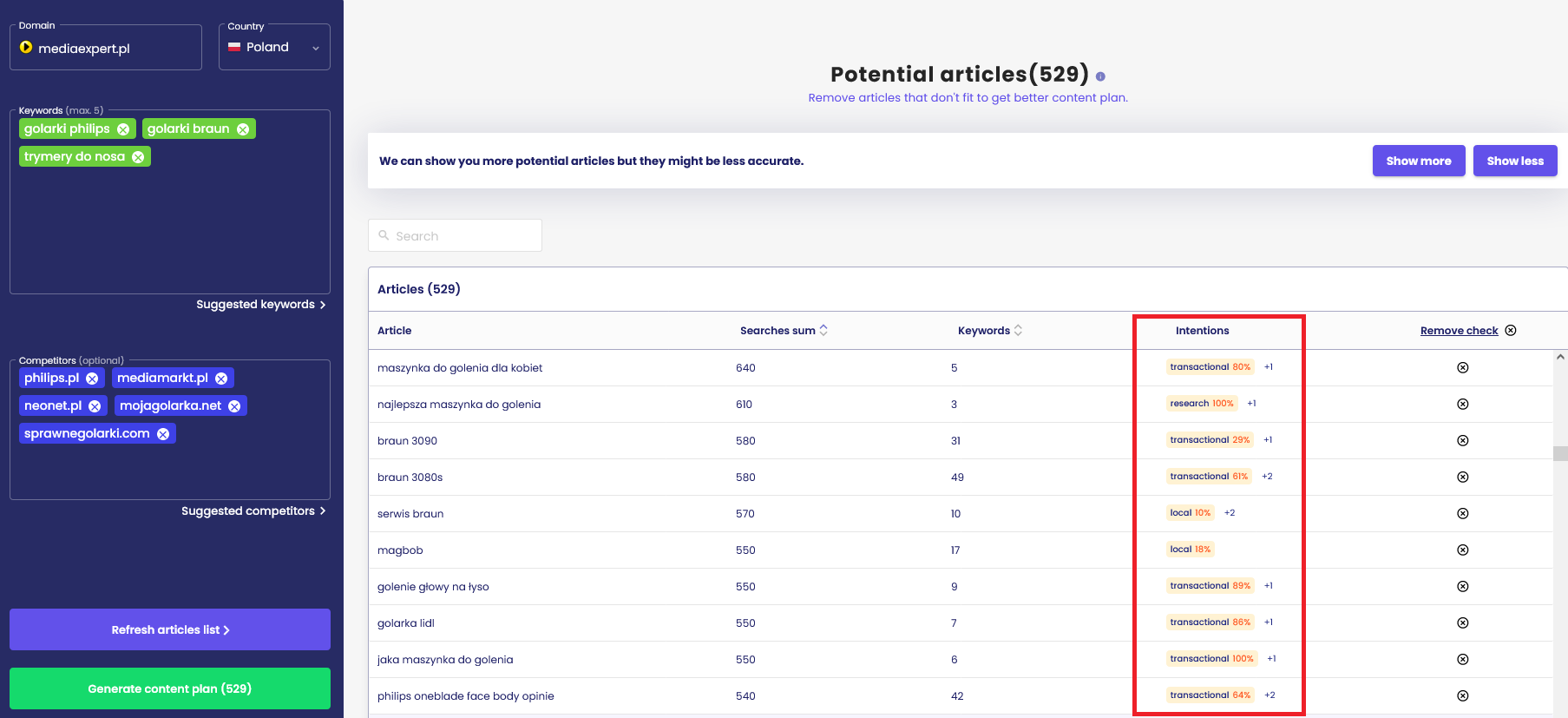
2. Metoda słownikowa – występujące w zapytaniach wyrazy sugerują z jaką intencją mamy do czynienia.
| | |
Wyraz |
Możliwa intencja |
| | |
Jak, kiedy, dlaczego, porównanie |
Know, know simple |
| | |
Cena, promocja |
Do |
| | |
niedaleko mnie, w okolicy |
Visit-in-person |
| | |
godziny otwarcia |
Website |
Do tej metody można wykorzystać dane z Google Search Console i prosty arkusz Google Sheets do przypisania intencji. Im dokładniejszy słownik utworzysz, tym dokładniejsze będą wyniki.
3. Sztuczna inteligencja – istnieją również bardziej zaawansowane metody identyfikacji intencji. Można wykorzystać do tego celu np. model językowy BERT, który omawialiśmy wcześniej. Jest to model, który można wytrenować również do klasyfikacji intencji. Nie będziemy omawiać tu w jaki sposób wykonać ten proces technicznie, zostawiam adresy stron, gdzie jest to dokładnie objaśnione.
https://www.kdnuggets.com/2020/02/intent-recognition-bert-keras-tensorflow.html – wykorzystanie modelu BERT
https://www.algolia.com/blog/ai/how-to-identify-user-search-intent-using-ai-and-machine-learning/ – wykorzystanie modelu Glove i Fasttext (model Meta)
Co nacisk na intencje użytkownika oznacza dla SEO?
Fakt, że Google kładzie tak duży nacisk na spełnianie intencji użytkownika ma wiele implikacji dla SEO.
-
Brak dopasowania do intencji = brak pozycji w TOP10– spełnienie intencji użytkownika (chociażby fragmentarycznej) jest pierwszym krokiem do tego, aby pojawić się wysoko w wynikach wyszukiwania. Żadna ilość linków czy treści nie spowoduje, że strona niedopasowana do intencji pojawi się wysoko w wynikach wyszukiwania. Nawet jeśli tak by się stało, to najpewniej długo tej pozycji nie utrzyma. Jeśli użytkownik ma intencję Know (np. wpisuje “jak się ubrać na studniówkę”), to stroną docelową nie może być tu strona spełniająca intencję Do (np. strona kategorii z sukienkami na studniówkę), a raczej odpowiednio napisany artykuł z inspiracjami.
-
Jeśli intencja jest prawidłowa, otwiera to możliwości do rankowania na tysiące fraz dla jednego adresu URL – niegdyś dla każdego słowa kluczowego tworzyło się oddzielną stronę docelową. Dziś dzięki temu jak działa wyszukiwarka, pojedyncza podstrona może być wysoko w wynikach wyszukiwania na tysiące fraz, jeśli spełnia intencję użytkownika. Google wie, że zapytania “co robić w Warszawie” i “co zwiedzić w Warszawie” mają taką samą intencję.
-
Intencja to nie tylko typ podstrony – wielu specjalistów SEO postrzega intencję poprzez typ strony, jaki powinien wyświetlać się w wynikach wyszukiwania (np. artykuł, strona kategorii, produkt). Trzeba myśleć tu głębiej: 1. Czy użytkownik oczekuje recenzji, definicji czy może długiej treści? 2. Czy użytkownik oczekuje mediów, filmów?
Niestety na te pytania nie da się odpowiedzieć automatycznie. Należy edukować copywriterów w tym zakresie.
-
Wyniki dla intencji fragmentarycznej – w przypadku tego typu intencji należy analizować wyniki wyszukiwania i zdecydować, jaki typ intencji chcemy spełnić: dominujący, czy może powszechny? Przykład: użytkownik wpisuje “narzędzia do tworzenia landing page” – może oczekiwać strony produktu, porównania, listy. Google rezerwuje określoną liczbę miejsc w wynikach dla poszczególnych odpowiedzi, należy brać to pod uwagę.
-
**Wyniki dla intencji fragmentarycznej mogą się częściej zmieniać –**wyniki, dla których intencja nie jest oczywista (zwłaszcza krótkie zapytania) podlegają częstym niż kiedyś fluktuacjom. Trzeba obserwować takie wyniki i na bieżąco reagować.
Entities (encje)
Graf wiedzy wyszukiwarki nie jest zbudowany w oparciu o słowa kluczowe – jest zbudowany w oparciu o entities i kontekst ich użycia. Entities w tłumaczeniu na polski to podmioty, często używa się też słowa encje. Jako że żadne z tych tłumaczeń nie wyjaśnia dokładnie z czym mamy do czynienia, będę posługiwał się angielską formą.
Według definicji Google, entity to:
“Rzecz lub koncepcja, która jest unikalna, dobrze zdefiniowana i rozróżnialna.”
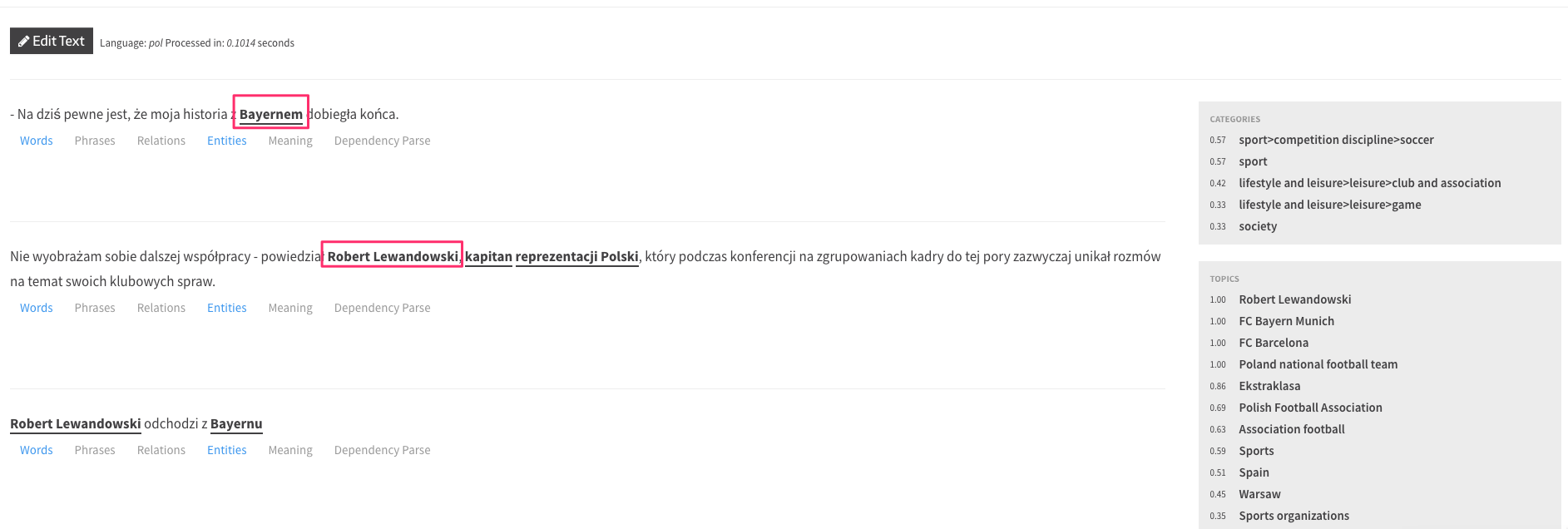
Przykładem entity może być np. “Robert Lewandowski”. Za pomocą API grafu wiedzy możemy zobaczyć, w jaki sposób Google przechowuje informacje na ten temat.
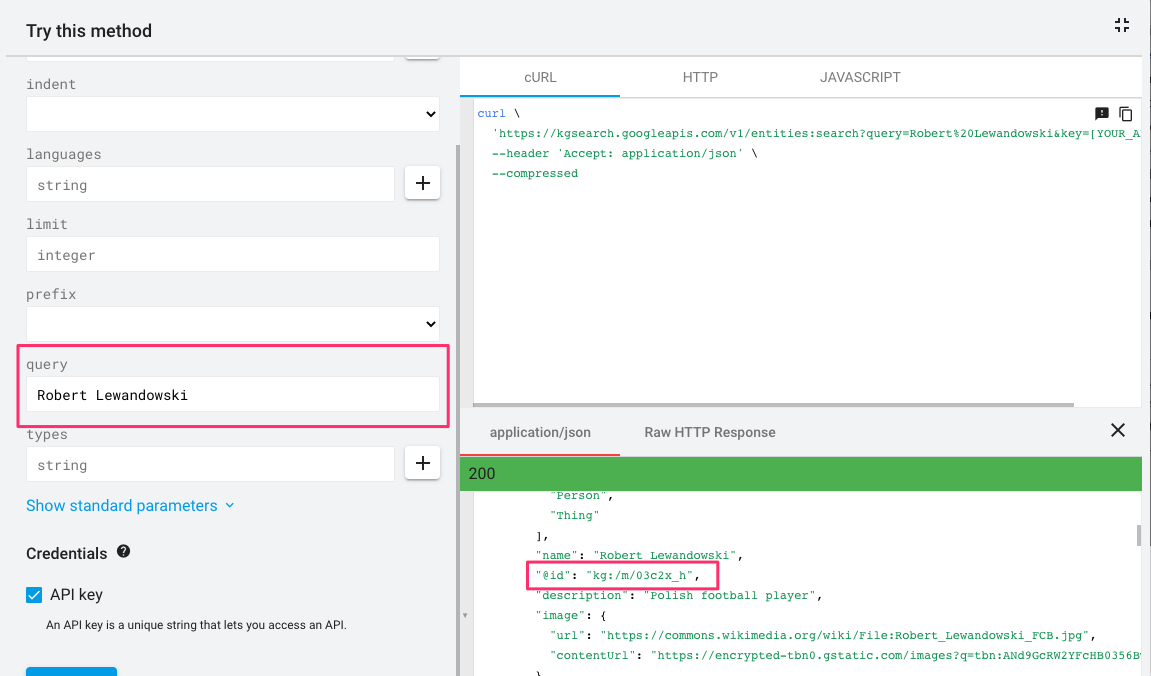
Google wie, że Robert Lewandowski to osoba, polski piłkarz.
Warto tu zwrócić na @id zaznaczone na zrzucie ekranu. Każde entity w bazie wiedzy Google ma swoje unikalne id, gdyż jedno zapytanie może mieć wiele znaczeń (możesz to sprawdzić wpisując jako zapytanie np. “zamek”).
Entity “Robert Lewandowski” ma swoje unikalne id: /m/03c2x_h (things not strings). Entity z /m/ oznacza, że Google dodało to pojęcie do grafu wiedzy przed 2015 rokiem, entity z /g/ oznacza, że odbyło się to po 2015 roku.
Jak to się ma do intencji użytkownika (i czy artykuł o Mariuszu Lewandowskim ma szanse na TOP3)?
Kiedy wpiszemy do API Knowledge Graphu zapytanie “Lewandowski” zobaczymy, że wyników jest wiele. Mamy Roberta Lewandowskiego, Mariusza czy Janusza. Wpisując do wyszukiwarki zapytanie “Lewandowski” mamy zatem do czynienia z intencją fragmentaryczną. Intencja dominująca ujawni się w tym, jak wyglądają wyniki wyszukiwania, ale można też posłużyć się tu scoringiem z Knowledge Graphu.
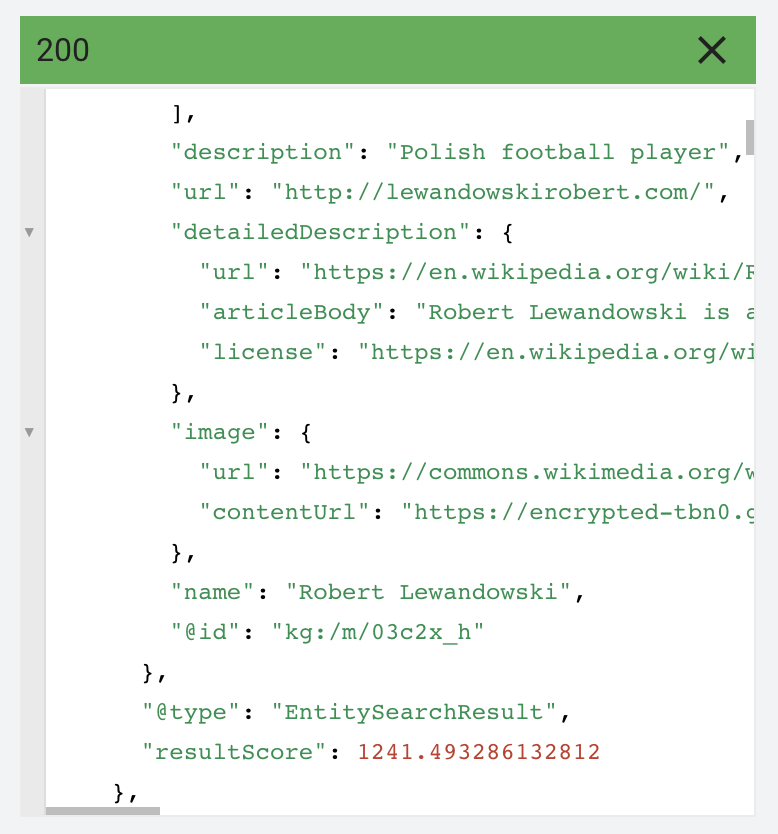
Score dla Roberta Lewandowskiego wynosi 1241, dla Mariusza Lewandowskiego (drugi wynik) 74. W TOP50 dla tego zapytania próżno szukać innych wyników. Co oznacza, że próba zdobycia wysokiej pozycji z artykułem o Mariuszu Lewandowskim zakończyłaby się raczej niepowodzeniem.
Artykuł dotyczy semantyki, a w semantyce kluczowe są relacje. Graf wiedzy zawiera relacje właśnie pomiędzy entities.
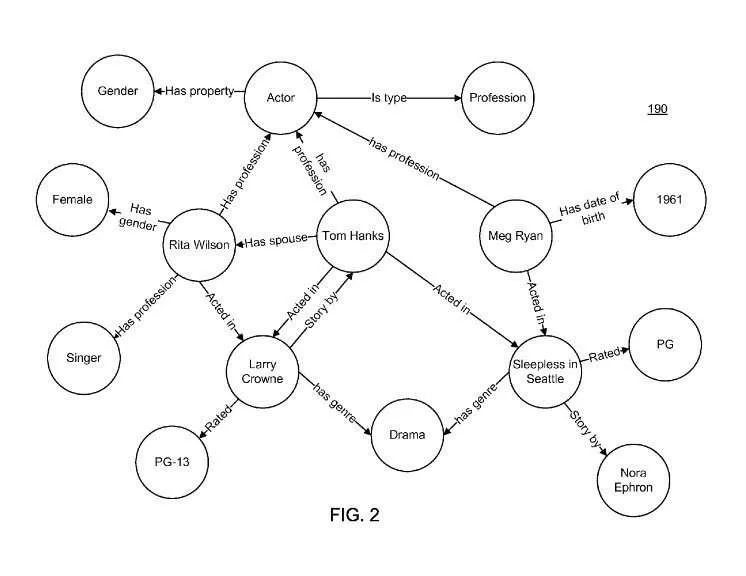
Graf wiedzy może zawierać entity “Tom Hanks”, ale też entites opisujące filmy, w których zagrał oraz inne atrybuty i relacje (jak płeć, wiek, wykonywany zawód).
Taki zestaw cech, atrybutów i relacji dla entities nazywany jest ontologią. Posiadając miliony unikalnych połączeń cech i atrybutów, wyszukiwarka może znacznie lepiej rozumieć treści na stronach internetowych i zapytania użytkowników.
Google w 2018 w jednym ze swoich naukowych opracowań opisał możliwy sposób na budowanie bazy ontologii działającej w wyszukiwarce.
Biperpedia opisywana w dokumencie, z definicji jest ontologią atrybutów binarnych zawierającą do dwóch rzędów wielkości więcej atrybutów niż Freebase (baza danych entities niegdyś używana między innymi przez Google, bardzo polecam lekturę tego dokumentu!).
Poniższy zrzut ekranu prezentuje przykładowy zapis informacji w takim systemie:

Atrybut (w tym systemie jest to relacja dwóch entities, np. stolice i państwa) stolica jest w zbiorze klas krajów, które są powiązane z lokalizacjami.
Synonimem są tu stolice.
W bazie informacji zapisane są też niepoprawne formy zapisu.
Dodatkowe powiązania: stolice krajów, stolice mody.
Mamy również informację o źródłach atrybutów:
- Zapytania użytkowników – 317 entites zawiera ten atrybut, występuje on w 11 milionach zapytań użytkowników (system został oparty na analizie 36 miliardów zapytań)
- Treści ze stron www – 441 entities z atrybutem, zawarty w milionach dokumentów
Poniżej w tabeli znajdziesz również przykładowe formy wyekstrahowane z treści i zapytań.
A tutaj zamieszczam jeszcze kilka ciekawych wniosków z wcześniej przytoczonego dokumentu:

Biperpedia rozumie powiązania między atrybutami (np. rozumie, że matka należy do podzbioru rodzic). Taki sposób przechowywania informacji pozwala rozumieć szersze zapytania użytkowników i zwrócić lepszy wynik. Cały system skupia się na zwracaniu sformatowanych informacji w postaci gotowej odpowiedzi – dlatego mowa tu o tabeli.
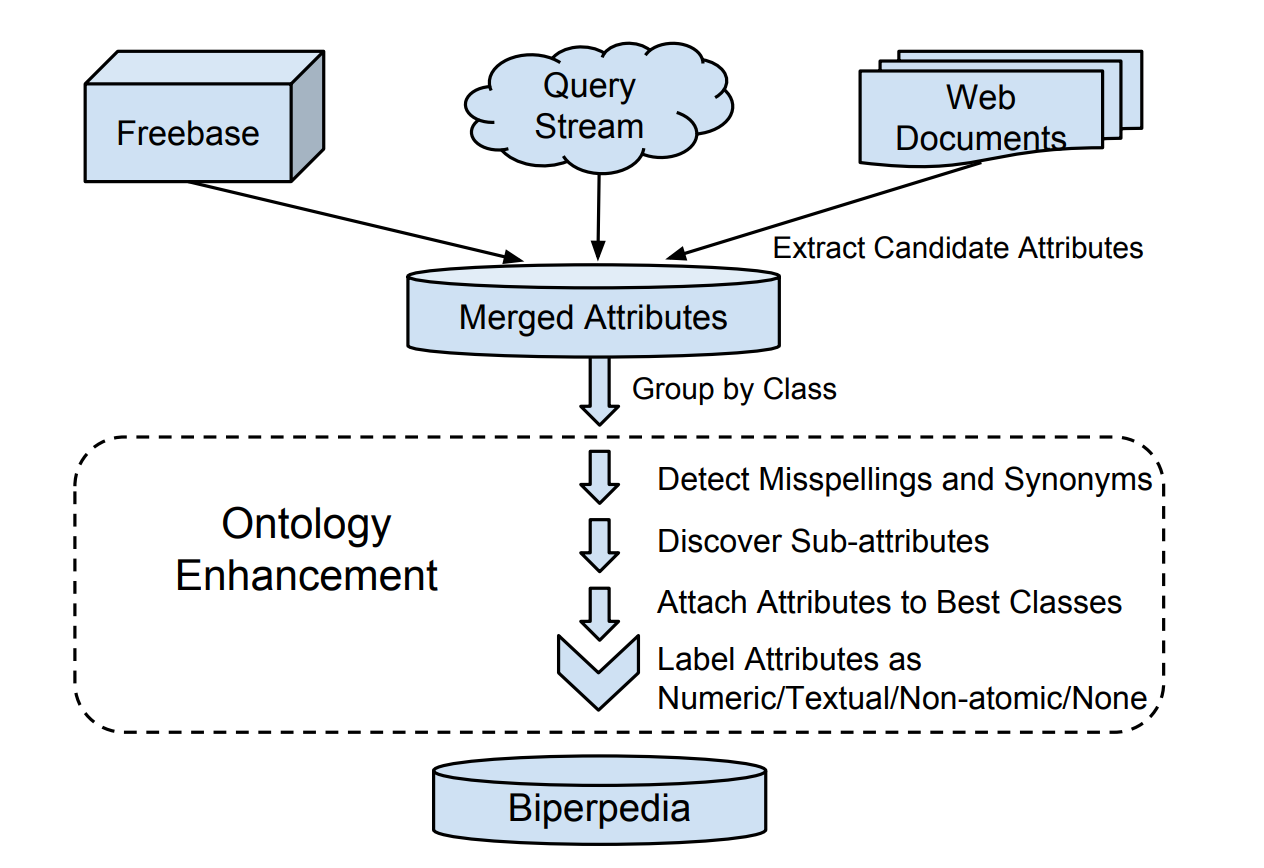
W taki sposób wygląda budowa tej bazy.
- Dane pobierane są z Freebase, Query Streams, stron internetowych
- Atrybuty z tych źródeł są ze sobą łączone
- Wykrywane są synonimy i błędy językowe
- Wykrywane są sub-atrybuty
- Atrybuty przypisywane są do najlepszych klas (jeden atrybut może mieć wiele klas)
- Atrybuty oznaczane są typem
- Trafiają do bazy
Ważny jest również punkt 5. dokumentu (strona 4), gdzie znajduje się opis, w jaki sposób system dokonuje ekstrakcji entites z treści. Ekstrakcja ta odbywa się za pomocą techniki Distant supervision. Wykorzystuje się w niej wcześniej utworzoną bazę wiedzy do poszukiwania elementów podobnych. W przypadku Biperpedii użyte zostały najpopularniejsze atrybuty już w niej istniejące.
System w swojej bazie ma atrybut PRODUKCJA KAWY przypisany do entity BRAZYLIA, w momencie znalezienia tekstu “Produkcja kawy w Brazylii wzrosła o 5%” za pomocą leksykalnych wzorców jest w stanie wyznaczyć parę atrybut + entity. Po analizie treści powstaje zbiór kandydatów na parę atrybut + entity.
System bierze pod uwagę tylko takie pary, które mają minimum 10 wystąpień (10 wystąpień liczonych w całym korpusie, czyli w całym analizowanym zbiorze dokumentów).
Do ekstrakcji wykorzystywane są jeszcze dodatkowe techniki NLP: parts-of-speech (POS) tagger, dependency parser, noun pharse-segmenter, named entity recognizer, coreference resolver, and entity resolver (jeśli chcesz zobaczyć co dokładnie robi każdy z procesów zajrzyj do podlinkowanego dokumentu).
Na ostatnim etapie przed trafieniem atrybutu do bazy, prace wykonuje klasyfikator oparty na modelu regresji liniowej.
W jaki sposób entities uczyniły wyszukiwarkę lepszą?
- Rozumienie atrybutów entities pozwala wyświetlać coraz bardziej ustrukturyzowane informacje (snippety, mamy coraz więcej wyników z direct answer).
- Duża liczba atrybutów entites pozwala wyłapywać fakty znajdujące się w treści, co przekłada się na lepszą analizę wiarygodności źródeł.
- Pozwala lepiej rozumieć bardzo długie zapytania.
Google mając powiązania pomiędzy entities jest również w stanie lepiej spełniać intencje użytkownika. Dzięki temu poza zwykłymi wynikami jest w stanie zwracać dodatkowe, ciekawe dla użytkownika informacje – np. wszystkie filmy, w których zagrał Tom Hanks.
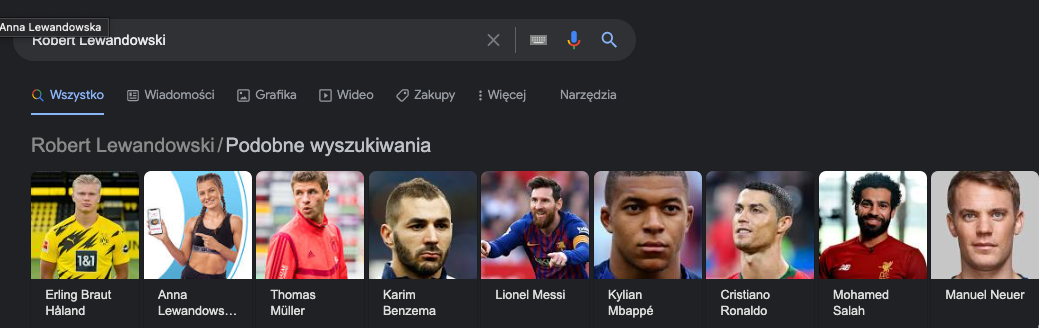
Z kolei w przypadku zapytania “Robert Lewandowski”, Google pokazuje innych piłkarzy, którzy są w jakiś sposób powiązani z Robertem.
To, z jaką precyzją Google rozpoznaje entities, można przetestować za pomocą Google NLP API. Jest to API, które pozwala wdrożyć w zewnętrznych systemach algorytmy NLP podobne do tych używanych przez wyszukiwarkę. Samo API nie działa w języku polskim (lista dostępnych języków), dlatego pokażę przykład w języku angielskim.
Jako tekstu użyłem pierwszych czterech paragrafów strony o Robercie Lewandowskim na Wikipedii:

źródło: https://cloud.google.com/natural-language#section-2
Każdy tekst zaznaczony kolorem to rozpoznane entites, poniżej znajduje się opis każdego z nich. Możemy się z niego dowiedzieć, że:
- Robert Lewandowski to osoba
- Salience dla tego entities wynosi 0,73 (skala 0-1, która określa jak konkretne entity jest istotne w danym dokumencie/tekście)
Jak można też zauważyć, w niektórych przypadkach API nie jest precyzyjne, np. Bayern Munich został oznaczony jako lokalizacja, a jest to klub piłkarski. Wyniki wyszukiwania wskazują jednak, że Google rozumie to entity, co może sugerować, że do API nie są używane najnowsze modele.
Poza analizą entites NLP API Google potrafi znacznie więcej – między innymi kategoryzować treści. Przytoczony wcześniej tekst z Wikipedii o Robercie Lewandowskim zaliczył do dwóch kategorii:

Pełna lista kategorii dostępna jest tutaj. Natomiast demo API sprawdzisz tutaj.
API do 5 tysięcy zapytań miesięcznie jest darmowe. Później w zależności od wykorzystywanych funkcji płacimy od 0.125$ do 2$ za zapytanie.
Jeśli chcesz korzystać z NLP w swoim projekcie w języku polskim, to możesz skorzystać z innych dostępnych na rynku modeli językowych.
Analiza entites w języku polskim przeprowadzona przez model Text Razor.
Oto dwa popularne rozwiązania:
Samych modeli i bibliotek jest w internecie bardzo wiele.
Entities są istotne z punktu widzenia tworzenia treści i architektury informacji w SEO.
Z dalszej części artykułu dowiesz się, w jaki sposób użyć tej wiedzy w praktyce.
Topical authority
W ostatnich dwóch latach pojęcie topical authority bardzo mocno przebija się w świecie SEO.
Dzięki wymienionym wyżej algorytmom, modelom i zmianom Google przestał postrzegać serwisy przez pryzmat słów kluczowych, a zaczął postrzegać przez pryzmat pojęć.
Znając zależności pomiędzy pojęciami Google jest w stanie określić, jakie pojęcia należą do danego zagadnienia. Dzięki temu może stwierdzić, jak dany serwis wpisuje się w to zagadnienie (a nie w konkretne słowo kluczowe) – i ocenić, na ile jest w tym zagadnieniu ekspercki.
Google, mając na uwadzę swoją misję dotyczącą spełniania intencji użytkownika, woli go odsyłać do serwisów eksperckich, na których użytkownik w pełni zrealizuje swoją intencję.
O takich serwisach mówimy jako o posiadających wysokie topical authority.
Przykład
Użytkownik wpisuje do wyszukiwarki zapytanie “pozycjonowanie” – w przeszłości Google dopasowałby najlepsze dokumenty na bazie pojedynczego zapytania oraz szeregu innych czynników, takich jak linki.
Dziś Google rozumie, że w pojęciu pozycjonowania znajdują się też takie pojęcia jak: linki, optymalizacja techniczna, mapa strony i tysiące innych. Na górze wyników wyszukiwania mają większą szansę pojawić się te serwisy, które w pełni pokrywają te obszary wiedzy – odpowiadają na wszystkie te pojęcia zgodnie z intencją.
Oczywiście to nie jedyny czynnik algorytmiczny i serwisy muszą spełniać szereg innych wymogów, ale topical authority jest dziś bardzo istotne. Np. budując eksperckość da się być wysoko w wynikach wyszukiwania bez linków – ale ciężko być wysoko w wynikach wyszukiwania tylko budując linki, z pominięciem elementu eksperckości.
Musimy tu jednak mieć cały czas na uwadze intencje. Niekiedy intencja użytkownika nie wymaga tego, aby serwis był ekspercki w danym temacie, bo sama intencja jest powierzchowna. W takich przypadkach topical authority nie będzie odgrywać kluczowej roli.
Na temat topical authority wypowiedział się John Muller z Google.
Oto dwa cytaty z wypowiedzi Johna:
“When we want to rank for a specific topic on Google is it a good practice to also cover related topics. For example, if we sell laptops when you want to rank for that is it useful to create posts like reviewing laptops, the introducing the best new laptops, those kind of things? And if it’s useful then it doesn’t have to be done in any special way?”
“So I think this is always useful because what you’re essentially doing is on the one hand for search engines you’re kind of building out your reputation of knowledge on that specific topic area. And for users as well it provides a little bit more context on kind of like why they should trust you. If they see that you have all of this knowledge on this general topic area and you show that and you kind of present that regularly, then it makes it a lot easier for them to trust you on something very specific that you’re also providing on your website. So that’s something where I think that that always kind of makes sense.
And for search engines as well. It’s something where if we can recognize that this website is really good for this broader topic area then if someone is searching for that broader topic area we we can try to show that website as well. We don’t have to purely focus on individual pages but we’ll say oh like it looks like you’re looking for a new laptop, like this website has a lot of information on various facets around laptops.”
Podsumowując:
- John mówi, że jeśli chcemy być wysoko w Google na jakiś temat, warto też napisać treści na tematy powiązane.
- Robiąc to w taki sposób budujemy “reputację w zakresie wiedzy w danym obszarze” – wspomina tu o topical authority.
- Ważne jest to również dla użytkowników, którzy mając więcej kontekstu zyskują większe zaufanie.
- Dzięki takiemu podejściu Google może zawęzić obszar swoich poszukiwań – zamiast dla każdego zapytania analizować najlepsze strony może dostarczyć użytkownikowi zestaw stron, które najlepiej wypełniają dany koncept.
Jak istotne jest topical authority?
Na potrzeby mojej prezentacji na Festiwalu SEO w 2021 zbadałem korelację pomiędzy topical authority a pozycją w wynikach wyszukiwania.
Metodologia badania:
- W badaniu brałem pod uwagę 212 tysięcy słów kluczowych,
- Metodą klasteryzacji Senuto podzieliłem te słowa kluczowe na 7 200 grup semantycznych,
- Dla każdego słowa kluczowego sprawdzałem wyniki TOP10 i badałem ile słów kluczowych spośród przypisanych do grupy semantycznej adresują w swoich treściach (jedna grupa semantyczna powinna odpowiadać jednej podstronie). Na tej podstawie ułożyłem metrykę w skali od 1 do 100: 1 – bardzo słabe pokrycie, 100 – pełne pokrycie tematyczne.
Wyniki kształtują się następująco:
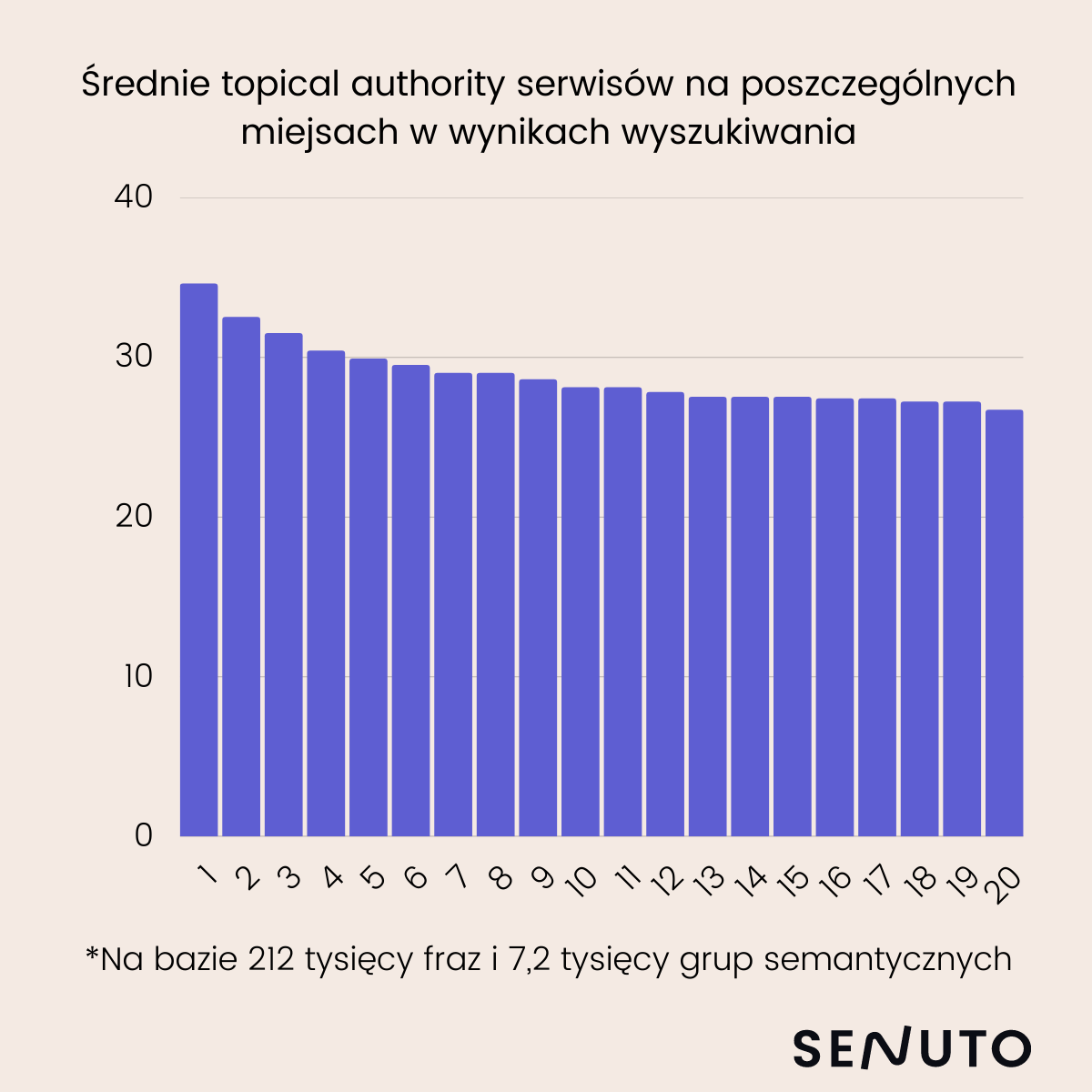
Jak widać im wyższa pozycja, tym wyższe topical authority. Badałem również korelację pomiędzy pozycją a wysokim topical authority. Wynik korelacji wynosi 0,69, co oznacza, że korelacja występuje.
Oczywiście zdaję sobie sprawę, że metoda badawcza nie jest tu idealna, ponieważ badam pojedyncze podstrony zamiast całych serwisów, dodatkowo badanie jest w oderwaniu od innych czynników, takich jak liczba linków czy poziom optymalizacji serwisu – ale to jedyna metoda, którą dysponowałem.
Pomijając samo badanie możemy odnieść się do obserwacji zmian w wyszukiwarce w ostatnich latach. Wszystkie istotne aktualizacje algorytmu dotyczą tego, jak Google analizuje treści i dopasowanie intencji, co oznacza, że czynniki z tej kategorii są dla wyszukiwarki istotne, a w przyszłości będą na tej istotności mocno zyskiwać.
Co jeszcze warto wiedzieć w kontekście semantycznego SEO?
Do pełnego zrozumienia semantycznego SEO musisz zrozumieć jeszcze kilka mechanizmów działania wyszukiwarki. Przejdziemy przez nie po kolei i wtedy już będziesz mieć w głowie pełny obraz.
Ocena kompleksowości dostarczonej informacji
Zgodnie z koncepcją topical authority Google chce odsyłać użytkownika do kompleksowych źródeł informacji. W tym celu ocenia każdy dokument pod kątem dodatkowych informacji, których użytkownik mógł nie znaleźć w innych dokumentach (np. wpis blogowy, który kompleksowo wyjaśnia niuanse diety keto i jest bogatszy w wiedzę od wpisów na konkurencyjnych blogach).
W patencie Google znajdziemy taki zapis:
Techniques are described herein for determining an information gain score for one or more documents of interest to the user and present information from the documents based on the information gain score. An information gain score for a given document is indicative of additional information that is included in the document beyond information contained in documents that were previously viewed by the user. In some implementations, the information gain score may be determined for one or more documents by applying data from the documents across a machine learning model to generate an information gain score. Based on the information gain scores of a set of documents, the documents can be provided to the user in a manner that reflects the likely information gain that can be attained by the user if the user were to view the documents.
W praktyce oznacza to, że Google może zwiększać pozycje serwisom, które dostarczają nowe informacje w zakresie danego zapytania użytkownika i obniżać pozycje serwisom, które nie wnoszą żadnych nowych informacji.
Obecnie w SEO większość treści powstaje w oparciu o analizę obecnych wyników TOP10 wyników wyszukiwania. Nie jest to zła technika, ale wpycha często w pułapkę powielania już istniejących informacji.
Naszym celem powinno być takie tworzenie treści, które wnosi więcej informacji niż obecnie znajdujące się wysoko w wynikach wyszukiwania strony.
W praktyce oznacza to między innymi, że w procesie researchu słów kluczowych nie powinniśmy wybierać tylko te frazy, które mają wyszukiwania. Te, które ich nie mają również powinny być przez nas zagospodarowane (a więc użyte w treści). W ten sposób istnieje szansa na wypełnienie luki informacyjnej i wyższe pozycje w wynikach wyszukiwania.
Więcej na ten temat napisał Bill Slawski.
Architektura informacji serwisu & linkowanie wewnętrzne a semantyczne SEO
Z punktu widzenia semantycznego SEO istnieją dwa składniki sukcesu:
- Napisanie treści w taki sposób, aby pokrywała dany temat i odpowiadała na intencje użytkownika.
- Organizacja jej na stronie internetowej w taki sposób, aby treści zbieżne tematycznie były w strukturze blisko siebie, a sama struktura była zrozumiała dla wyszukiwarki – i to właśnie jest aspekt odpowiednio ułożonej architektury informacji, który teraz omówimy.
Odpowiednio zbudowana architektura informacji ma wpływ na wiele aspektów SEO (takich jak crawl budget), tu będziemy rozpatrywać ją z punktu widzenia semantycznego SEO. Kluczowe jest to aby podobną do siebie treść w strukturze serwisu trzymać odpowiednio blisko siebie. Wprowadzimy tu dwa pojęcia:
- Klastry tematyczne – zbieżne ze sobą semantycznie treści (np. artykuł o semantycznym SEO i artykuł o linkowaniu wewnętrznym).
- Pillar pages (strony filarowe) – według tej techniki powinniśmy posiadać jeden artykuł, który porusza temat w bardzo kompleksowy sposób, oraz wiele artykułów wspomagających go dodatkowymi informacjami.
Schemat takiej architektury mógłby wyglądać tak:
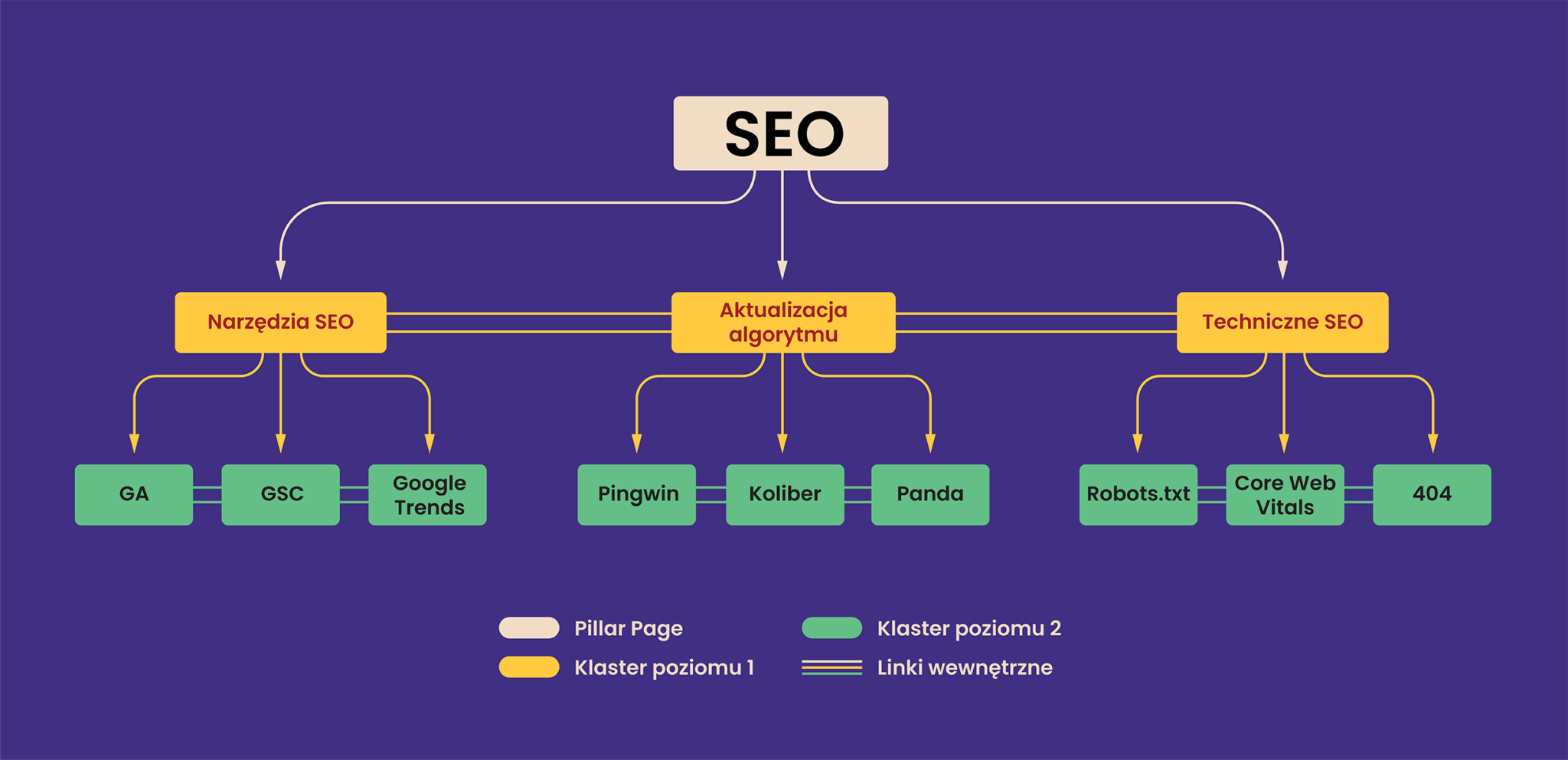
Schemat przedstawia poglądową część struktury. Realna struktura, która uzyskałaby wysokie topical authority musiałaby być znacznie bardziej rozbudowana.
Taka struktura nazywana jest też często strukturą silosową (silo structure).
- Na górze naszego schematu mamy ogólny artykuł na temat SEO – jest to nasz pillar page.
- Niżej mamy klaster poziomu 1, który nadal porusza ogólne zagadnienia, ale są one częścią wiedzy zawartej w pillar page.
- Niżej mamy klaster poziomu 2, który porusza już bardzo szczegółowe zagadnienia, również wywodzące się z wiedzy z klastra 1.
Pomiędzy poszczególnymi podstronami znajdują się też linki wewnętrzne. Nie w każdym przypadku są one koniecznością, nie należy ich dodawać na siłę. Tak zorganizowana struktura pozwoli wyszukiwarce lepiej rozumieć witrynę i szybciej ją analizować. To z kolei przełoży się na poprawę wielu parametrów SEO (np. crawl budgetu)
W tym momencie możesz zadawać sobie sporo pytań, poniżej na nie odpowiadam:
- Czy mogę dodawać linki wewnętrzne pomiędzy klastrami?
Pomiędzy klastrami zorganizowanymi pod jednym pillar page jak najbardziej. Pomiędzy klastrami zorganizowanymi pod innymi pillar pages nie zawsze. Jeśli są one mocno oddalone tematycznie staraj się je oddzielać (np. Zdrowie i Budownictwo), natomiast jeśli są zbieżne tematycznie, to możesz takie linki dodawać (np. SEO i Google Ads)
- Jaki typ linków wewnętrznych jest najlepszy?
Najlepsze z punktu widzenia semantycznego SEO będą linki z treści. Dzięki otoczeniu linka treścią wyszukiwarka ma niezbędny kontekst podczas analizy.
- Ile linków wewnętrznych dodawać w jednym klastrze?
Nie ma złotej reguły. Pamiętaj, że im więcej linków wewnętrznych dodasz, tym moc pojedynczego linka będzie niższa. Jeśli strona ma 300 linków wewnętrznych, to każdy przekazuje 1/300 jej mocy. W związku z tym warto zastosować kilka dobrych praktyk:
– Unikaj wielu powtarzających się linków w stopce (tzw. linków site-wide) – na przykład jeśli prowadzisz sklep i bloga, menu ze sklepu nie powinno występować na blogu.
– Dodawaj w widgetach i sugerowanych linkach tylko powiązane klastry.
– W treści stosuj tyle linków, ile ma semantyczny sens. Nie stosuj sztywnych zasad ilościowych.
- Czy w adresie URL powinna znajdować się cała ścieżka do klastra, np. domena.com/seo/techniczne-seo/404
Przy odpowiednim linkowaniu wewnętrznym Google poradzi sobie z analizą takiej struktury, zwłaszcza jeśli użyjemy dodatkowo np. breadcrumbs. Natomiast utrzymanie takiej struktury katalogów jest zawsze dodatkowym atutem. Zarówno z punktu widzenia wyszukiwarki jak i użytkowników.
- Czy mogę tworzyć klastry dalszych poziomów?
Co do zasady warto utrzymywać dość płaską strukturę serwisu. Ułatwia to wyszukiwarce crawlowanie, pozwala też lepiej zarządzać przepływem PageRank. Jeśli jednak temat, w którym operujesz jest bardzo głęboki (np. zdrowie) może być konieczne utworzenie kolejnego poziomu klastrów.
Dobrym przykładem do naśladowania może być tu np. serwis medonet.pl. Spójrzmy w jaki sposób spełniają wymagania semantycznego SEO.
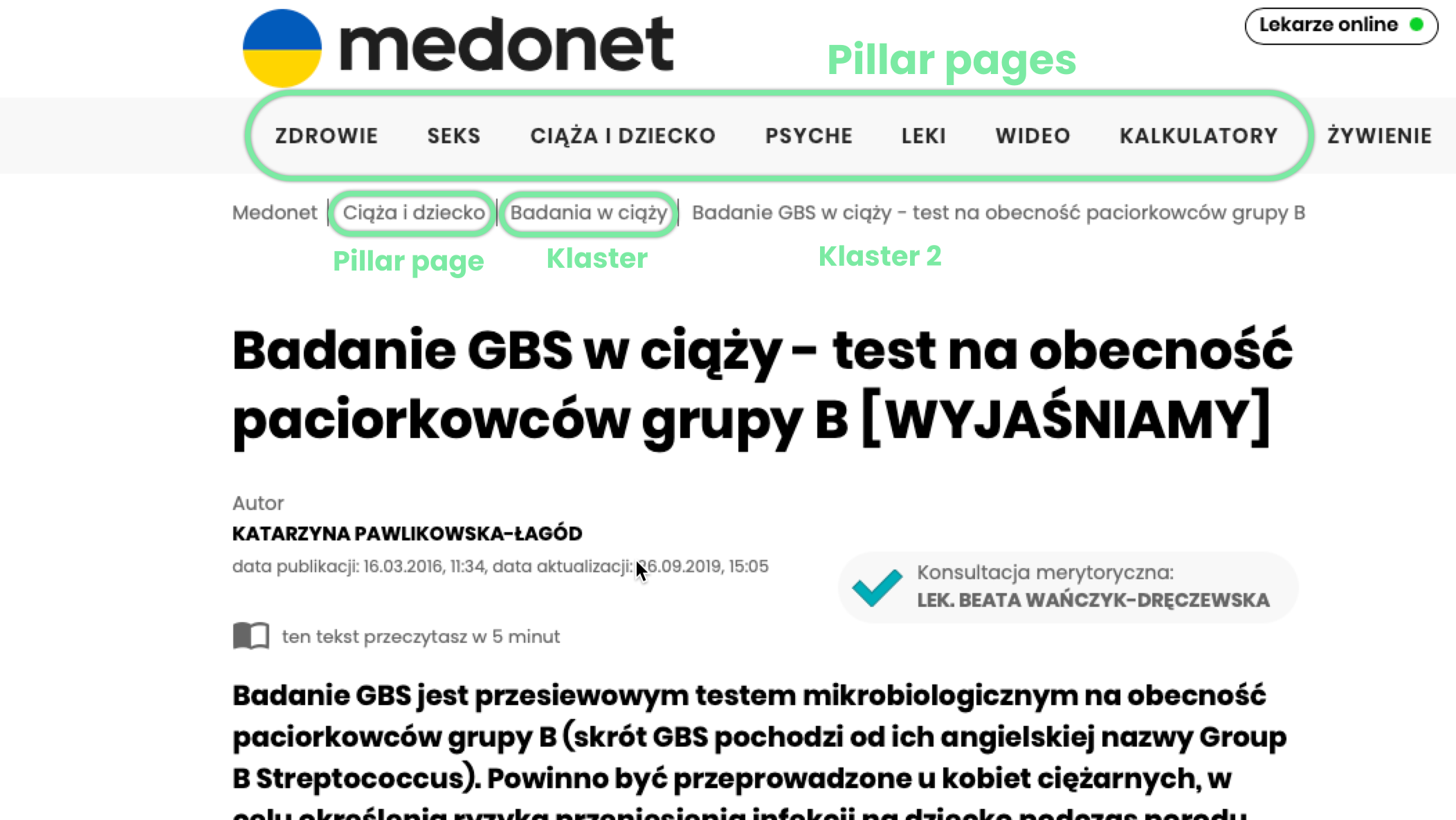
- Medonet organizuje architekturę wokół pillar pages (Zdrowie, Seks, Ciąża i Dziecko)
- Każdy pillar page posiada własną treść (https://www.medonet.pl/ciaza-i-dziecko,kategoria,157.html), która zawiera linki do klastrów
- Stosuje klastry powiązane z pillar page, które głębiej opisują temat
- Struktura adresów URL oraz breadcrumbs przekazuje pełną ścieżkę do klastra najniższego rzędu
- Architektura informacyjna jest dość płaska, wszystko znajduje się maksymalnie kilka kliknięć od strony głównej
- Wszystkie linki wewnętrzne są ściśle powiązane z klastrem (jak na zrzucie ekranu poniżej)

https://www.medonet.pl/ciaza-i-dziecko/rozwoj-dziecka,kategoria,164.html
Efektem tego są bardzo wysokie pozycje Medonetu w wynikach wyszukiwania, które utrzymują się od długiego czasu.
Drugim, nie do końca dobrym przykładem może być serwis zdrowie.wprost.pl.
źródło: https://zdrowie.wprost.pl/dziecko/rozwoj-dziecka
Co prawda na pierwszy rzut oka struktura wydaje się podobna do Medonetu, ale:
- Strony pillar page są puste (np. Rozwój dziecka zawiera tylko linki do artykułów)
- Struktura adresów URL ani breadcrumbs nie przekazują ścieżki
- Linkowanie wewnętrzne jest źle zorganizowane. Klaster o rozwoju dziecka zawiera bardzo dużo nie powiązanych linków (screen poniżej)

Pomimo, że serwis zdrowie.wprost.pl ma w teorii więcej podstron zaindeksowanych w wyszukiwarce, to jego widoczność jest prawie 10x niższa.
Przy tej okazji chciałem zaprosić Cię do sprawdzenia oferty automatyzacji linkowania wewnętrznego. Vestigio korzysta z autorskiego algorytmu, by dostarczyć Ci gotowy przepis na linkowanie wewnętrzne w ramach Twojego serwisu. Dla Ciebie jest to istotne wsparcie na drodze po wyższe pozycje w Google. Kliknij banner poniżej.

Jak ważna jest aktualizacja treści w semantycznym SEO
W świecie SEO od dawna istnieje przeświadczenie, że Google premiuje strony, które często dodają nowy content i aktualizują ten, który już opublikowały.
W zakresie aktualizacji treści i semantycznego SEO istotne są dwa patenty Google:
Pierwszy to Document scoring based on document content update.
W patencie tym przeczytamy:
A system may determine a measure of how a content of a document changes over time, generate a score for the document based, at least in part, on the measure of how the content of the document changes over time, and rank the document with regard to at least one other document based, at least in part, on the score.
Z tego można wywnioskować, że:
- Google może badać zmiany w dokumencie w czasie
- i na tej podstawie tworzyć scoring danego dokumentu.
W patencie możemy wyczytać również, według jakiego wzoru wyliczana jest ocena.

U (content update score) składa się z trzech elementów:
- f – suma, która określa, że wzór może się odnosić zarówno do pojedynczego dokumentu, jak i do wielu dokumentów sumarycznie
- UF – określa jak często dokument jest aktualizowany
- UA – określa jak bardzo dokument został zmieniony
Co to oznacza w praktyce?
- Źródła, które aktualizowane są częściej mogą zyskiwać pozycje w wynikach wyszukiwania.
- Im więcej treści dodajemy, tym wyższy scoring uzyska nasza witryna – dodanie nowych treści pozytywnie wpłynie również na te dodane wcześniej (o ile są zbieżne tematycznie).
- Warto aktualizować stare treści, zwłaszcza takie, gdzie intencja użytkownika może się zmieniać w czasie.
W zakresie zmiany intencji w czasie istnieje drugi patent Google: Query Deserves Freshness (QDF).
Według definicji:
QDF (Query Deserves Freshness) – a mathematical model that tries to determine when users want new information and when they don’t. (Model matematyczny, który stara się określić, kiedy użytkownik chce, a kiedy nie chce otrzymać nową informację.)
Google na bazie analizy blogów i magazynów, portali newsowych oraz analizy zapytań ocenia, czy użytkownicy dla danego zapytania oczekują nowej treści. W przypadku takich zapytań, w wyszukiwarce najczęściej zaczyna pojawiać się snippet Google news, natomiast Google może też wtedy aktualizować zwykłe wyniki wyszukiwania.
Co z tego wynika?
Warto obserwować trendy i aktualizować te treści, które mogą wymagać nowej wiedzy.
Mity w obszarze semantycznego SEO
W zakresie topical authority i semantycznego SEO wyrosło wiele mitów. Chciałbym się w tej części artykułu z nimi rozprawić.
1. Długość treści ma znaczenie
W wielu artykułach, nawet tych poruszających zagadnienie topical authority, spotkamy się ze stwierdzeniem, że istotnym czynnikiem w budowaniu autorytetu jest długość treści i że jest ona jednym z czynników algorytmicznych.
Po lekturze treści tego artykułu domyślasz się pewnie, że tak nie jest. Długość treści sama w sobie nie ma znaczenia dla wyszukiwarki.
Treść powinna być tak długa, jak wymaga tego użytkownik. W niektórych wyszukiwaniach intencją użytkownika jest czytanie długich treści, w innych nie. W niektórych przypadkach zbyt długa treść może nawet obniżać pozycję.
Przeprowadziłem badanie, które ma udowodnić moją tezę.
- W badaniu wziąłem pod uwagę 209 411 fraz
- Badałem treści zamieszczone na 66 072 unikalnych domenach
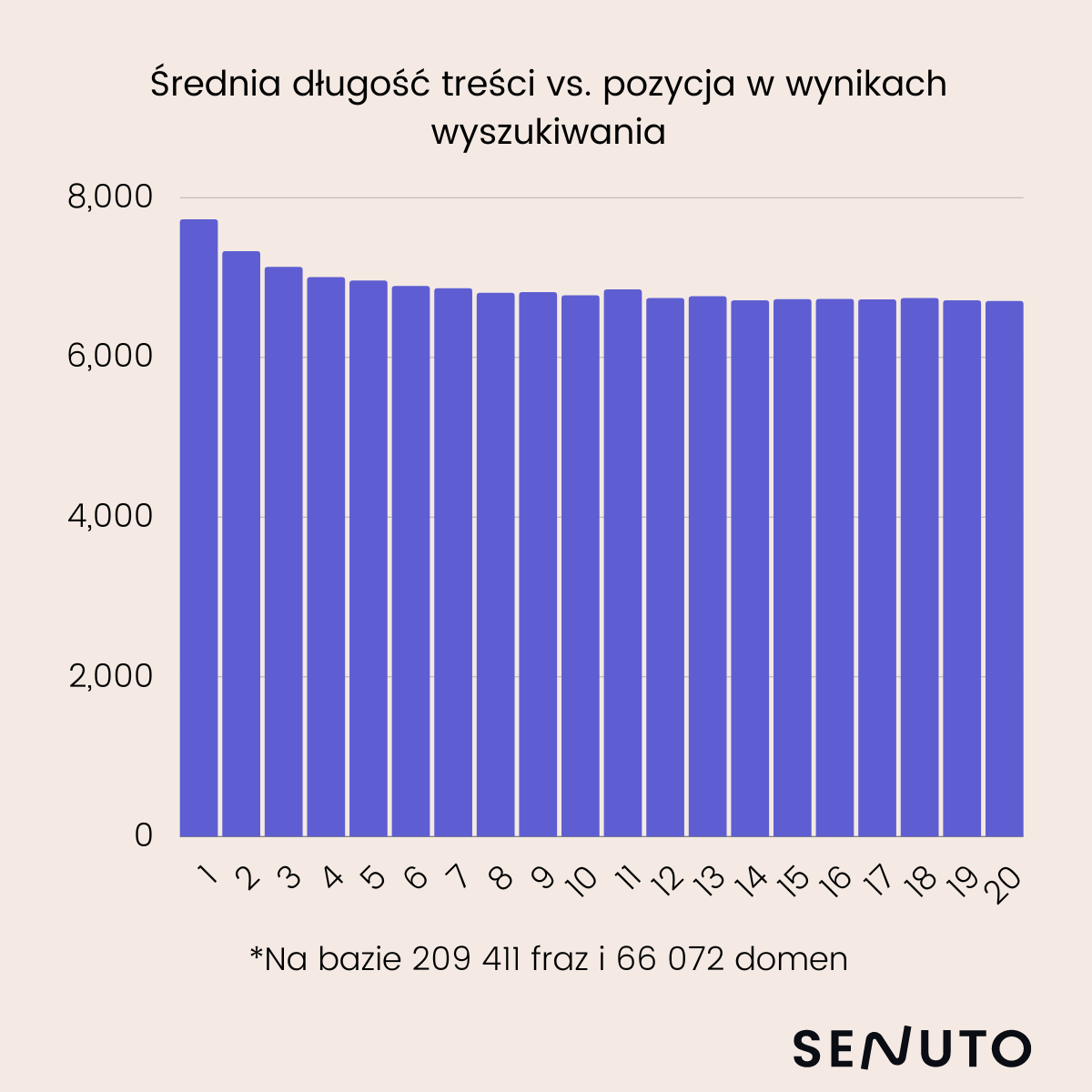
Tak prezentuje się średnia długość treści (w znakach) na poszczególnych pozycjach w TOP10 wyników wyszukiwania:
A tak prezentuje się % najdłuższych tekstów na poszczególnych pozycjach w wynikach wyszukiwania:
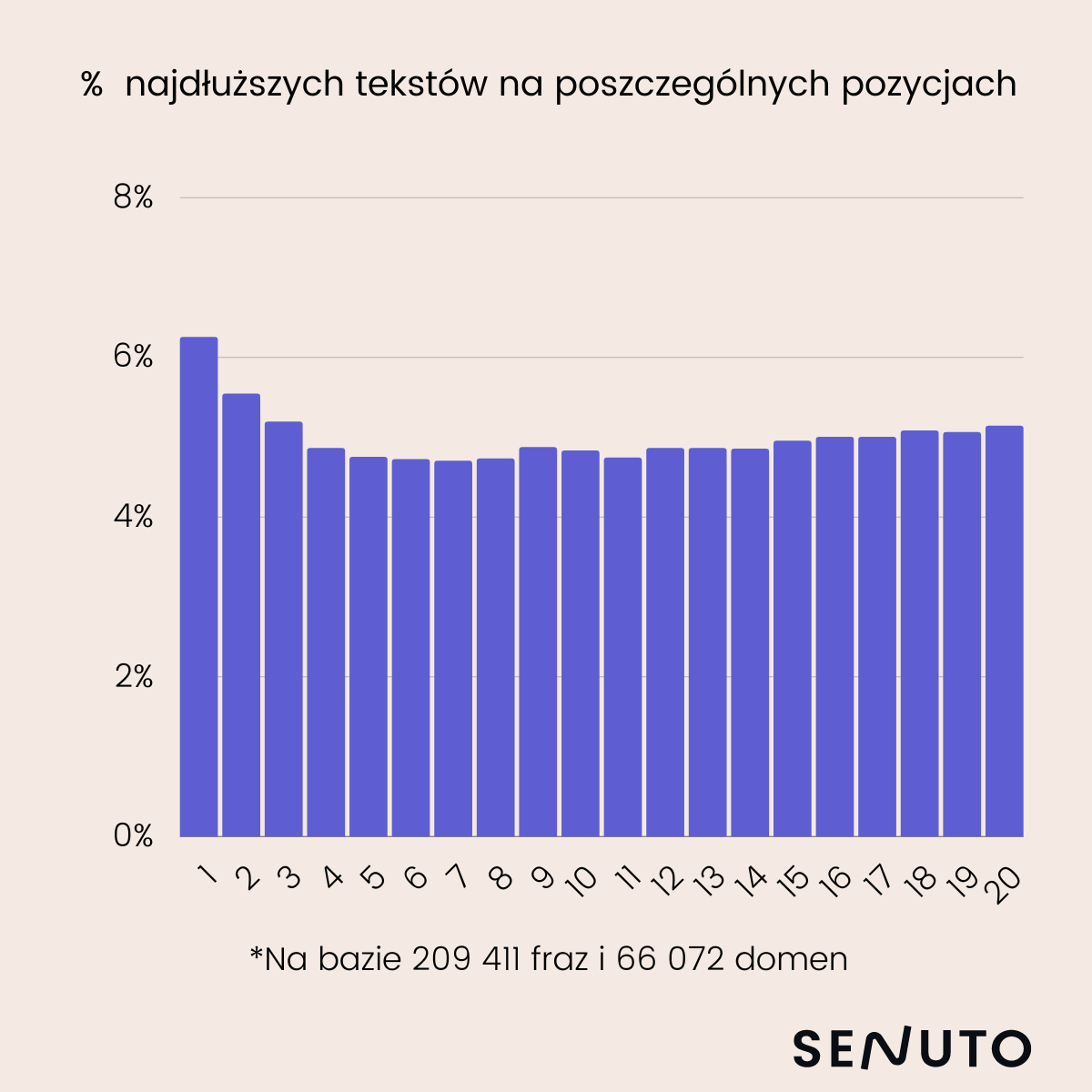
Badając korelację długości treści z pozycją otrzymujemy wynik 0,08.
Nie warto więc skupiać swojej uwagi na długości treści. Nadrzędnym celem powinno być zaspokojenie intencji użytkownika. Treść powinna pokrywać wszystkie pojęcia, entities i konteksty w danym zestawie pojęć w jak najprostszej i najkrótszej formie.
Tu może pojawić się pytanie: co w takim razie z wytycznymi dla copywriterów w zakresie długości artykułów?
Zalecam, aby długość treści w briefie dla copywritera była rekomendacją, pewnym punktem odniesienia, a nie sztywnym wymogiem. W tym zakresie bardzo przydatne są wytyczne, jakie podaje narzędzie Content Planner w Senuto.
Sprawdź Content Plannera od Senuto Przejdź do aplikacji
Aspekt długości treści można pominąć w specyficznych sytuacjach – kiedy copywriter jest bardzo doświadczony i rozumie działanie SEO w zakresie, jaki został tutaj opisany. Natomiast copywriterów z wiedzą o SEO na takim poziomie jest raczej niewielu, więc rekomendacje w sprawie długości treści nadal będą wartościową wskazówką.
2. Google nie rozumie języka polskiego
Regularnie słyszę takie stwierdzenie.
Google ma modele NLP zdolne do przetwarzania języka polskiego (takie jak BERT). Być może nie są one tak dobrze wytrenowane dla języka polskiego jak dla języka angielskiego, ale działają z wysoką skutecznością. Niech za przykład służy wytrenowany przez Allegro model BERT-a, który opisałem rozdziale o historii rozwoju algorytmów Google.
Czasem w wynikach wyszukiwania zdarzy się oczywiście błąd, ale pojedynczy przypadek nie powinien stanowić podstawy do wysnuwania takich wniosków.
Za kolejny przykład może posłużyć model GPT-3, za pomocą którego możemy między innymi automatycznie generować treści. Z językiem polskim radzi sobie bardzo dobrze. Google dysponuje podobnymi, a nawet lepszymi modelami.
3. LSI keywords mają istotny wpływ na semantyczne SEO
W wielu artykułach na temat topical authority znajdziemy informacje, że to zagadnienie powiązane jest z LSI (latent semantic indexing) keywords – to takie słowa i wyrażenia, które są semantycznie powiązane z tematem głównym treści.
Jeśli treść jest na temat podnoszenia ciężarów, to wedle tej teorii powinniśmy używać też takich słów jak: siłownia, zrzucanie wagi, trener personalny.
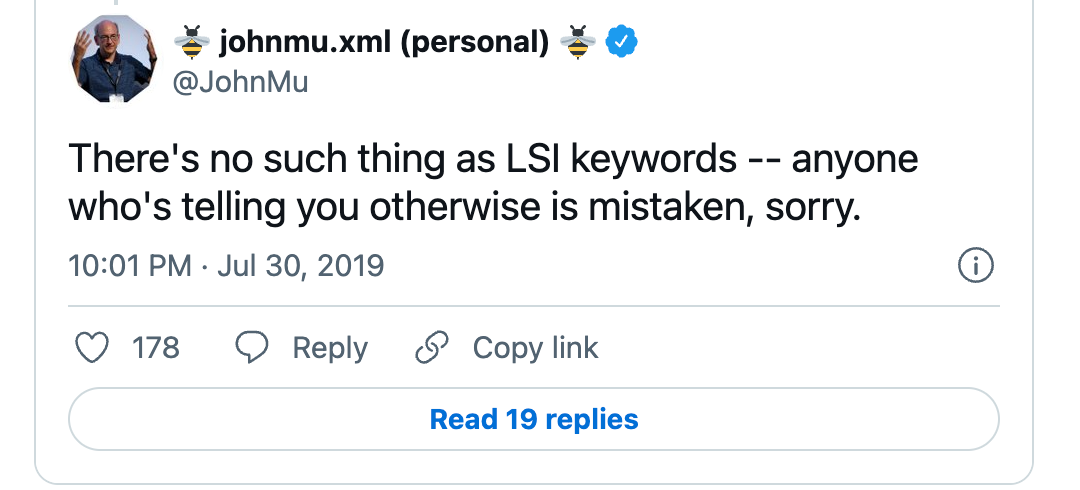
Sam John Muller w jednym ze swoich tweetów podkreślił, że LSI keywords nie istnieją:
Latent semantic indexing to metoda pochodząca z 1980 roku (ponad 40 lat!). To prosta technika NLP, której zadaniem jest badanie relacji słów z dokumentami zawierającymi te słowa.
Google mając do dyspozycji technologie takie jak neural matching czy RankBrain nie używałby tak starej technologii.
Wiele osób sugerujących używanie LSI keywords myli je z tym, że Google używa synonimów i semantycznie powiązanych słów. To są zupełnie dwa różne procesy.
Nie korzystaj zatem z narzędzi do wyznaczania LSI keywords i ich rekomendacji.
Jak wykorzystać techniki semantycznego SEO w praktyce?
Znasz już całkiem sporo pojęć z tematyki semantycznego SEO, w tej części artykułu zajmiemy się praktyką.
Poniżej znajdziesz listę porad dotyczących tego, jak wcielić tę wiedzę teoretyczną w Twoją codzienną pracę.
1. Zmień myślenie o słowach kluczowych
Wspominałem, że dzięki Rank Brain nie musisz skupiać się tak mocno na długim ogonie. Google frazy spełniające tę samą intencję grupuje razem. Dzięki temu możesz występować wysoko na frazy, których nawet nie masz w treści.
Twoim celem powinny być dwie rzeczy:
- Ontologia: opisanie pojęć jak największą liczbą atrybutów w jak najprostszej formie.
- Taksonomia: odpowiednie ich ułożenie w strukturze serwisu.
Oczywiście nie porzucaj w ogóle słów kluczowych. Google nadal analizuje strony pod tym kątem. Nie musisz jednak używać w tekście zarówno “co robić w Warszawie” jak i “atrakcje Warszawy”.
Google przede wszystkim ma rozumieć treść i strukturę strony. Jeśli Twoja strona pojawia się w snippecie direct answer może to oznaczać, że Google radzi sobie z jej analizą.
2. Zachowaj logiczną strukturę w treści
W wytycznych dla quaility team możemy przeczytać, że Google dzieli content na 3 części:
- Main content (treść główna)
- Ads (reklamy)
- Supplementary Content (treść uzupełniająca)
Google za istotniejszą treść traktuje tę znajdującą się w sekcji “above the fold” (przed scrollowaniem). Dlatego poczynając od znacznika title warto umieszczać u góry najważniejsze informacje, a niżej mniej istotne i bardziej szczegółowe.
Google posiada między innymi patenty w zakresie analizy nagłówków treści. Dlatego cała treść powinna być bardzo logicznie skomponowana:
- Najważniejsze treści należy przekazywać w nagłówkach najwyżej umieszczonych.
- Każdy nagłówek i treść pod nim powinny przekazywać unikalną informację. Jeśli dwa nagłówki są na ten sam temat – połącz je.
Szukasz idealnych fraz kluczowych? Przejdź do Bazy Słów Kluczowych
3. Wypełniaj luki wiedzy
Staraj się dostarczać unikalną wiedzę w danej tematyce, taką, której użytkownik nie znajdzie w TOP10 wyników wyszukiwania. Nie staraj się tylko powielać tego, co już znajduje się w TOP10 wyników wyszukiwania.
Nie skupiaj się tylko na słowach kluczowych, które mają dużą liczbę wyszukiwań. Te, które mają bardzo mało wyszukiwań lub nie mają ich w ogóle, również są warte odpowiedzi. Dlatego nie wykluczaj fraz, które według Bazy słów kluczowych Senuto mają np. 0 czy 10 wyszukiwań w miesiącu – być może nie złapiesz dzięki nim ruchu z Google (przynajmniej na razie!), jednak będą one wpływać na ocenę treści przez Google.
Szukasz idealnych fraz kluczowych? Przejdź do Bazy Słów Kluczowych
4. Używaj słownika schema.org do opisywania swojej witryny
Pomimo, że użycie schema.org nie wpływa bezpośrednio na pozycje w wynikach wyszukiwania, to pozwala wyszukiwarce lepiej rozumieć strukturę Twojej witryny – a więc jest dla Ciebie korzystne.
5. Publikuj regularnie i odświeżaj treści
Regularne publikowanie zwiększy Twój update score, co przełoży się na lepszy crawl budget. Twoje treści będą się indeksować szybciej.
Odświeżanie treści, którym zmieniła się intencja jest równie istotne.
6. Patrz szeroko na intencję
Staraj się dopasować rodzaj treści do oczekiwań użytkownika.
Jeśli w wynikach wyszukiwania pojawiają się głównie krótkie treści, to nie pisz na przekór długiego artykułu. Jeśli w wynikach wyszukiwania pojawiają się listy czy tabele, spróbuj je dodać do swojej treści. Intencja użytkownika to nie tylko rodzaj podstrony jaki chcemy mu wyświetlić. Trzeba podejść do tematu znacznie bardziej szczegółowo, pogłębiając swoje zrozumienie tego, jakie potrzeby użytkowników zaspokajają wyniki z TOP10 Google. Z tych wyników jesteśmy w stanie wyczytać, czy intencją użytkownika jest długi tekst, czy treść sformatowana w formie tabeli, czy może coś jeszcze innego.
7. Nie patrz na długość treści
Długość treści nie ma znaczenia w SEO. Treść powinna być tak krótka, jak to możliwe. SEO to nie wyścig na długość treści, tylko na zaspokojenie intencji użytkownika. Ponownie: analizuj wyniki z TOP10 Google. Jeśli widzisz, że użytkownik przede wszystkim oczekuje długiej treści – napisz taki artykuł, jeśli oczekuje zwięzłej informacji – taką dostarcz.
Działaj zgodnie z logiką: jeśli użytkownik wpisuje ogóle zapytanie (jak np. “SEO”), to najpewniej oznacza, że szuka ogólnych informacji i musisz mu dać więcej wiedzy niż w przypadku specyficznych zapytań (np. “jak robots.txt wpływa na SEO”). Tekst odpowiadający na ogólne zapytanie z reguły będzie dłuższy.
Miej na uwadze, że w niektórych przypadkach zbyt długa treść może wpływać niekorzystnie na Twoją pozycję.
8. Używaj krótkich zdań i sformułowań
Modele NLP znacznie lepiej radzą sobie z rozumieniem krótkich zdań (możesz to przetestować w Google NLP API w opcji “dependency tree”). Taki sposób pisania z reguły jest również lepiej przyswajany i preferowany przez użytkowników.
9. Uważaj na wyrażanie własnych opinii w treściach
Google za pomocą modeli machine learningowych stara się rozpoznać co w treści jest opinią, a co faktem (wykorzystując między innymi słowniki entity). Zazwyczaj Google mniej chętnie prezentuje w wynikach wyszukiwania opinię autorów treści, dlatego zamiast bazować na swoich opiniach – skupiaj się na faktach.
Więcej na ten temat przeczytasz na stronie SEO by the sea.
10. Wykaż się cierpliwością
Każdy specjalista SEO jest nauczony cierpliwości. Nie inaczej jest w przypadku semantycznego SEO.
- Treści publikujemy regularnie, zwiększając ich ilość w czasie
- Budujemy sieć linków wewnętrznych
W niektórych przypadkach zbudowanie wysokiego topical authority może wymagać napisania kilkuset artykułów. Dodatkowo wyszukiwarka potrzebuje czasu, aby zrozumieć strukturę witryny i zaklasyfikować ją jako wartościowe źródło informacji. Kilka miesięcy to dobry czas, aby zacząć oczekiwać efektów.
Jak w semantycznym SEO pomoże Ci Senuto?
Już od 2016 w ofercie mieliśmy usługę planowania treści, zgodnego z zasadami semantycznego SEO. Chcemy w tym kierunku rozwijać też naszą aplikację. Jednym z modułów, który może wesprzeć budowanie silnego topical authority jest nasz Content Planner Senuto. W tej części artykułu przekonamy się, w jaki sposób to narzędzie odpowiada na zagadnienia opisywane w artykule.
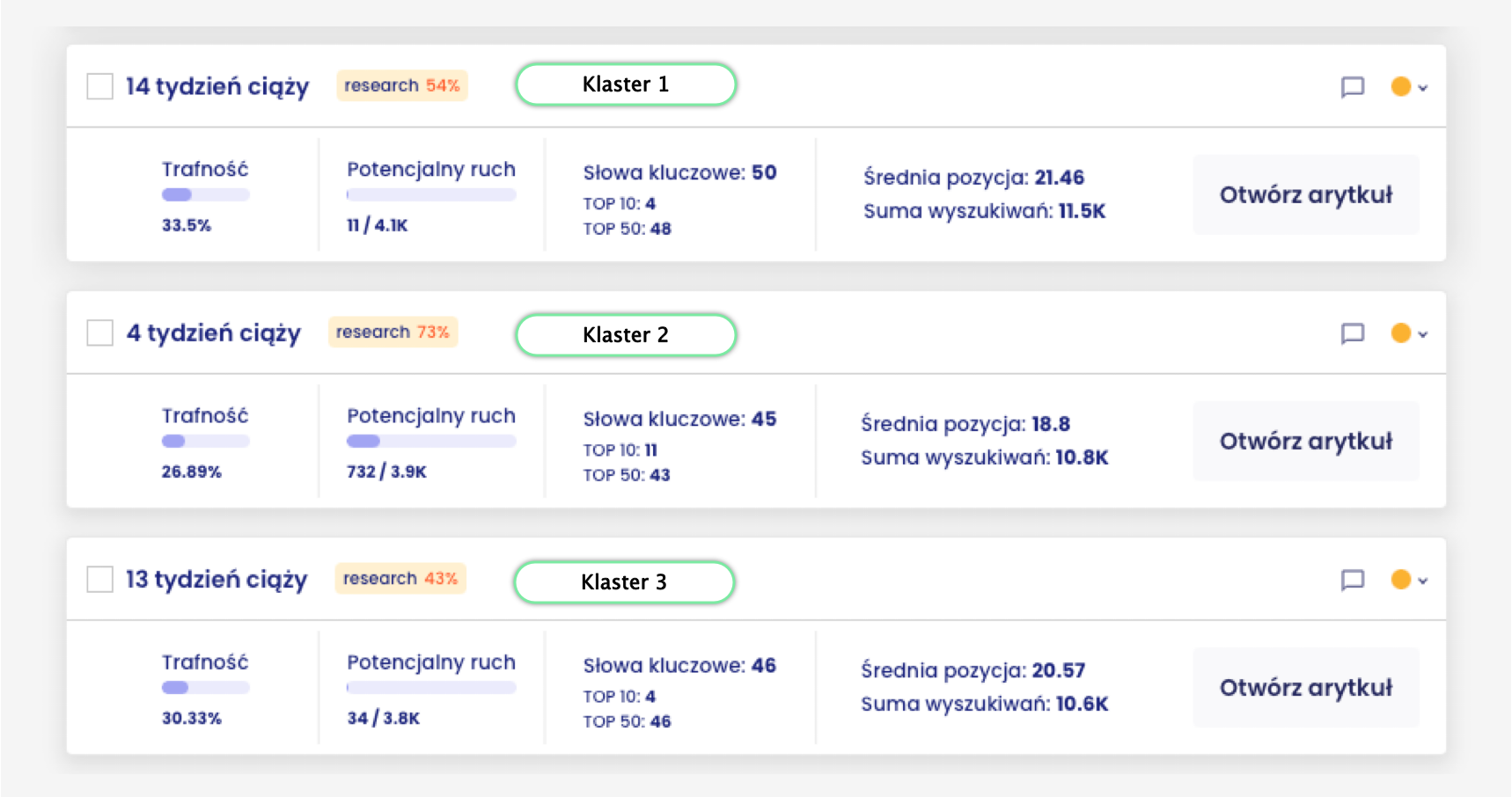
Na powyższym wykresie znajdują się trzy przykładowe klastry tematyczne z obszaru ciąży. Dla każdego z nich Content Planner wyznacza:
- Potencjalny ruch
- Liczbę słów kluczowych przypisaną do klastra
- Obecną widoczność serwisu w ramach danego klastra
Pojedynczy klaster odwzorowuje pojedynczy artykuł lub podstronę, którą należy utworzyć (lub zoptymalizować obecną) w serwisie. Słowa kluczowe przypisane do klastra to te, na które docelowo utworzona podstrona powinna pojawić się w wynikach wyszukiwania.
Klastry łączone są również w grupy wyższego poziomu, przy pomocy technik grafowych. Grupy te mają za zadanie odwzorować umieszczenie poszczególnych klastrów obok siebie w architekturze informacji serwisu (pamiętasz fragment tekstu o pillar pages oraz klastrach niższego i wyższego rzędu?). Pomiędzy klastrami w jednej grupie warto dodawać też linki wewnętrzne.
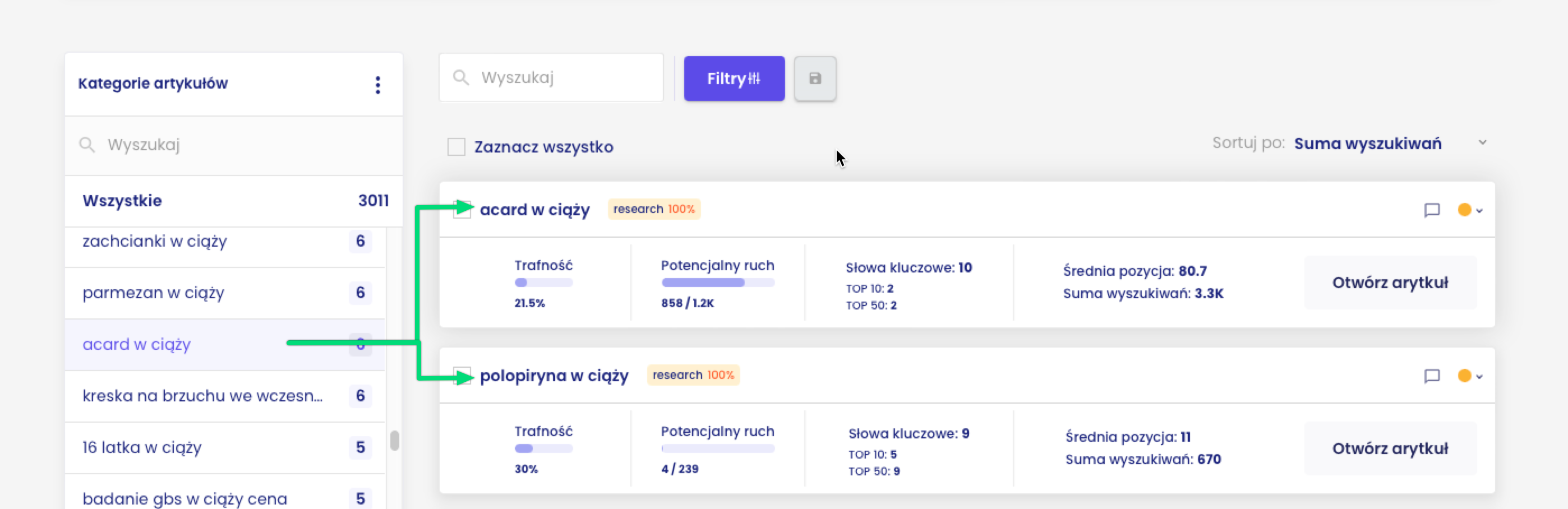

Np. klaster “żelazo w ciąży” ma przede wszystkim intencję research (interpretacja dominująca, 93%) ale również intencję transactional (intencja powszechna, 47%).
Dla jeszcze lepszego zrozumienia intencji użytkownika system przeprowadza analizę wyników wyszukiwania – można sprawdzić, co dokładnie znajduje się w tych wynikach dla słów kluczowych przypisanych do klastra.
Pierwszym istotnym elementem są snippety występujące w wynikach wyszukiwania.
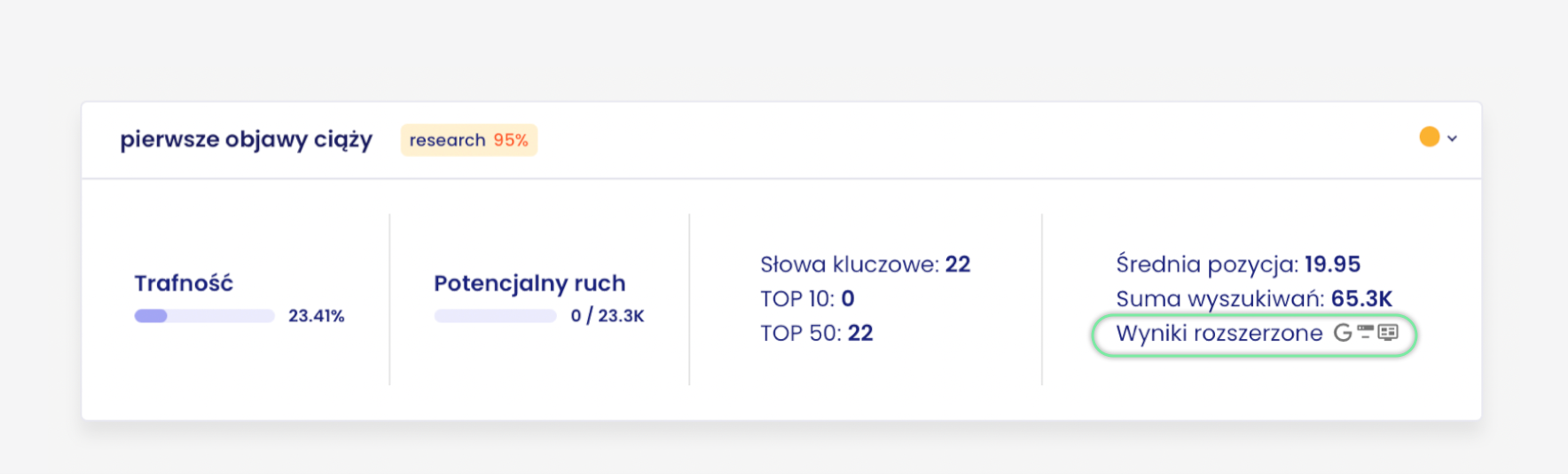
Dla klastra “pierwsze objawy ciąży” dominującym snippetem jest direct answer (występuje na 14 z 22 słowach kluczowych).
Drugim istotnym elementem jest analiza konkurencji.
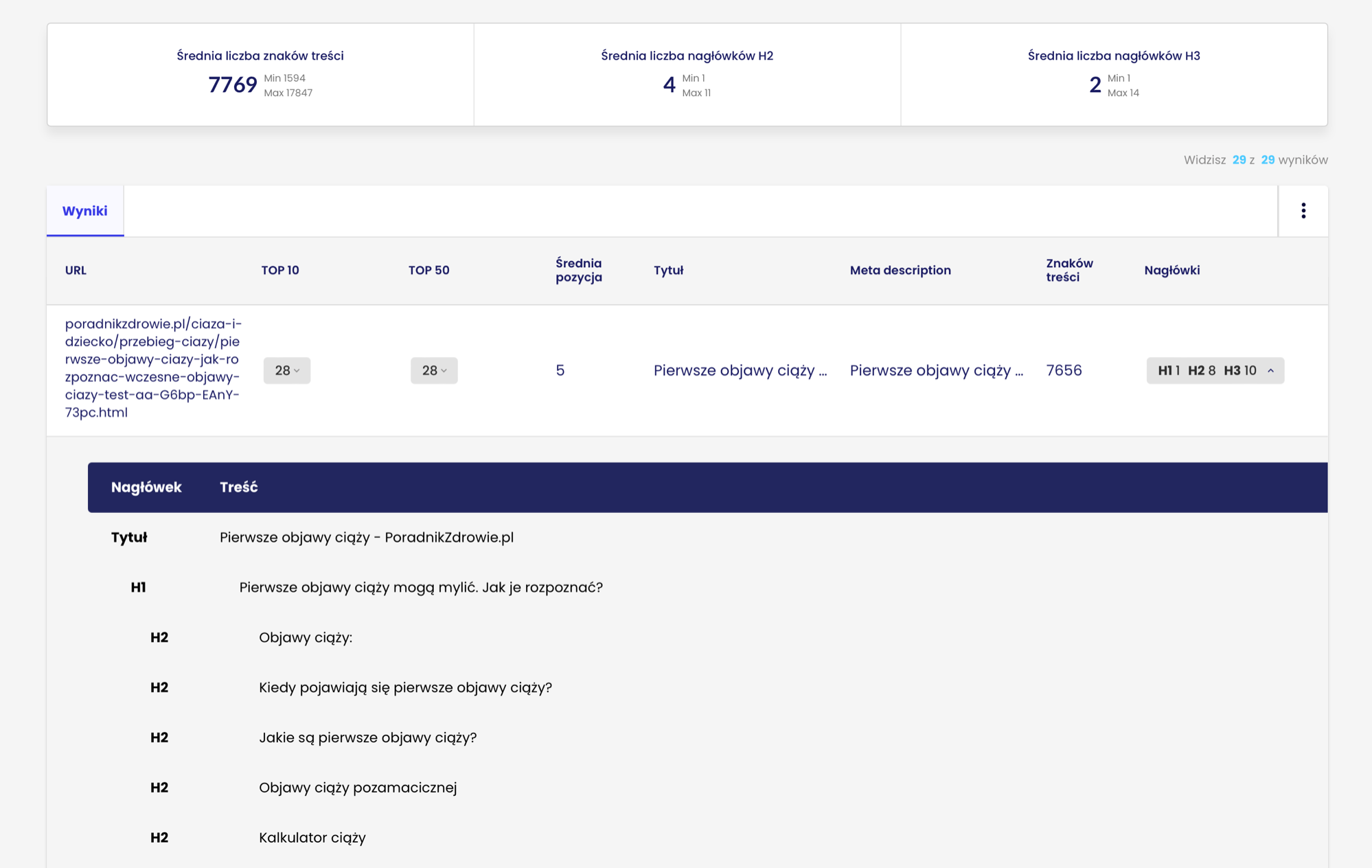
System analizuje takie parametry jak:
- Średnia długość treści konkurencji
- Liczba nagłówków
- Liczba linków wewnętrznych
- Meta dane
- Struktura nagłówków każdego z konkurentów
Taka analiza to zestaw istotnych wskazówek, w jaki sposób odpowiedzieć na intencję użytkownika swoją treścią.
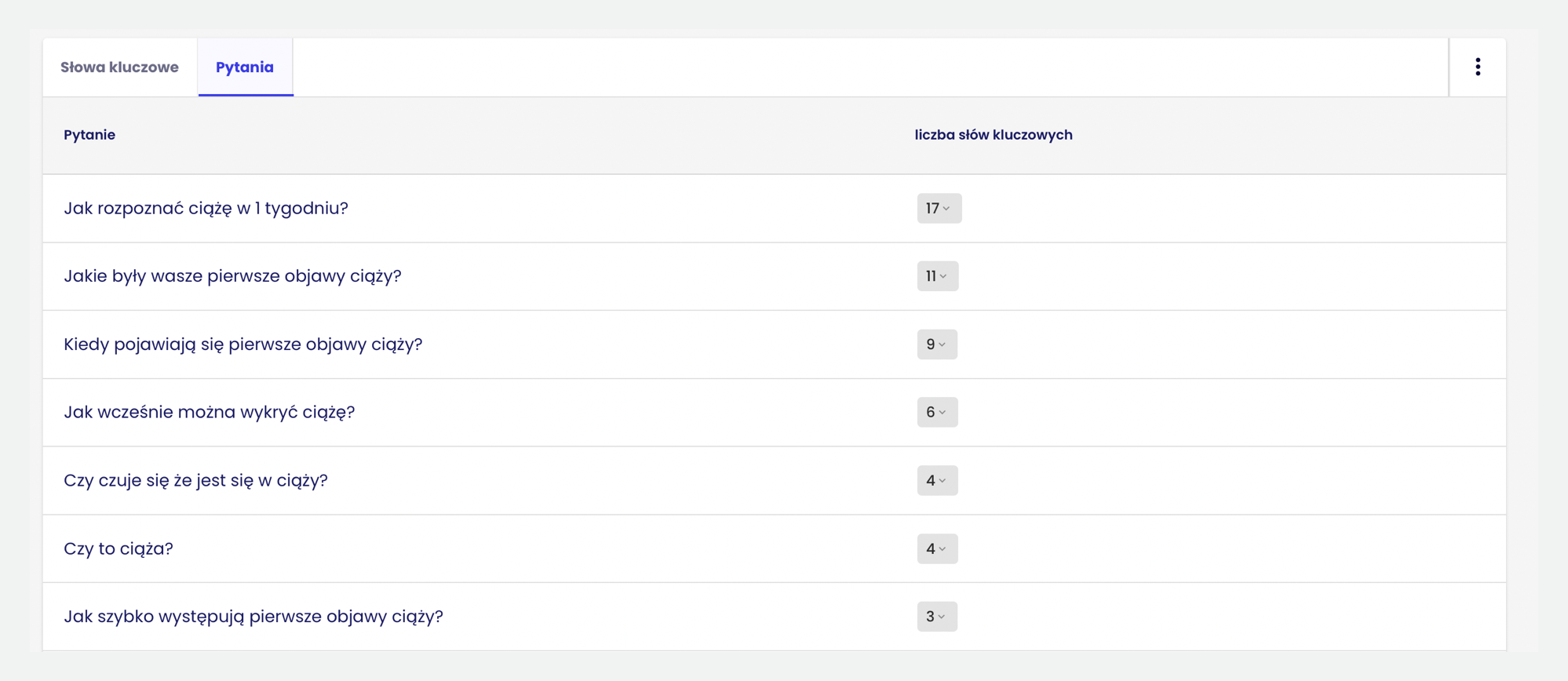
Dodatkowo system podpowiada, na jakie pytania użytkowników powinieneś odpowiedzieć w swojej treści. Z lektury tego artykułu wiesz, jak bardzo jest to istotne.
Jeśli chcesz dokonać klasteryzacji na własnoręcznie przygotowanej bazie słów kluczowych, możesz wykorzystać narzędzie Grupowanie słów kluczowych w Senuto.
Jeśli jeszcze nie korzystasz z Content Plannera Senuto, koniecznie go wypróbuj wraz z drugim, komplementarnym modułem Content Writer.
Oba te moduły są dla nas kamieniem milowym w opracowaniu narzędzia, które pozwoli Ci w pełni zapanować nad procesem semantycznego SEO.
Przyszłość semantycznego SEO
Patrząc historycznie na rozwój wyszukiwarki nietrudno przewidzieć, że jej przyszłość będzie bardzo interesująca. Google będzie na pewno rozwijał kolejne NLP i inne modele machine learningowe, żeby jeszcze lepiej zrozumieć intencję użytkownika i jeszcze lepiej na nią odpowiadać. Zmiany będziemy obserwować w perspektywie najbliższych lat. Wzrost możliwości AI rośnie wykładniczo.
Obecnie znajduję jedną zmianę, która w najbliższym czasie może mocno namieszać w wynikach wyszukiwania.
Multitask Unified Model (MUM)
Google już w maju 2021 ogłosił kolejną dużą zmianę w sposobie analizy informacji i prezentowania jej użytkownikowi – wprowadzenie do wyszukiwarki modelu MUM, Multitask Unified Model. Multitask to słowo klucz. Nie jest to model NLP jak BERT, który służy do przetwarzania języka. MUM potrafi przetwarzać i rozumieć różnego rodzaju treści (tekst, obrazy, video, audio). Według zapewnień Google jest on 1000 (!) razy skuteczniejszy od BERT-a.
Poniższe grafiki przedstawia, w jaki sposób będzie działać MUM:

Zapytanie…

…i odpowiedź
Mum będzie potrafił połączyć zdjęcie z zapytaniem i udzielić kompleksowej informacji, w tym przypadku: czy mogę wspiąć się w tych butach na górę Fuji?
MUM działa w oparciu o model T5 (Text-To-Text Transfer Transformer), który Google opublikował w 2020 roku. Jest to model open-source (tak jak BERT) – co oznacza, że jeśli chcesz go wypróbować, możesz wykorzystać model przygotowany przez inżynierów Google Colab.
Tak jak w przypadku BERT-a, można przeprowadzić fine-tuning T5 do różnych zadań.
Kompleksowość modelu T5 prezentuje poniższa grafika:
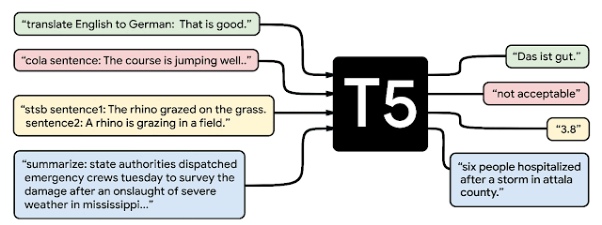
źródło: https://ai.googleblog.com/2020/02/exploring-transfer-learning-with-t5.html
Celem tej zmiany jest dostarczenie użytkownikowi informacji w mniejszej niż do tej pory liczbie zapytań. Powyżej opisane zasady będą miały jeszcze większe znaczenie.
Google korzysta również z autorskiego modelu językowego PaLM, który jest wytrenowany na 540 miliardach parametrów.
Dla porównania model GPT-3, który jest ostatnio bardzo popularyzowany przez różne narzędzia do automatycznego generowania treści został wytrenowany na 175 miliardach parametrów.
Poniższa grafika pokazuje do czego zdolny jest model w zależności od liczby parametrów:
źródło: https://ai.googleblog.com/2022/04/pathways-language-model-palm-scaling-to.html
W badaniu, w którym modele AI badane są pod kątem 200 różnych zadań (ich lista znajduje się tutaj), PaLM osiąga wyniki lepsze niż przeciętny człowiek.
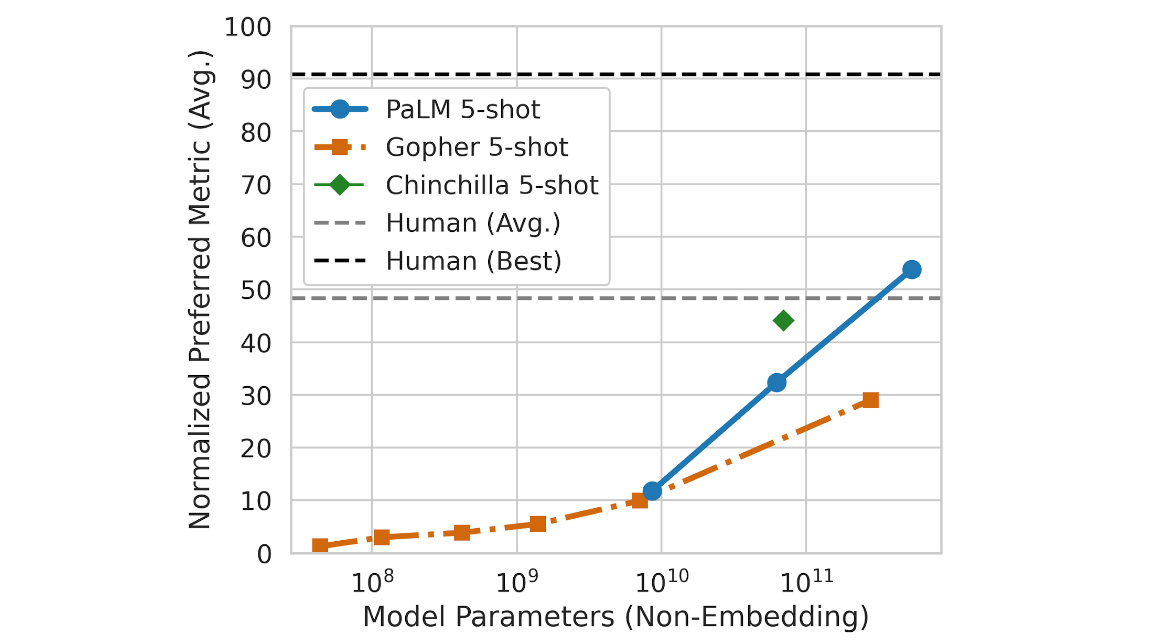
źródło: https://ai.googleblog.com/2022/04/pathways-language-model-palm-scaling-to.html
Znacznie lepiej radzi sobie też od innych popularnych modeli (między innymi GPT-3):
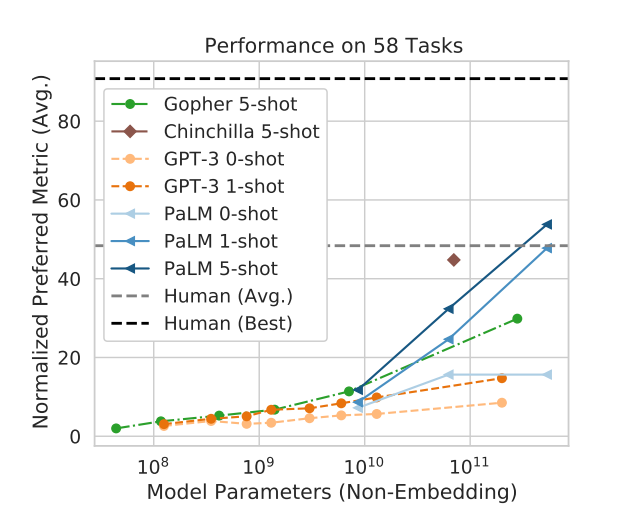
źródło: https://arxiv.org/pdf/2204.02311.pdf
Jednym z dobrych przykładów jest umiejętność tłumaczenia żartów.
źródło: https://ai.googleblog.com/2022/04/pathways-language-model-palm-scaling-to.html
Więcej o PaLM przeczytasz na blogu AI Google oraz tutaj (pdf).
Warto śledzićblog AI Google, ponieważ na bieżąco informują tam o swoich nowych osiągnięciach w dziedzinie sztucznej inteligencji. Lektura tego bloga daje dobre spojrzenie na to, jakimi zasobami dysponuje Google.
Liczba modeli i ich zdolności rosną w bardzo szybkim tempie. Już teraz mówi się, że model GPT-4, który ma zostać udostępniony za kilka lat, ma być wytrenowany na bazie 100 trylionów parametrów (do czego będzie zdolny?).
Jeśli Google będzie w stanie w dużej skali generować treści wysokiej jakości, to być może w przyszłości na proste pytania odpowiedzią będzie treść wygenerowana przez AI, a nie lista stron internetowych.
Zawsze jednak modele trenowane są na jakiejś bazie (np. GPT-3 przestał się uczyć w 2019), dlatego jeśli będziesz dostarczać nową i unikatową wiedzę zgodnie z zasadami opisanymi w tym artykule, to pozostaniesz w obszarze zainteresowania wyszukiwarek internetowych.
Zakończenie
Dziękuje Ci za lekturę. Mam nadzieje, że pojęcia semantycznego SEO są dla Ciebie jasne i zaczniesz wdrażać tę wiedzę w życie. Ze swojej strony mogę Cię zapewnić, że na naszym blogu będziemy aktualizować wiedzę na ten temat i dostarczać Ci najświeższą wiedzę z tego zakresu.

Damian Salkowski
CEO Senuto. Specjalista SEO z bagażem doświadczeń z rynku polskiego i rynków zagranicznych. Autor dwóch książek o marketingu internetowym i kilkuset artykułów w tej tematyce. Prywatnie fan piłki nożnej i sportów motorowych.
Wszystkie artykuły →