Duplikacja treści – znajdź i rozwiąż ten problem

Duplikacja treści jest istotnym problemem, który może prowadzić do obniżenia widoczności podstron, a tym samym znacząco zmniejszyć ruch organiczny w witrynie. Sprawdź, jak znaleźć zduplikowany content i sprawnie się z nim uporać.
Czym jest duplikacja treści?
Duplikacja treści jest zjawiskiem, które polega na powieleniu (zduplikowaniu) treści na podstronach w obrębie jednej witryny – duplikacja wewnętrzna; bądź na różnych stronach zewnętrznych – duplikacja zewnętrzna. Zatem, gdy ta sama treść pojawia się pod różnymi adresami URL, wówczas mamy do czynienia ze zjawiskiem znanym również pod nazwą duplicate content.
Do duplikacji może dojść w wyniku pomyłki, kradzieży contentu bądź poprzez powstanie błędów na etapie technicznej optymalizacji SEO witryny lub sklepu internetowego.
Problem zewnętrznej duplikacji treści w sektorze e-commerce sprowadza się zwykle do bezrefleksyjnego kopiowania opisów produktów bądź kategorii ze stron producentów.
Z duplikacją wewnętrzną mamy do czynienia zwykle w wyniku publikacji identycznych opisów, które dotyczą produktów różniących się między sobą jedynie detalem – np. rozmiarem czy kolorem.
Jaka jest różnica między duplikacją treści a kanibalizacją?
Różnica między duplikacją treści a kanibalizacją słów kluczowych jest dość istotna.
Duplikacją treści jest każdy nieunikalny (identyczny) content, który pojawia się pod więcej niż jednym adresem URL. Innymi słowy: duplikacja contentu powstaje, gdy na dwóch, trzech czy większej liczbie podstron w obrębie witryny bądź między różnymi serwisami, pojawi się taki sam większy fragment tekstu.
Z kanibalizacją słów kluczowych mamy do czynienia, gdy w obrębie jednego serwisu opublikowane zostaną różne podstrony z różną treścią, które optymalizowane są na takie same frazy kluczowe.
Kanibalizacja słów kluczowych jest zjawiskiem, które może dotyczyć wyłącznie jednego serwisu. Duplikacja treści może powstawać zarówno w obrębie jednego serwisu, jak i między zewnętrznymi witrynami.
Co więcej, w wyniku duplikacji treści może powstać równocześnie kanibalizacja słów kluczowych (te same frazy kluczowe w tej samej treści). Niemniej, kanibalizacja fraz nie prowadzi równocześnie do duplikacji treści (te same frazy kluczowe, inny content).
Czy duplikacja treści szkodzi SEO?
Zdecydowanie tak, duplikacja treści szkodzi SEO. I to bardzo. Duplicate content negatywnie wpływa na widoczność podstron ze zduplikowana treścią i może skutkować obniżeniem pozycji witryny w organicznych wynikach wyszukiwania.
Dlaczego duplikacja treści szkodzi pozycjonowaniu? Algorytmy Google, crawlując kilka URL-i witryny z takim samym contentem, nie wiedzą, która podstrona jest ważniejsza i którą mają pokazać wyżej w wynikach wyszukiwania.
W efekcie Google może zachować się na kilka sposobów.
- Po pierwsze, algorytmy Google mogą pokazać wszystkie adresy URL jeden obok drugiego, ale na zdecydowanie niższych pozycjach (np. na 2., 3. czy nawet 4. stronie).
- Po drugie, Google może wybrać tylko jeden adres URL według swojego widzimisię i wyświetlić go wyżej względem pozostałych adresów URL ze zduplikowanym contentem. To rozwiązanie może doprowadzić do tego, że użytkownikom na górze wyników wyszukiwania wyświetli się niekoniecznie właściwy adres URL.
- Po trzecie, Google może zwyczajnie zignorować każdy URL ze zduplikowaną treścią, co doprowadzi do spadku ratingu całej witryny.
Niezależnie od tego, jak Google potraktuje podstrony ze zduplikowaną treścią, możesz być pewny, że jego reakcja wpłynie negatywnie na widoczność strony, zmniejszy ruch organiczny i może zakłócić ścieżkę klienta w lejku, a tym samym zmniejszyć poziom konwersji.
Przyczyny duplikacji treści
Problem duplikacji contentu jest dość złożony i może dotyczyć zarówno sklepów internetowych, blogów, portali, jak i stron wizytówek. W zasadzie z duplikacją treści mogą spotkać się wszyscy, którzy publikują content w sieci.
Jakie są więc przyczyny duplikacji contentu? Wśród najczęstszych z nich należy wymienić:
- niepoprawnie wykonaną paginację (m.in. brak wdrożenia self-canonicali na każdej z podstron paginacji),
- zduplikowane opisy kategorii i produktów,
- niepoprawne wdrożenie certyfikatu SSL,
- pojawienie się podstron pod różnymi adresami URL,
- Nieprawidłowe zaimplementowanie wersji językowych w witrynie,
- zaindeksowanie strony deweloperskiej,
- niepoprawne parametry GET,
- skopiowanie dużych fragmentów treści z innych podstron (wewnątrz i na zewnątrz witryny),
- duplikacja meta znaczników.
Niepoprawnie wykonana paginacja
Źle wykonana paginacja może prowadzić do wielu problemów zarówno pod kątem UX, jak i SEO. Paginację zwykle wykorzystuje się do podziału podstron kategorii z dużą liczbą produktów lub do podzielenia obszernych publikacji.
Najczęściej problem paginacji wynika ze źle wykonanego przekierowania podstron.
Przykładowo, pierwsza strona z paginacją może być dostępna pod dwoma adresami:
- senuto.com/pl/kategoria
- senuto.com/pl/kategoria?p=1
Wówczas dochodzi do duplikacji treści całej podstrony.
Problem niepoprawnie wykonanej paginacji można rozwiązać poprzez stworzenie przekierowania 301 z powielonego adresu, czyli adres senuto.com/pl/kategoria?p=1 należy przekierować na adres senuto.com/pl/kategoria. Warto jednak tak zmienić skrypt, żeby parametr p=1 nie występował w adresie URL.
Zduplikowane opisy kategorii i produktów
Duplikacja opisów produktów i kategorii to jeden z najczęściej spotykanych problemów. Do duplikacji contentu na podstronach kategorii może dojść poprzez powielenie treści w wyniku paginacji lub podczas ustawiania filtrów bądź sortowania produktów w obrębie danej kategorii.
W takim przypadku można również wdrożyć tag link z atrybutem rel ustawionym na wartość canonical. Stosujemy go na zduplikowanych stronach i umieszczamy w kodzie link do głównej strony kategorii.
Do powielania opisów produktów dochodzi zwykle w sytuacji, gdy oferta produktowa obejmuje wiele pozycji, które nie różnią się między sobą w znaczący sposób – np. przewodów o różnych długościach czy płaskowników o zróżnicowanych wymiarach.
Rozwiązaniem takiej sytuacji również może okazać się tag rel=„canonical”, który zostanie umieszczony na każdej zduplikowanej stronie produktowej i będzie wskazywał na główny produkt. Alternatywnym rozwiązaniem może być wdrożenie sekcji z opiniami lub komentarzami. Dzięki nim użytkownicy wzbogacą treść na stronach produktów unikalnym contentem, co obniży lub całkowicie wyeliminuje problem zduplikowanej treści.
Do duplikacji treści opisów kategorii i produktów może dojść również w wyniku jej skopiowania ze strony producenta. W takim przypadku należy zadbać o to, aby treść na Twojej stronie była w 100% unikalna.
Niepoprawne wdrożenie certyfikatu SSL
Podczas wdrażania certyfikatu SSL do witryny, należy pamiętać o wykonaniu przekierowania z HTTP na HTTPS we wszystkich adresach URL. Częstym błędem jest albo niewykonanie takiego przekierowania, albo wykonanie go wyłącznie na kilku wybranych adresach (np. tylko na stronie głównej).
W takim przypadku, aby uniknąć duplikacji treści, należy wprowadzić globalne przekierowanie wszystkich adresów URL z HTTP na HTTPS.
Pojawienie się podstron pod różnymi adresami URL
Publikacja podstron witryny pod różnymi adresami URL może powstawać w wyniku większych bądź mniejszych błędów technicznych.
Najczęściej powstanie powielonych podstron wynika z:
- pojawienia się tych samych produktów w różnych kategoriach produktowych (adres URL zawiera nazwy kategorii, przez co produkt ma różne adresy),
- linkowania do tej samej strony z „.html” i bez,
- pojawienia się kategorii w różnych miejscach w strukturze sklepu internetowego.
W każdym z opisanych przypadków rozwiązaniem jest wykonanie przekierowania 301 z powielonych podstron na właściwy adres URL.
Nieprawidłowe zaimplementowanie wersji językowych w witrynie
Duplikacja treści w wyniku wdrożenia wersji językowych na stronie powstaje wtedy, gdy nie wszystkie podstrony zostaną przetłumaczone. Wówczas w obcojęzycznej wersji strony może pojawić się tekst opublikowany np.w języku polskim – ten sam, który już jest na „oryginalnej” stronie.
Aby rozwiązać ten problem, należy opublikować unikalną, przetłumaczoną treść na każdej z podstron, która ma być wyświetlana w obcym języku. Z kolei, gdy konkretna podstrona ma się nie wyświetlać w danym języku, wówczas można zastosować tag „noindex”.
Zaindeksowanie strony deweloperskiej
Czasem przez przypadek dochodzi do indeksacji strony deweloperskiej przed jej właściwą publikacją.
Jeśli strona internetowa nie jest jeszcze gotowa, wówczas wersję deweloperską należy zablokować przed indeksacją, wprowadzając tag „noindex”.
Niepoprawne parametry GET
Parametry GET służą przekazywaniu danych między kolejnymi odsłonami podstron w protokole HTTP. Ciągi znaków „typ=new” czy „sort=up” wykorzystywane są do generowania kodu HTML wedle preferencji klienta.
Problem z nadmierną liczbą parametrów GET w adresach URL dotyczy przede wszystkim sklepów internetowych. Wówczas, przy ustaleniu wielu filtrów produktowych, dochodzi do tworzenia się takich adresów URL:
- senuto.com/pl?typ=new&sort=up&page=2,
- senuto.com/pl?page=2&typ=new&sort=up,
- senuto.com/pl?sort=up&page=2&typ=new.
W takiej sytuacji każdy z powyższych adresów URL prowadzi do tej samej strony. Najłatwiej można rozwiązać ten problem poprzez wykonanie canonicala na właściwym adresie URL.
Skopiowanie większych fragmentów treści z innych podstron
Kopiowanie 1:1 dużych fragmentów treści i publikacja ich na własnej stronie, to nie najlepszy pomysł. Zwykle Google bardzo szybko dowiaduje się, że treść została skopiowana i ogranicza widoczność podstrony, która „pożyczyła” sobie content.
Jeśli skopiowana treść pochodzi z podstrony tego samego serwisu, wówczas obniżenie widoczności może spotkać każdą z podstron, która ma opublikowaną nieunikalną treść.
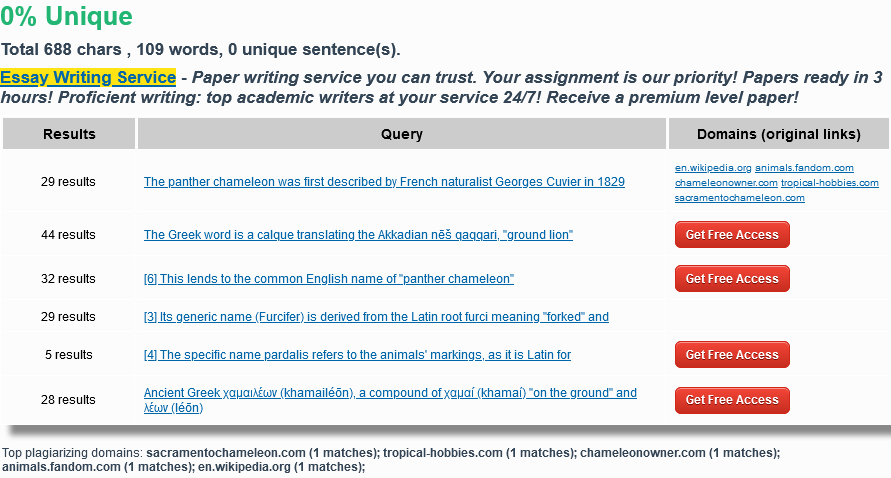 Źródło: Plagiarisma.net
Źródło: Plagiarisma.net
Uwaga: duplikacja treści w obrębie tego samego serwisu może wynikać również z pojawiania się tego samego tekstu w stopce strony. W takim przypadku dłuższy fragment tekstu ze stopki można zastosować wyłącznie na stronie głównej i usunąć go z pozostałych podstron.
Ofiarą duplikacji treści możesz również paść nie z własnej winy. Wystarczy, że ktoś skopiuje treść z Twojej strony i opublikuje ją u siebie. W takiej sytuacji warto najpierw spróbować skontaktować się z właścicielem strony z prośbą o usunięcie zduplikowanej treści. Sprawę warto również zgłosić do dostawcy hostingu.
Duplikacja meta znaczników
Kopiowanie znaczników Meta Title i Meta Description również nosi znamiona duplicate contentu. W takiej sytuacji nieunikalne znaczniki mogą przyczyniać się do obniżenia widoczności strony.
Rozwiązanie tego problemu jest proste – wystarczy stworzyć unikatową treść do meta znaczników.
Jak znaleźć zduplikowane treści na swojej stronie?
Istnieje kilka sposobów, dzięki którym można sprawnie znaleźć zduplikowany content w obrębie własnej witryny. Do najczęściej stosowanych rozwiązań zalicza się:
- manualną analizę witryny,
- crawlery internetowe,
- Google Search Console,
- wprowadzanie fragmentów treści bezpośrednio do wyszukiwarki.
Manualna analiza witryny
Jest to najbardziej czasochłonne rozwiązanie, które może okazać się trafnym sposobem szukania zduplikowanej treści na małych stronach internetowych. Niemniej, w przypadku bardziej rozbudowanych stron warto wykorzystać inne metody opisane poniżej.
Crawlery internetowe
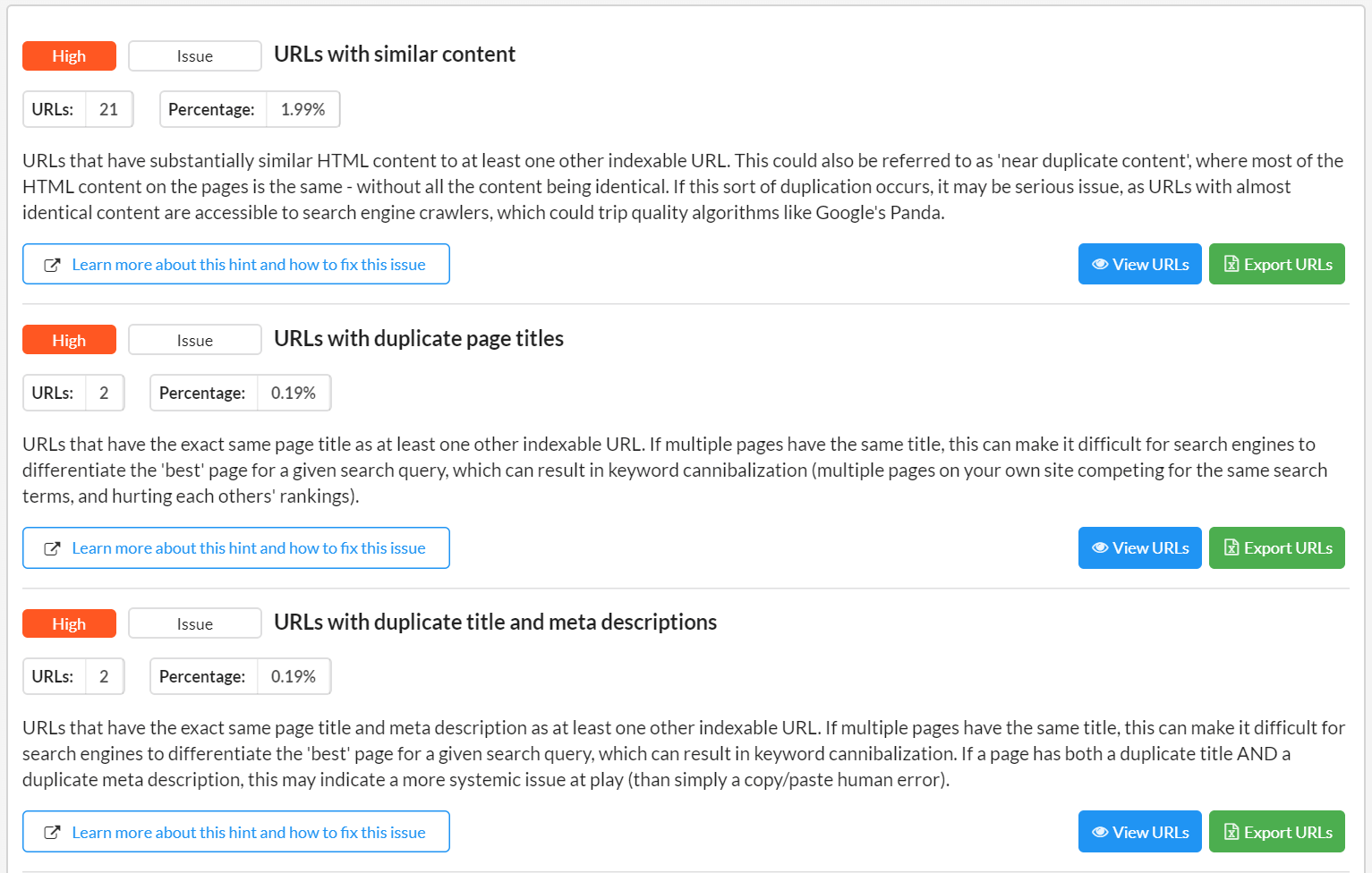 Źródło: Sitebulb.com
Źródło: Sitebulb.com
Dzięki crawlerom możliwe jest zebranie pełnej informacji o strukturze i zawartości witryny. Narzędzia te są nieocenioną pomocą podczas wykonywania audytu stron internetowych – również pod kątem duplicate contentu. Wśród najczęściej wykorzystywanych crawlerów wymienia się m.in.:
- ScreamingFrog,
- Sitebulb,
- NetPeak,
- Siteliner,
- DeepCrawl.
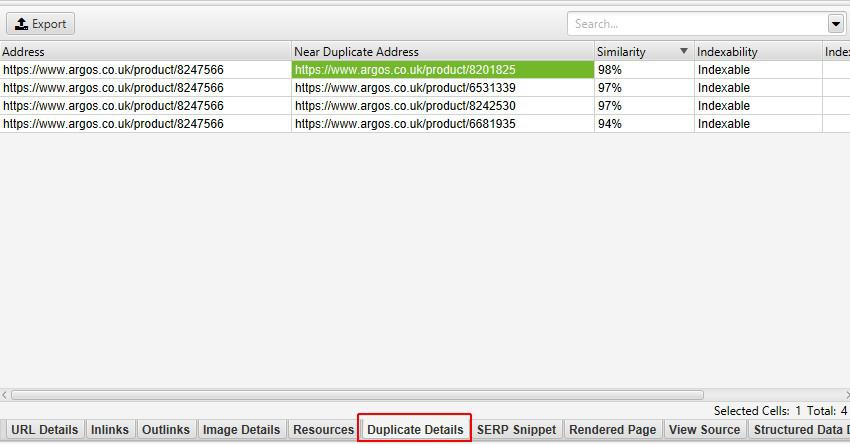 Źródło: Screamingfrog.co.uk
Źródło: Screamingfrog.co.uk
Każdy ze wskazanych crawlerów pozwala relatywnie łatwo odnaleźć adresy URL ze zduplikowaną treścią.
Google Search Console
W narzędziu Google Search Console łatwo sprawdzisz, czy witryna nie ma zduplikowanej treści. Żeby zweryfikować duplikację contentu, wejdź do zakładki „Stan” i następnie sprawdź komunikaty w kategoriach: „Błąd”, „Prawidłowe z ostrzeżeniem”.
Można też wejść do zakładki „skuteczność” i tam sprawdzić, czy nie następuje duplikacja adresów URL. Przykładowo pozornie dwa różne URL’e, ale jeden z http a drugi z https.
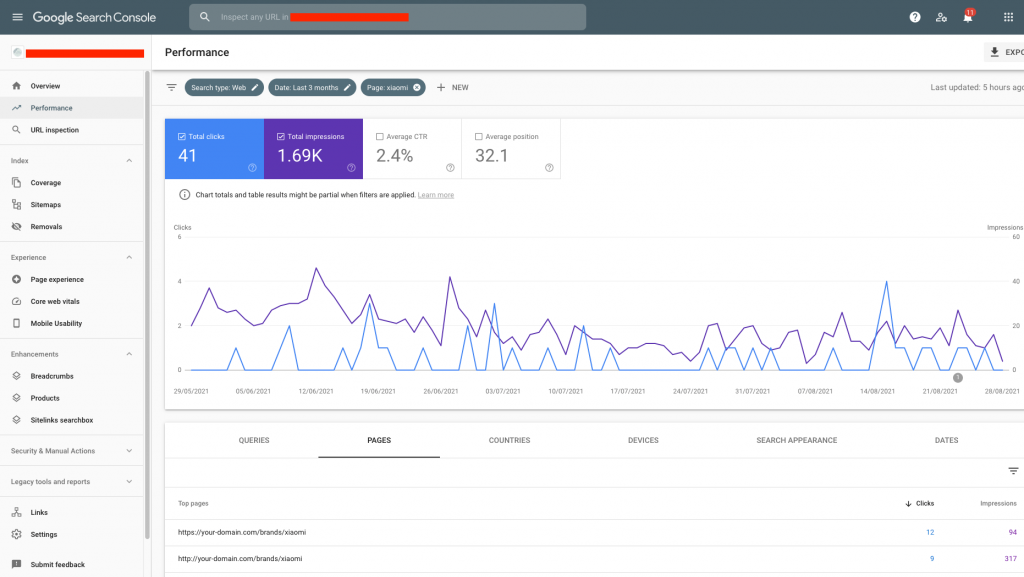
Wprowadzanie fragmentów treści w wyszukiwarce
W wyszukiwarkę możesz wprowadzić również fragmenty zduplikowanej treści. Rozwiązanie to może okazać się on dobrym sposobem na sprawdzenie kluczowych podstron witryny – np. zakładek ofertowych czy treści blogowych.
Jak sprawdzić, czy nie duplikujesz treści z internetu?
 Źródło: Copywritely.com
Źródło: Copywritely.com
Żeby sprawdzić, czy nie duplikujesz treści z internetu, możesz posłużyć się jednym z kilku dostępnych narzędzi. Wśród najczęściej wykorzystywanych należy wymienić Copyscape, Copywritely, Siteliner oraz Plagiarismę. Wystarczy, że wkleisz fragment treści lub URL, a wybrane narzędzie wyszuka treść w sieci.
 Źródło: Plagiarisma.net
Źródło: Plagiarisma.net
Alternatywnie możesz też wkleić fragment tekstu bezpośrednio do wyszukiwarki i sprawdzić, jakie Google zwraca wyniki.
Jak naprawić problem zduplikowanych treści?
Problem zduplikowanych treści można naprawić na kilka sposobów. Jednym z nich jest wykonywanie przekierowań 301 ze zduplikowanych podstron na właściwe adresy URL. Dzięki takiemu rozwiązaniu możliwe jest zachowanie mocy zduplikowanych podstron, ponieważ duplikat nie zostaje usunięty. Jednocześnie przekierowania 301 są łatwe do wykonania.
Innym rozwiązaniem jest wdrożenie tagu rel=„noindex”, a tym samym zablokowanie podstrony przed jej indeksacją w Google. Pamiętaj jednak, że stosując tag „noindex”, obniżysz potencjał widoczności witryny.
Trzecim sposobem jest zastosowanie metatagu rel=„canonical”. Canonicale świetnie sprawdzają się np. w przypadku publikacji dużej liczby podstron produktowych z identycznymi lub prawie takimi samymi opisami. Stosując kanoniczne adresy URL, wskażesz Google, który adres jest najbardziej reprezentatywny spośród zbioru duplikatów podstron.
W przypadku duplikacji treści wynikającej ze wdrożenia różnych wersji językowych serwisu zdecydowanie warto zastosować tag „hreflang”. Dzięki temu wskażesz Google różnice między różnymi wersjami językowymi witryny.
Problem zduplikowanych treści można również rozwiązać poprzez stworzenie i opublikowanie unikalnego contentu na każdej zduplikowanej podstronie.
Podsumowanie
Duplikacja treści to istotny problem, który dotyczy zwłaszcza większych sklepów oraz serwisów. Warto regularnie weryfikować, czy nie doszło do duplikacji treści zewnętrznej i wewnętrznej oraz szybko podjąć odpowiednie działania mające na celu eliminację tego problemu. Duplikacja contentu może znacząco obniżyć widoczność strony w wynikach wyszukiwania, a tym samym doprowadzić do spadku ruchu organicznego.

Marcin Cichocki
Założyciel i CEO agencji contentowej Kuźnia Treści. Jego teksty trafiały między innymi na łamy: Newsweeka, Wyborczej, Forbesa, Business Insidera, Rzeczpospolitej i portalu Komputer Świat. Jest autorem książki „Zawód: copywriter. Zacznij zarabiać na pisaniu". Dzieli się swoją wiedzą z zakresu content marketingu na swoim kanale w serwisie YouTube oraz w Treściwym Podcaście.
Wszystkie artykuły →